Researchers From Stanford And DeepMind Come Up With The Idea of Using Large Language Models LLMs as a Proxy Reward Function
With the development of computing and data, autonomous agents are gaining power. The need for humans to have some say over the policies learned by agents and to check that they align with their goals becomes all the more apparent in light of this.
Currently, users either 1) create reward functions for desired actions or 2) provide extensive labeled data. Both strategies present difficulties and are unlikely to be implemented in practice. Agents are vulnerable to reward hacking, making it challenging to design reward functions that strike a balance between competing goals. Yet, a reward function can be learned from annotated examples. However, enormous amounts of labeled data are needed to capture the subtleties of individual users’ tastes and objectives, which has proven expensive. Furthermore, reward functions must be redesigned, or the dataset should be re-collected for a new user population with different goals.
New research by Stanford University and DeepMind aims to design a system that makes it simpler for users to share their preferences, with an interface that is more natural than writing a reward function and a cost-effective approach to define those preferences using only a few instances. Their work uses large language models (LLMs) that have been trained on massive amounts of text data from the internet and have proven adept at learning in context with no or very few training examples. According to the researchers, LLMs are excellent contextual learners because they have been trained on a large enough dataset to incorporate important commonsense priors about human behavior.
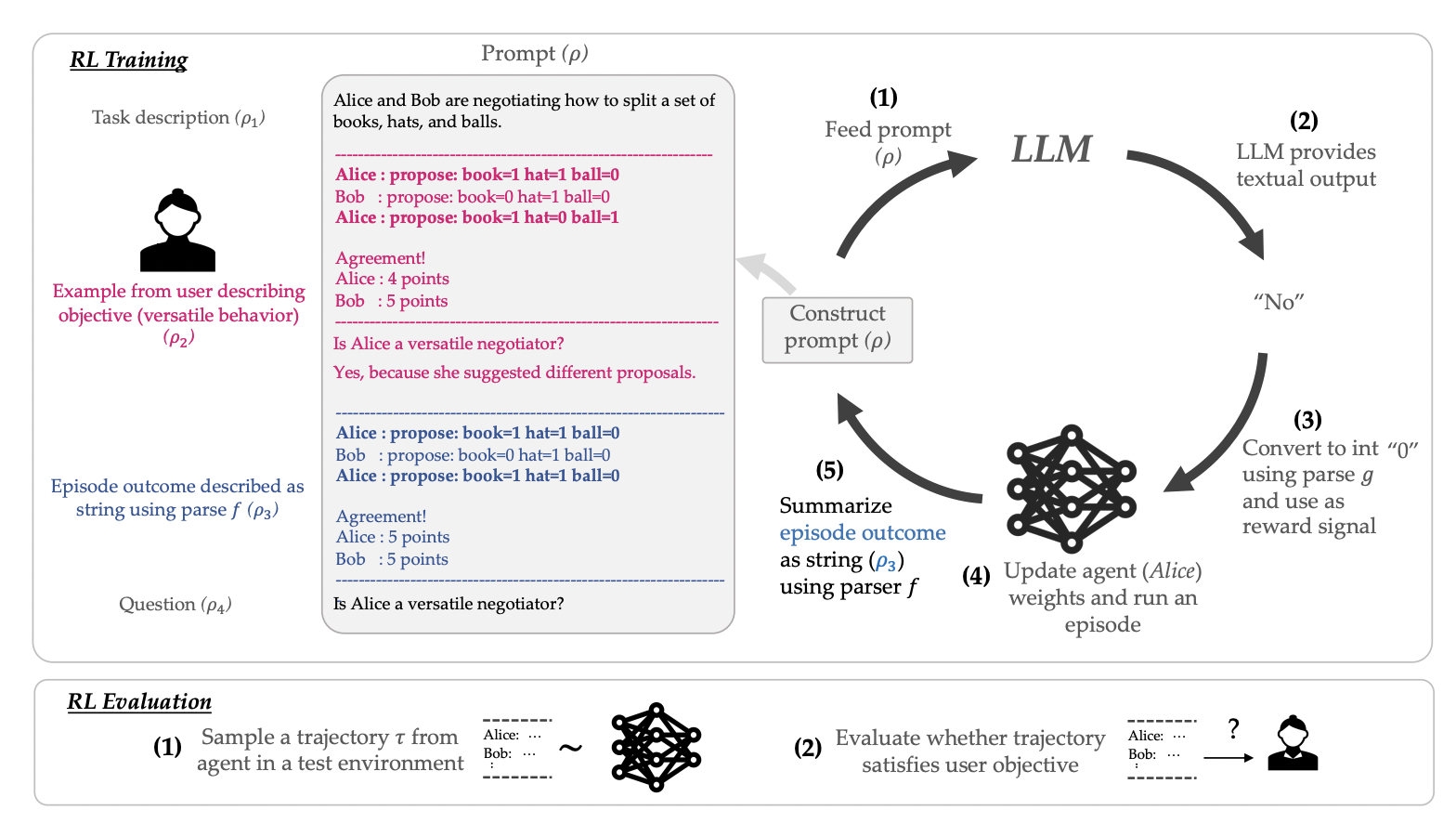
The researchers investigate how to employ a prompted LLM as a stand-in reward function for training RL agents using data provided by the end user. Using a conversational interface, the proposed method has the user define a goal. When defining an objective, one might use a few instances like “versatility” or one sentence if the topic is common knowledge. They define a reward function using the prompt and LLM to train an RL agent. An RL episode’s trajectory and the user’s prompt are fed into the LLM, and the score (e.g., “No” or “0”) for whether the trajectory satisfies the user’s aim is output as an integer reward for the RL agent. One benefit of using LLMs as a proxy reward function is that users can specify their preferences intuitively through language rather than having to provide dozens of examples of desirable behaviors.
Users report that the proposed agent is much more in line with their goal than an agent trained with a different goal. By utilizing its prior knowledge of common goals, the LLM increases the proportion of objective-aligned reward signals generated in response to zero-shot prompting by an average of 48% for a regular ordering of matrix game outcomes and by 36% for a scrambled order. In the Ultimatum Game, the DEALORNODEAL negotiation task, and the MatrixGames, the team only use several prompts to guide players through the process. Ten actual people were used in the pilot study.
An LLM can recognize common goals and send reinforcement signals that align with those goals, even in a one-shot situation. So, RL agents aligned with their objectives can be trained using LLMs that only detect one of two correct outcomes. The resulting RL agents are more likely to be accurate than those trained using labels because they just need to learn a single right outcome.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.