Researchers from Stanford, UC Berkeley, and Adobe Research have Developed a New AI Model that can Realistically Insert Specific Humans into Different Scenes
The creative industries have witnessed a new era of possibilities with the advent of generative models—computational tools capable of generating texts or images based on training data. Inspired by these advancements, researchers from Stanford University, UC Berkeley, and Adobe Research have introduced a novel model that can seamlessly insert specific humans into different scenes with impressive realism.
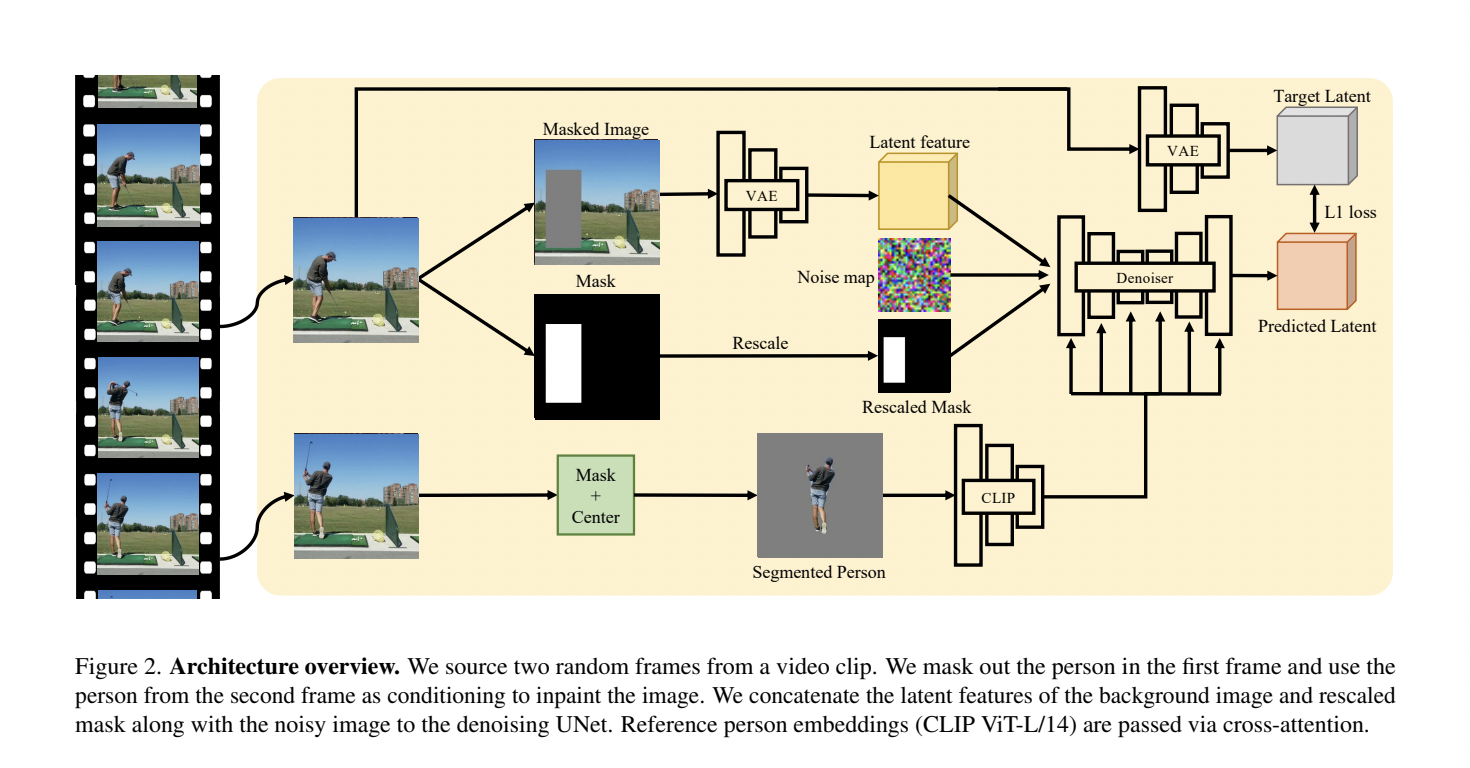
The researchers employed a self-supervised training approach to train a diffusion model. This generative model converts “noise” into desired images by adding and then reversing the process of “destroying” the training data. The model was trained on videos featuring humans moving within various scenes, selecting two frames randomly from each video. The humans in the first frame were masked, and the model used the unmasked individuals in the second frame as a conditioning signal to reconstruct the individuals in the masked frame realistically.
The model learned to infer potential poses from the scene context through this training process, re-pose the person, and seamlessly integrate them into the scene. The researchers found that their generative model performed exceptionally well in placing individuals in scenes, generating edited images that appeared highly realistic. The model’s predictions of affordances—perceived possibilities for actions or interactions within an environment—outperformed non-generative models previously introduced.
The findings hold significant potential for future research in affordance perception and related areas. They can contribute to advancements in robotics research by identifying potential interaction opportunities. Moreover, the model’s practical applications extend to creating realistic media, including images and videos. Integrating the model into creative software tools could enhance image editing functionalities, supporting artists and media creators. Furthermore, the model could be incorporated into photo editing smartphone applications, enabling users to easily and realistically insert individuals into their photographs.
The researchers have identified several avenues for future exploration. They aim to incorporate greater controllability into generated poses and explore the generation of realistic human movements within scenes rather than static images. Additionally, they seek to improve model efficiency and expand the approach beyond humans to encompass all objects.
In conclusion, the researchers’ introduction of a new model allows for the realistic insertion of humans into scenes. Leveraging generative models and self-supervised training, the model demonstrates impressive performance in affording perception and holds potential for various applications in the creative industries and robotics research. Future research will focus on refining and expanding the capabilities of the model.
Check Out The Paper. Don’t forget to join our 22k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club

Niharika is a Technical consulting intern at Marktechpost. She is a third year undergraduate, currently pursuing her B.Tech from Indian Institute of Technology(IIT), Kharagpur. She is a highly enthusiastic individual with a keen interest in Machine learning, Data science and AI and an avid reader of the latest developments in these fields.
Credit: Source link
Comments are closed.