Researchers from the University of Kentucky Propose MambaTab: A New Machine Learning Method based on Mamba for Handling Tabular Data
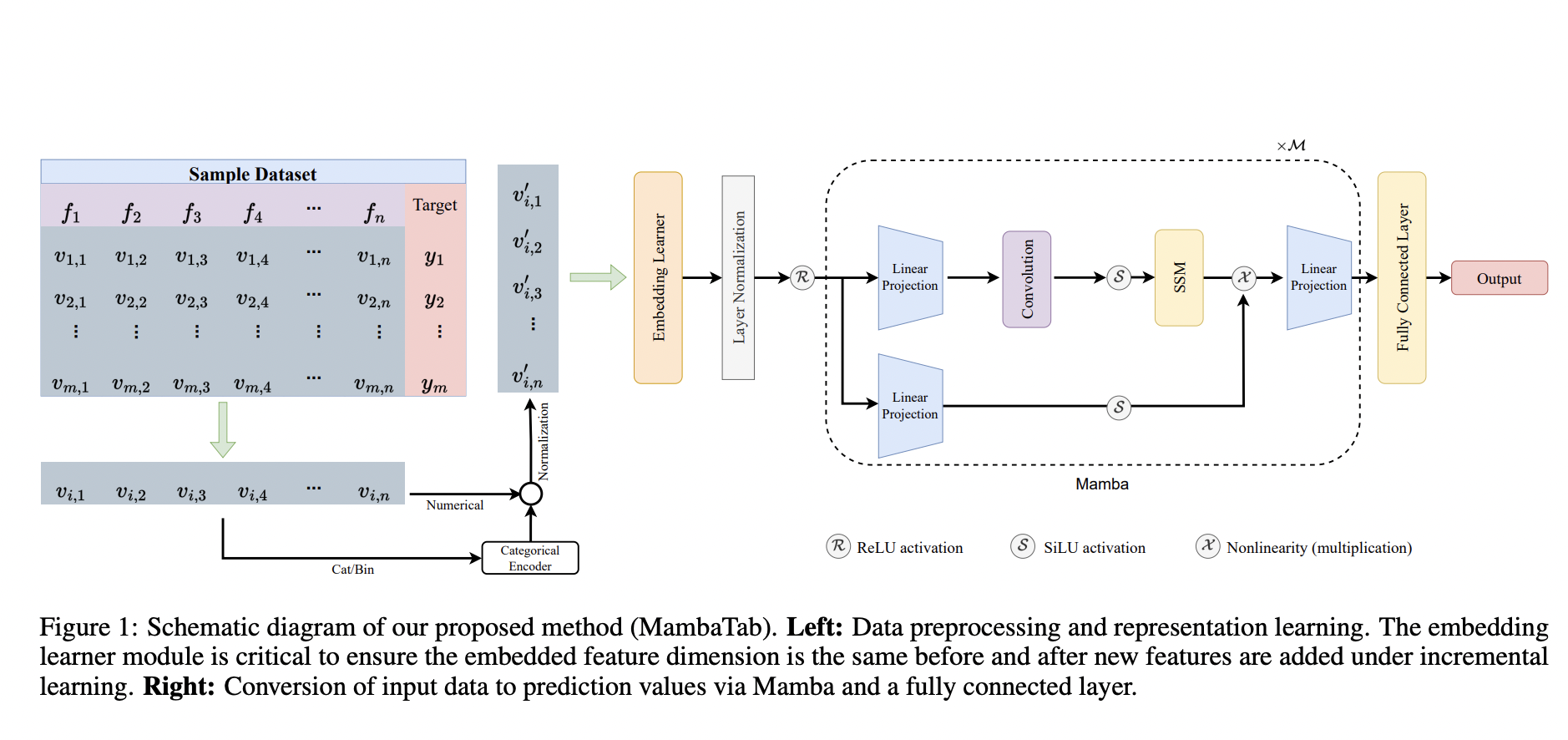
With its structured format, Tabular data dominates the data analysis landscape across various sectors such as industry, healthcare, and academia. Despite the surge in the use of images and texts for machine learning, tabular data’s inherent simplicity and interpretability have kept it at the forefront of analytical methods. However, while effective, the traditional and deep learning models currently employed to process this data type come with their own set of challenges. These include the need for extensive preprocessing, significant computational resources, and a high degree of model complexity, which can hinder their applicability and scalability.
To tackle these challenges, researchers from the University of Kentucky have developed MambaTab, an innovative approach leveraging a structured state-space model (SSM) specifically tailored for tabular data. This novel method introduces a streamlined, efficient pathway to handle tabular datasets without the burdensome requirements of its predecessors. The core innovation of MambaTab lies in its use of Mamba, an emerging SSM variant, which brings a lightweight yet potent solution to the table. Unlike conventional models that necessitate a hefty preprocessing workload and many parameters, MambaTab operates on a much leaner architecture. It reduces the need for manual data wrangling. It demonstrates an impressive capacity for feature incremental learning, where new features can be incorporated without discarding existing data or features.
