Researchers from Stanford and AWS AI Labs Unveil S4: A Groundbreaking Approach to Pre-Training Vision-Language Models Using Web Screenshots
In the realm of artificial intelligence, bridging the gap between vision and language has been a formidable challenge. Yet, it harbors immense potential to revolutionize how machines understand and interact with the world. This article delves into the innovative research paper that introduces Strongly Supervised pre-training with ScreenShots (S4), a pioneering method poised to enhance Vision-Language Models (VLMs) by exploiting the vast and complex data available through web screenshots. S4 not only presents a fresh perspective on pre-training paradigms but also significantly boosts model performance across a spectrum of downstream tasks, marking a substantial step forward in the field.
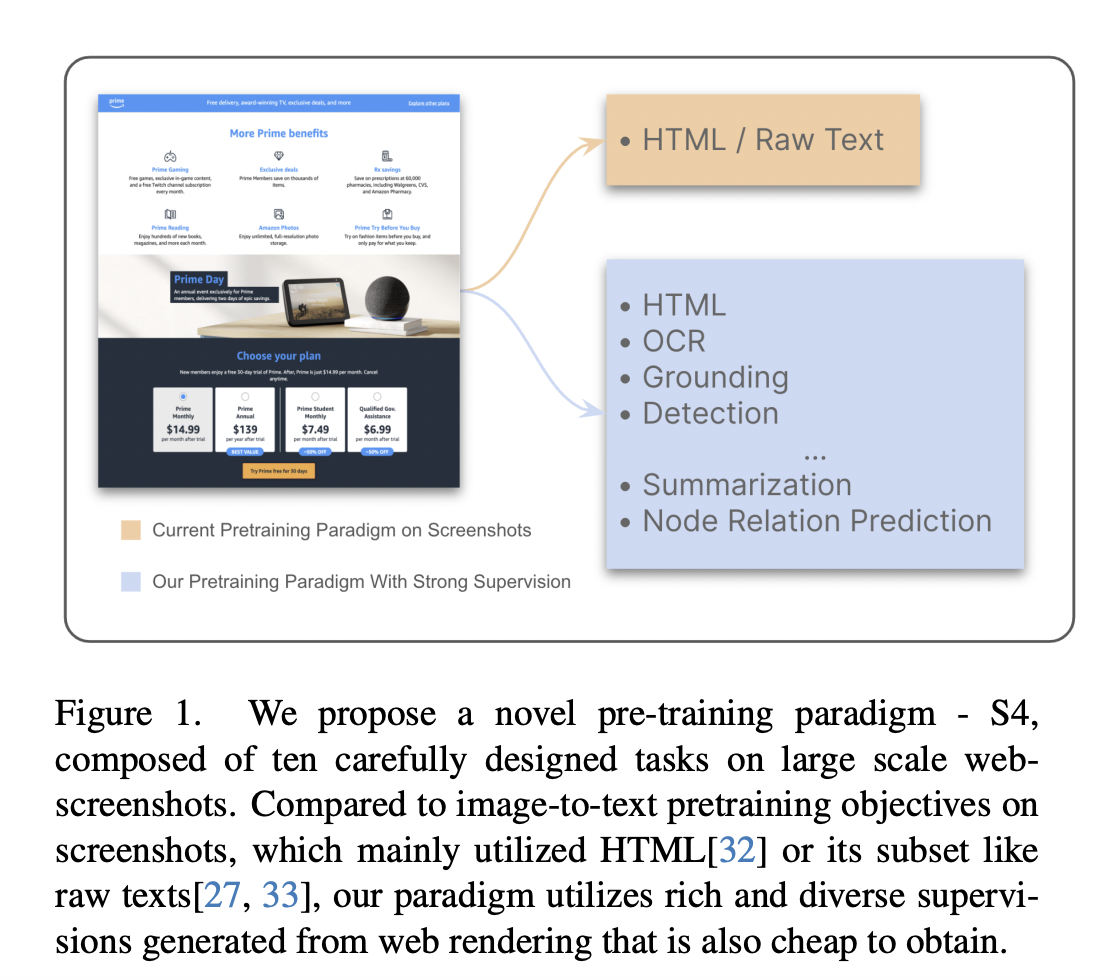
Traditionally, foundational models for language and vision tasks have heavily relied on extensive pre-training on large datasets to achieve generalization. For Vision-Language Models (VLMs), this involves training on image-text pairs to learn representations that can be fine-tuned for specific tasks. However, the heterogeneity of vision tasks and the scarcity of fine-grained, supervised datasets pose limitations. S4 addresses these challenges by leveraging web screenshots’ rich semantic and structural information. This method utilizes an array of pre-training tasks designed to closely mimic downstream applications, thus providing models with a deeper understanding of visual elements and their textual descriptions.

The essence of S4’s approach lies in its novel pre-training framework that systematically captures and utilizes the diverse supervisions embedded within web pages. By rendering web pages into screenshots, the method accesses the visual representation and the textual content, layout, and hierarchical structure of HTML elements. This comprehensive capture of web data enables the construction of ten specific pre-training tasks as illustrated in Figure 2, ranging from Optical Character Recognition (OCR) and Image Grounding to sophisticated Node Relation Prediction and Layout Analysis. Each task is crafted to reinforce the model’s ability to discern and interpret the intricate relationships between visual and textual cues, enhancing its performance on various VLM applications.

Empirical results (shown in Table 1) underscore the effectiveness of S4, showcasing remarkable improvements in model performance across nine varied and popular downstream tasks. Notably, the method achieved up to 76.1% improvement in Table Detection and consistent gains in Widget Captioning, Screen Summarization, and other tasks. This performance leap is attributed to the method’s strategic exploitation of screenshot data, which enriches the model’s training regimen with diverse and relevant visual-textual interactions. Furthermore, the research presents an in-depth analysis of the impact of each pre-training task, revealing how specific tasks contribute to the model’s overall prowess in understanding and generating language in the context of visual information.
In conclusion, S4 heralds a new era in vision-language pre-training by methodically harnessing the wealth of visual and textual data available through web screenshots. Its innovative approach advances the state-of-the-art in VLMs and opens up new avenues for research and application in multimodal AI. By closely aligning pre-training tasks with real-world scenarios, S4 ensures that models are not just trained but truly understand the nuanced interplay between vision and language, paving the way for more intelligent, versatile, and effective AI systems in the future.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 38k+ ML SubReddit
Want to get in front of 1.5 Million AI enthusiasts? Work with us here
![]()
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.
Credit: Source link
Comments are closed.