Researchers from South Korea Propose VITS2: A Breakthrough in Single-Stage Text-to-Speech Models for Enhanced Naturalness and Efficiency
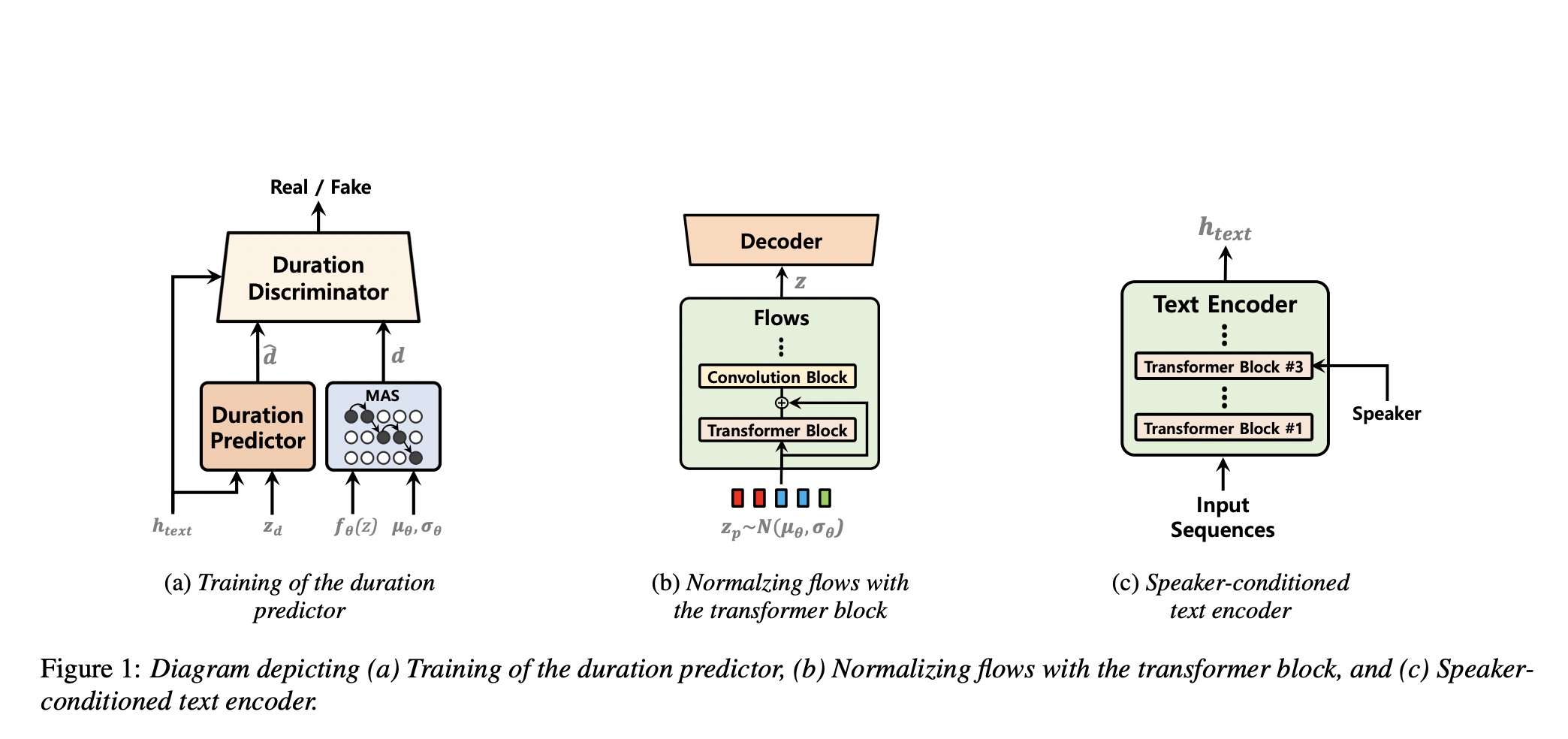
The paper introduces VITS2, a single-stage text-to-speech model that synthesizes more natural speech by improving various aspects of previous models. The model addresses issues like intermittent unnaturalness, computational efficiency, and dependence on phoneme conversion. The proposed methods enhance naturalness, speech characteristic similarity in multi-speaker models, and training and inference efficiency.
The strong dependence on phoneme conversion in previous works is significantly reduced, allowing for a fully end-to-end single-stage approach.
Previous Methods:
Two-Stage Pipeline Systems: These systems divided the process of generating waveforms from input texts into two cascaded stages. The first stage produced intermediate speech representations like mel-spectrograms or linguistic features from the input texts. The second stage then generated raw waveforms based on those intermediate representations. These systems had limitations such as error propagation from the first stage to the second, reliance on human-defined features like mel-spectrogram, and the computation required to generate intermediate features.
Single-Stage Models: Recent studies have actively explored single-stage models that directly generate waveforms from input texts. These models have not only outperformed the two-stage systems but also demonstrated the ability to generate high-quality speech nearly indistinguishable from human speech.
Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech by J. Kim, J. Kong, and J. Son was a significant prior work in the field of single-stage text-to-speech synthesis. This previous single-stage approach achieved great success but had several problems, including intermittent unnaturalness, low efficiency of the duration predictor, complex input format, insufficient speaker similarity in multi-speaker models, slow training, and strong dependence on phoneme conversion.
The current paper’s main contribution is to address the issues found in the previous single-stage model, particularly the one mentioned in the above successful model, and introduce improvements to achieve better quality and efficiency in text-to-speech synthesis.
Deep neural network-based text-to-speech has seen significant advancements. The challenge lies in converting discontinuous text into continuous waveforms, ensuring high-quality speech audio. Previous solutions divided the process into two stages: producing intermediate speech representations from texts and then generating raw waveforms based on those representations. Single-stage models have been actively studied and have outperformed two-stage systems. The paper aims to address issues found in previous single-stage models.
The paper describes improvements in four areas: duration prediction, augmented variational autoencoder with normalizing flows, alignment search, and speaker-conditioned text encoder. A stochastic duration predictor is proposed, trained through adversarial learning. The Monotonic Alignment Search (MAS) is used for alignment, with modifications for quality improvement. The model introduces a transformer block into the normalizing flows for capturing long-term dependencies. A speaker-conditioned text encoder is designed to better mimic the various speech characteristics of each speaker.
Experiments were conducted on the LJ Speech dataset and the VCTK dataset. The study used both phoneme sequences and normalized texts as model inputs. Networks were trained using the AdamW optimizer, and the training was conducted on NVIDIA V100 GPUs.Crowdsourced mean opinion score (MOS) tests were conducted to evaluate the naturalness of the synthesized speech. The proposed method showed significant improvement in the quality of synthesized speech compared to previous models. Ablation studies were conducted to verify the validity of the proposed methods.
Finally, the authors demonstrated the validity of their proposed methods through experiments, quality evaluation, and computation speed measurement but conveyed that various problems still exist in the field of speech synthesis that must be addressed, and hope that their work can be a basis for future research.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
I am Mahitha Sannala, a Computer Science Master’s student at the University of California, Riverside. I hold a Bachelor’s degree in Computer Science and Engineering from the Indian Institute of Technology, Palakkad. My main areas of interest lie in Artificial Intelligence and Machine learning. I am particularly passionate about working with medical data and to derive valuable insights from them . As a dedicated learner, I am eager to stay updated with the latest advancements in the fields of AI and ML.
Credit: Source link
Comments are closed.