Researchers From the University of Hamburg Propose A Machine Learning Model, Called ‘LipSound2’, That Directly Predicts Speech Representations From Raw Pixels

The purpose of the paper presented in this article is to reconstruct speech only based on sequences of images of talking people. The generation of speech from silent videos can be used for many applications: for instance, silent visual input methods used in public environments for privacy protection or understanding speech in surveillance videos.
The main challenge in speech reconstruction from visual information is that human speech is produced not only through observable mouth and face movements but also through lips, tongue, and internal organs like vocal cords. Furthermore, it is hard to visually distinguish phonemes like ‘v’ and ‘f’ only through mouth and face movements.
This paper leverages the natural co-occurrence of audio and video streams to pre-train a video-to-audio speech reconstruction model through self-supervision.
As shown in Figure 1a, at the beginning the LipSound2 model is pre-trained through self-supervised learning on an audio-visual dataset to map silent videos (i.e., sequences of face images) to mel-spectrogram without any human annotations. Hence, this pre-trained model is fine-tuned on other specific datasets. Finally, the existing network WaveGlow is used to generate the waveforms corresponding to the mel-spectrograms. In the second part of the framework (Figure 1b), the video-to-text process is performed by fine-tuning the generated audios (i.e., the waveforms) on Jasper, a pre-trained acoustic model.
Before seeing in detail the architecture of LipSound2, let’s talk about self-supervised learning. This learning approach relies on unlabeled data to learn meaningful features from data, through labels self-generated directly from data. A pretext task must be chosen to determine which are those self-generated labels. For instance, in computer vision, the pretext task could be predicting the angles of rotated images, or colorizing gray-scale images. In particular, this paper relies on cross-modality self-supervised learning, since, as we will see later, audio signals are used as the supervision of video inputs.
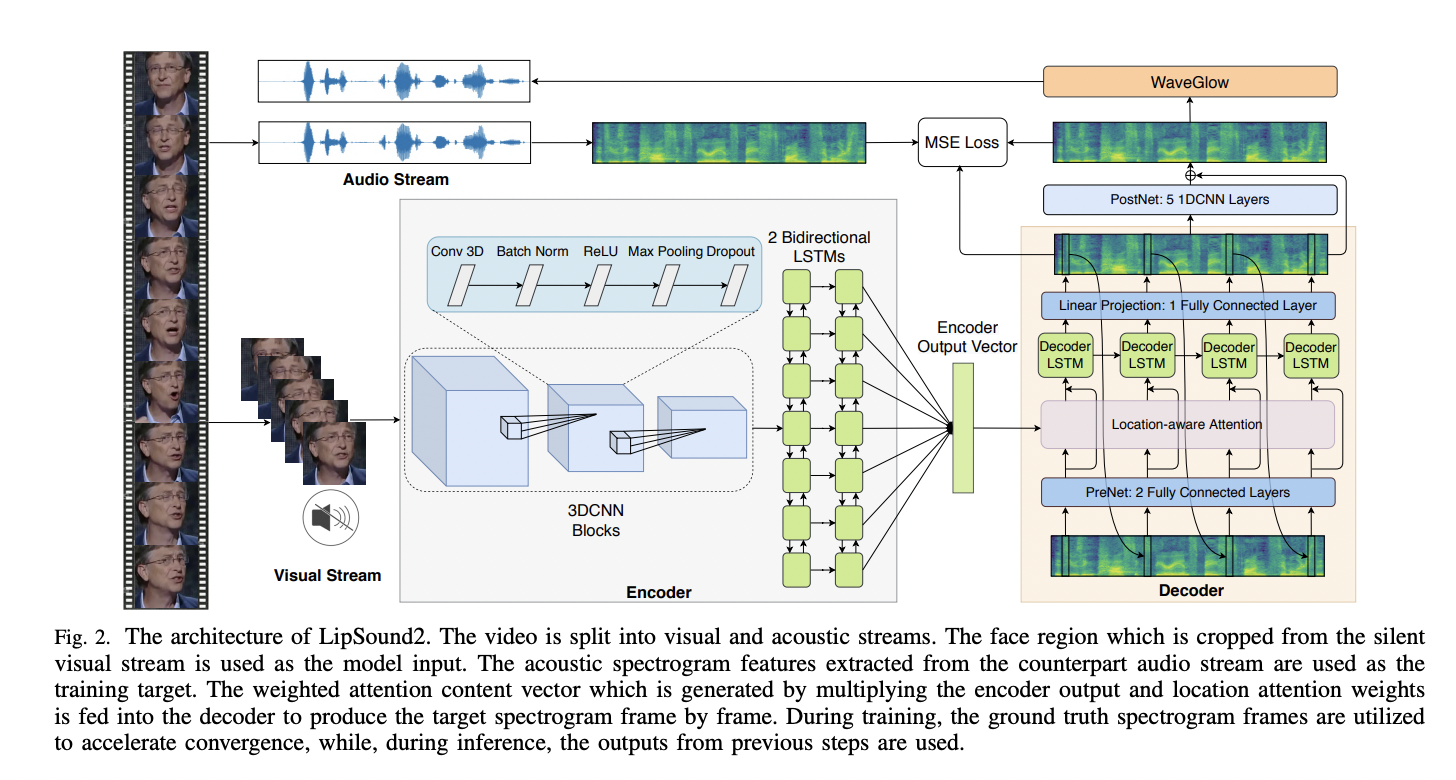
Figure 2 shows a detailed version of the LipSound2 model architecture. The dataset video clips are divided into an audio stream and a visual stream. The frames of the visual stream are pre-processed in order to give cropped face sequences as input to the model. Such sequences flow through the Encoder, which is composed of 3D CNN blocks, i.e., blocks that include a 3D Convolutional Neural Network layer, a Batch Normalization layer, a ReLU activation function, a Max Pooling layer, and a final Dropout layer. The Encoder Output Vector is then generated by two Bidirectional LSTM layers, which capture long-distance dependencies.
The Decoder involves a Location-aware Attention mechanism that uses attention weights from previous decoder timestamps as additional features. A single LSTM layer receives as input the weighted attention content vector which is generated by multiplying the encoder output and location attention weights. The output of the LSTM is given to a linear projection layer to produce the target spectrogram frame by frame. To guide the learning process through self-supervised learning, the original audio corresponding to the input face sequence is used as the training target. Furthermore, during the training process, ground truth spectrogram frames are used to accelerate the training process, while, during the inference step, the model uses the outputs from previous steps.
Since, at each time step, the Decoder receives only past information, 5 convolutional layers (i.e., Postnet) are added after the Decoder to further improve the model. The idea of the Postnet is to smooth the transition between adjacent frames and use future information that is not available while decoding. The loss function considered to train LipSound 2 is the sum of two Mean Square Errors (MSE): the MSE between the Decoder output and the target spectrogram and the MSE between the Postnet output and the target mel-spectrogram.
Finally, each mel-spectrogram is provided as input to WaveGlow to generate the original waveform, which is then used by the Jasper speech recognition system to generate text from the speech signals. The advantage of using mel-spectrograms during the learning process is reducing computational complexity and learning long-distance dependencies.
From the paper: LipSound2: Self-Supervised Pre-Training for Lip-to-Speech Reconstruction and Lip Reading
Link: https://arxiv.org/pdf/2112.04748.pdf
Suggested
Credit: Source link
Comments are closed.