Researchers From Stanford Introduce Voltron: A Framework For Language-Driven Representation Learning From Human Videos Associated Captions
With the growing popularity and advancements in Artificial Intelligence, AI has successfully stepped into the field of Robotics. Robotics is a branch of engineering in which machines are developed and programmed to perform tasks without human involvement. A number of AI technologies are being used in robotics, such as using Natural Language Processing (NLP) to give voice commands to a robot, edge computing for better data management, and improved security practices in robotics, etc. Developing generalizable perceptions and good communication systems for robots has always been the research topic. With the recent developments in robotics, several approaches to imbibing visual representations by robots have been introduced.
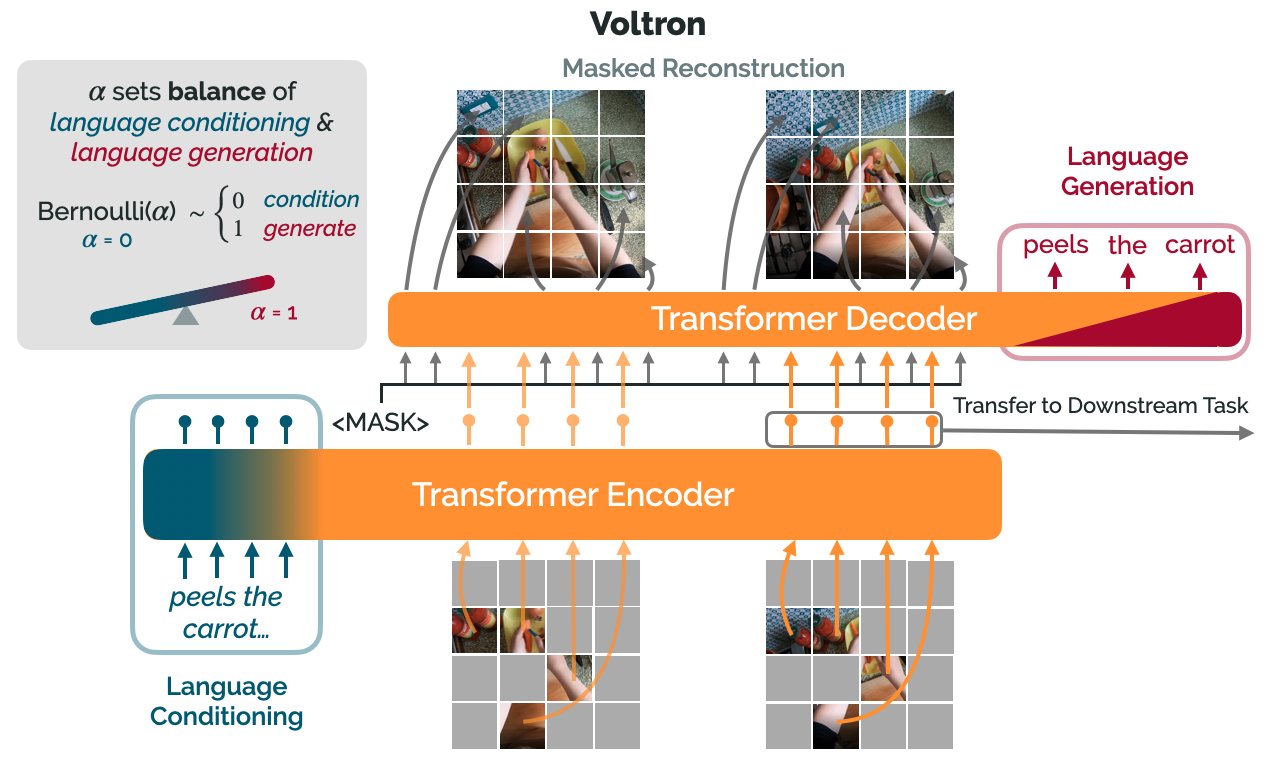
Recently, researchers from Stanford University have come up with a new framework called Voltron which is capable of learning representations driven by language and visuals. For a long time, many researchers have been trying to find out methods to make a robot learn from watching humans in a video. Some of the already used methods are masked autoencoding and contrastive learning. Apart from possessing the ability to control their actions, robots also need to have the potential to understand the way humans do and communicate effectively. Combining visual and language information is necessary for making a robot understand human intent from a video. Voltron allows the understanding of minute details from a video. It focuses on low-level visual reasoning as well as the high-level semantic understanding in robotics of whatever actions are taking place in a video.
Voltron works by taking related language texts as input from the videos. It uses a masked autoencoding pipeline and reconstructs frames from a masked context. Voltron makes use of language supervision to produce associated captions. This allows low-level pattern recognition at the spatial level and gives rise to high-level characteristics in terms of intent. Language supervision ensures improvised learning of visual representations for robotics. Videos, including humans performing everyday tasks, consisting of several resources, can act as datasets. These videos contain many natural language annotations useful in robotic manipulation and learning representations. Voltron does the same by improvising in representation learning using these large human video datasets.
Comparing Voltron to currently existing approaches, the team has shared that Voltron is far more consistent than the other two methods. Masked Autoencoding and Contrastive learning does not overcome the problems of grasp affordance prediction, language-conditioned imitation learning, and intent scoring for human-robot collaboration. According to the researchers, these methods show inconsistent results as masked autoencoding chooses low-level spatial characteristics at the cost of high-level semantics. On the other hand, Contrastive learning captures high-level semantics at the price of low-level attributes. The team has even introduced the Voltron Evaluation suite, which consists of evaluation problems spanning five applications: grasp affordance prediction, referring expression grounding, single-task visuomotor control, language-conditioned imitation learning on a real robot, and intent scoring. Voltron greatly outperforms prior approaches over all these applications.
Voltron is definitely a great addition to both robotics and Artificial Intelligence. It not just performs a single task but can be used for five downstream tasks. It is a breakthrough in visual representation learning for robotics and seems promising for future advancements.
Check out the Paper, Models, and Evaluation. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.