Researchers from TH Nürnberg and Apple Enhance Virtual Assistant Interactions with Efficient Multimodal Learning Models
The realm of virtual assistants faces a fundamental challenge: how to make interactions with these assistants feel more natural and intuitive. Earlier, such exchanges required a specific trigger phrase or a button press to initiate a command, which can disrupt the conversational flow and user experience. The core issue lies in the assistant’s ability to discern when it is being addressed amidst various background noises and conversations. This problem extends to efficiently recognizing device-directed speech – where the user intends to communicate with the device – as opposed to a ‘non-directed’ address, which is not designed for the device.
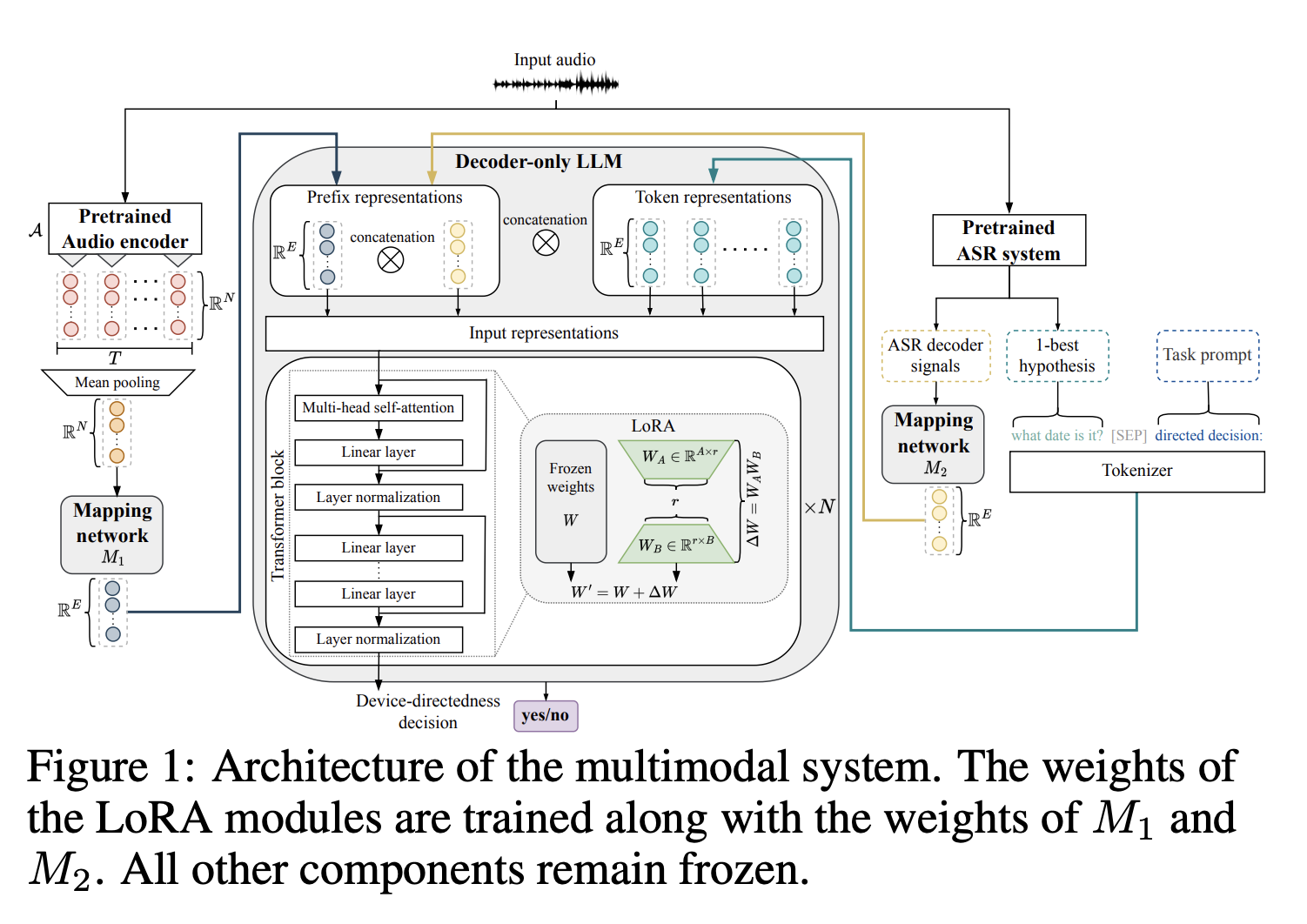
As stated, existing methods for virtual assistant interactions typically require a trigger phrase or button press before a command. This approach, while functional, disrupts the natural flow of conversation. In contrast, the research team from TH Nürnberg, Apple, proposes an approach to overcome this limitation. Their solution involves a multimodal model that leverages LLMs and combines decoder signals with audio and linguistic information. This approach efficiently differentiates directed and non-directed audio without relying on a trigger phrase.
The essence of this proposed solution is to facilitate a more seamless interaction between users and virtual assistants. The model is designed to interpret user commands more intuitively by integrating advanced speech detection techniques. This advancement represents a significant leap in the field of human-computer interaction, aiming to create a more natural and user-friendly experience using virtual assistants.
The proposed system utilizes acoustic features from a pre-trained audio encoder, combined with 1-best hypotheses and decoder signals from an automatic speech recognition system. These elements serve as input features for a large language model. The model is designed to be data and resource-efficient, requiring minimal training data and suitable for devices with limited resources. It operates effectively even with a single frozen LLM, showcasing its adaptability and efficiency in various device environments.

In terms of performance, the researchers demonstrate that this multimodal approach achieves lower equal-error rates compared to unimodal baselines while using significantly less training data. They found that specialized low-dimensional audio representations lead to better performance than high-dimensional general audio representations. These findings underscore the effectiveness of the model in accurately detecting user intent in a resource-efficient manner.
The research presents a significant advancement in virtual assistant technology by introducing a multimodal model that discerns user intent without the need for trigger phrases. This approach enhances the naturalness of human-device interaction and demonstrates efficiency in terms of data and resource usage. The successful implementation of this model could revolutionize how we interact with virtual assistants, making the experience more intuitive and seamless.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 34k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
Credit: Source link
Comments are closed.