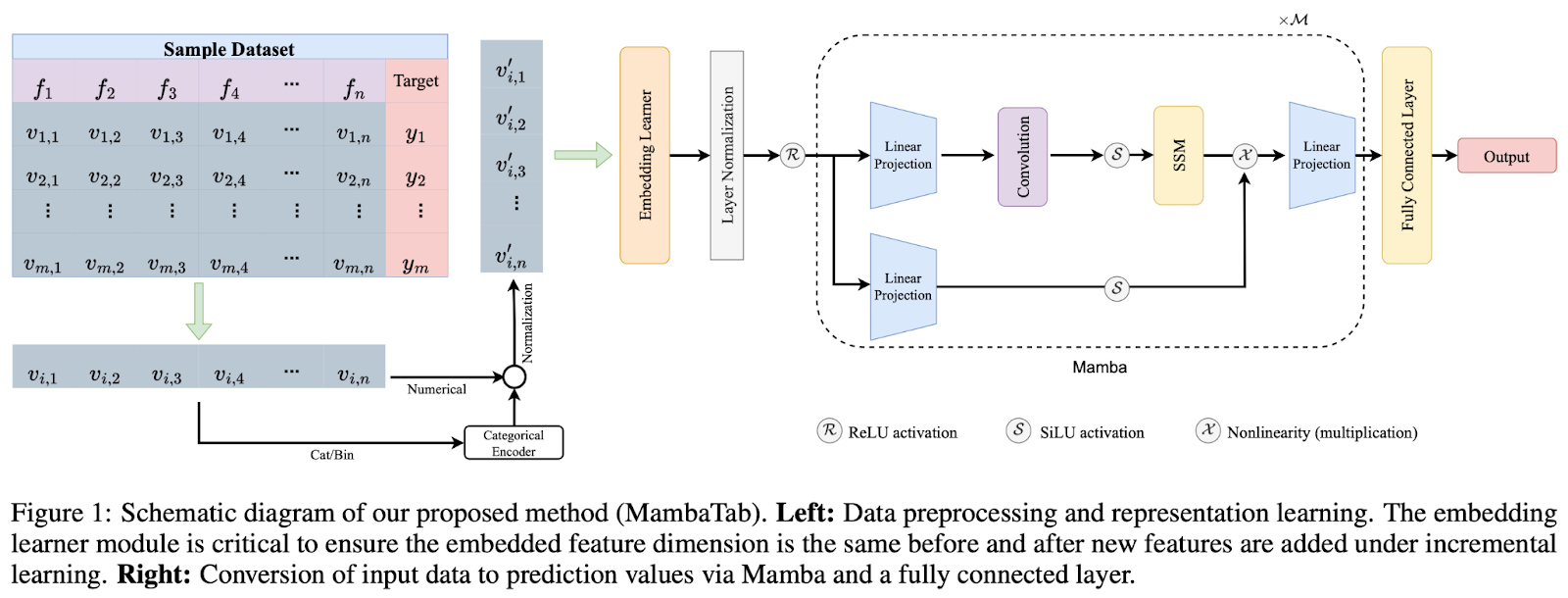
The technical underpinnings of MambaTab reveal a thoughtful design that balances efficiency with performance. By integrating the principles of both convolutional neural networks and recursive neural networks, MambaTab adeptly manages data with long-range dependencies—a frequent challenge in tabular datasets. This is achieved by carefully calibrating the model’s parameters, ensuring a linear scalability that is advantageous for datasets of varying sizes and complexities. Such architectural considerations allow MambaTab to maintain a high generalizability across different data domains, making it a versatile tool for various applications.
Empirical evidence underscores the efficacy of MambaTab. Rigorous testing on diverse benchmark datasets has shown that MambaTab not only outperforms existing state-of-the-art models in accuracy but does so with significantly fewer parameters. For instance, when evaluated under both vanilla supervised learning and feature incremental learning scenarios, MambaTab demonstrated superior performance across eight public datasets. Remarkably, it achieved these results while utilizing less than 1% of the parameters required by comparable transformer-based models, highlighting its exceptional efficiency and scalability.
The implications of MambaTab’s introduction are profound. By offering a method that simplifies the analytical process while delivering high-quality results, the research team has opened up new possibilities for data analysis. MambaTab’s efficiency and scalability make it an appealing option for researchers and practitioners, potentially democratizing access to advanced analytical techniques. Its ability to process tabular data with minimal preprocessing and reduced computational demand marks a significant step forward in the field, promising to enhance the breadth and depth of insights derived from tabular datasets.
In summary, MambaTab represents a pivotal advancement in the analysis of tabular data. Its innovative use of structured state-space models and its efficient and scalable architecture sets a new standard for data processing. As the research community continues to explore this method’s potential, MambaTab is poised to become a cornerstone tool in the arsenal of data scientists, offering a path to more accessible, efficient, and insightful data analysis.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
Credit: Source link
Comments are closed.