Researchers from the University of Massachusetts Lowell Propose ReLoRA: A New AI Method that Uses Low-Rank Updates for High-Rank Training
Over the past decade, training larger and more over parametrized networks, or the “stack more layers” strategy, has become the norm in machine learning. As the threshold for a “large network” has increased from 100 million to hundreds of billions of parameters, most research groups have found the computing expenses associated with training such networks too high to justify. Despite this, there is a lack of theoretical understanding of the need to train models that can have orders of magnitude more parameters than the training instances.
More compute-efficient scaling optima, retrieval-augmented models, and the straightforward strategy of training smaller models for longer have all provided new fascinating trade-offs as alternative approaches to scaling. However, they rarely democratize the training of these models and do not help us comprehend why over-parametrized models are necessary.
Overparametrization is also not required for training, according to many recent studies. Empirical evidence supports the Lottery Ticket Hypothesis, which states that, at some point in initialization (or early training), there are isolated sub-networks (winning tickets) that, when trained, achieve the whole network’s performance.
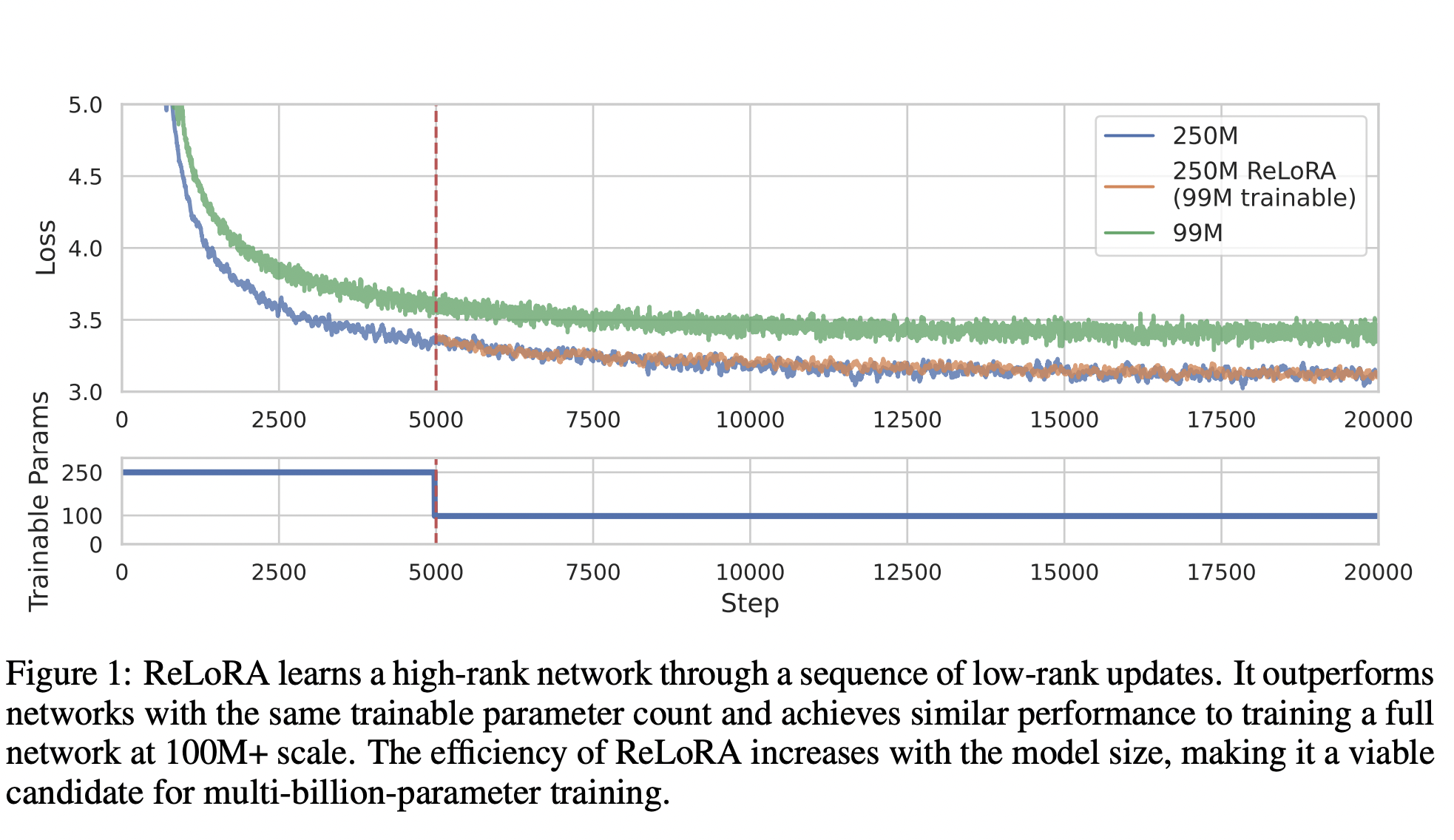
Recent research by the University of Massachusetts Lowell introduced ReLoRA to solve this problem by utilizing the rank of sum property to train a high-rank network with a series of low-rank updates. Their findings show that ReLoRA is capable of a high-rank update and delivers results comparable to standard neural network training. ReLoRA uses a full-rank training warm start similar to the lottery ticket hypothesis with rewinding. With the addition of a merge-and-rein-it (restart) approach, a jagged learning rate scheduler, and partial optimizer resets, the efficiency of ReLoRA is improved, and it is brought closer to full-rank training, especially in large networks.
They test ReLoRA with 350M-parameter transformer language models. While testing, they focused on autoregressive language modeling because it has proven applicable across a wide range of neural network uses. The results showed that ReLoRA’s effectiveness grows with model size, suggesting that it could be a good choice for training networks with many billions of parameters.
When it comes to training big language models and neural networks, the researchers feel that developing low-rank training approaches offers significant promise for boosting training efficiency. They believe that the community can learn more about how neural networks can be trained via gradient descent and their remarkable generalization skills in the over-parametrized domain from low-rank training, which has the potential to contribute significantly to the development of deep learning theories.
Check out the Paper and GitHub link. Don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 800+ AI Tools in AI Tools Club
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.