Researchers From the University of Sydney and Adobe Propose P3M-Net: A Portrait Matting Model with Privacy Preserving
This research summary is based on the paper 'Rethinking Portrait Matting with Privacy Preserving' Please don't forget to join our ML Subreddit
Deep learning’s effectiveness in many computer vision and multimedia applications is primarily dependent on vast amounts of training data. However, privacy concerns concerning individually identifiable information in datasets, such as face, gait, and voice, have lately gained traction for particular activities such as face recognition, human activity analysis, and portrait animation.
Unfortunately, addressing data privacy issues without compromising performance remains difficult and under-explored. Portrait matting, which involves predicting accurate foregrounds from portrait photographs, is particularly vulnerable to privacy concerns, as most of the images in earlier matting datasets feature identifiable faces.
Because portrait matting is a crucial approach in this multimedia application for changing virtual background, this issue has gotten more and more attention in the post-COVID-19 pandemic age, as the population of virtual video meetings has grown. According to studies, all previous portrait matting approaches paid less attention to the privacy issue and used intact identifiable portrait photos for both training and evaluation, leaving privacy-preserving portrait matting (P3M) as an unsolved challenge.
Researchers at Adobe recently published a work in which they set up a new task P3M that requires training solely on face-blurred portrait photographs (i.e., the Privacy-Preserving Training (PPT) setting) while testing on arbitrary images. They present the P3M-10k anonymized portrait matting benchmark, which consists of 10,000 high-resolution face-blurred portrait images carefully collected and filtered from a large number of images with diverse foregrounds, backgrounds, and postures, as well as the carefully labeled high-quality ground truth alpha mattes.

In terms of diversity, volume, and quality, it outperforms previous matting datasets. Furthermore, researchers chose face obfuscation as a privacy-protection technology because it removes identifiable face information while preserving small details like hairs. The team separates 500 photos from P3M-10k to create P3M-500-P, a face blurred validation set.
Furthermore, to test the generalization ability of matting models trained on privacy-preserved photos on non-privacy images, researchers created P3M-500-NP, a validation set of 500 images with no privacy issues. P3M-500-NP contains only frontal photographs of celebrities or profile/back images without any identifiable faces.
Face obfuscation introduces visible artifacts to the photos that aren’t present in typical portraits. Then there’s the matter of how existing SOTA matting models will be affected by the planned PPT (Privacy-Preserving Training (PPT)) setting. The researchers discovered that a recent study found actual evidence that face obfuscation has just a minimal impact on object detection and recognition models. In the case of portrait matting, where the pixel-wise alpha matte (a soft mask) with fine details is expected to be calculated from a high-resolution portrait image, the impact is uncertain.



They extensively investigated both trimap-based, and trimap-free matting approaches on P3M-10k to address the above problem and present insights and analyses. Researchers discovered that for trimap-based matting, where the trimap is employed as an auxiliary input, face obfuscation has less impact on the matting models, resulting in a minor performance change following the PPT setting.
When it comes to trimap-free matting, which has two sub-tasks: foreground segmentation and detail matting, researchers discovered that methods that use a multi-task framework to explicitly model and jointly optimize both tasks could achieve good generalization on both face blurred and non-privacy images at the same time. Under the PPT configuration, however, matting approaches that tackle the problem in a ‘segmentation followed by matting’ manner exhibit a considerable performance reduction.
The fundamental reason for this is that face obfuscation-induced segmentation mistakes might compound the fault of the next matting model. Other solutions, such as using multiple stages of networks to refine alpha mattes from coarse to fine, appear to be less influenced by face obfuscation but still suffer from a performance hit due to the lack of explicit semantic guidance. In the meantime, these methods necessitate a time-consuming training process.
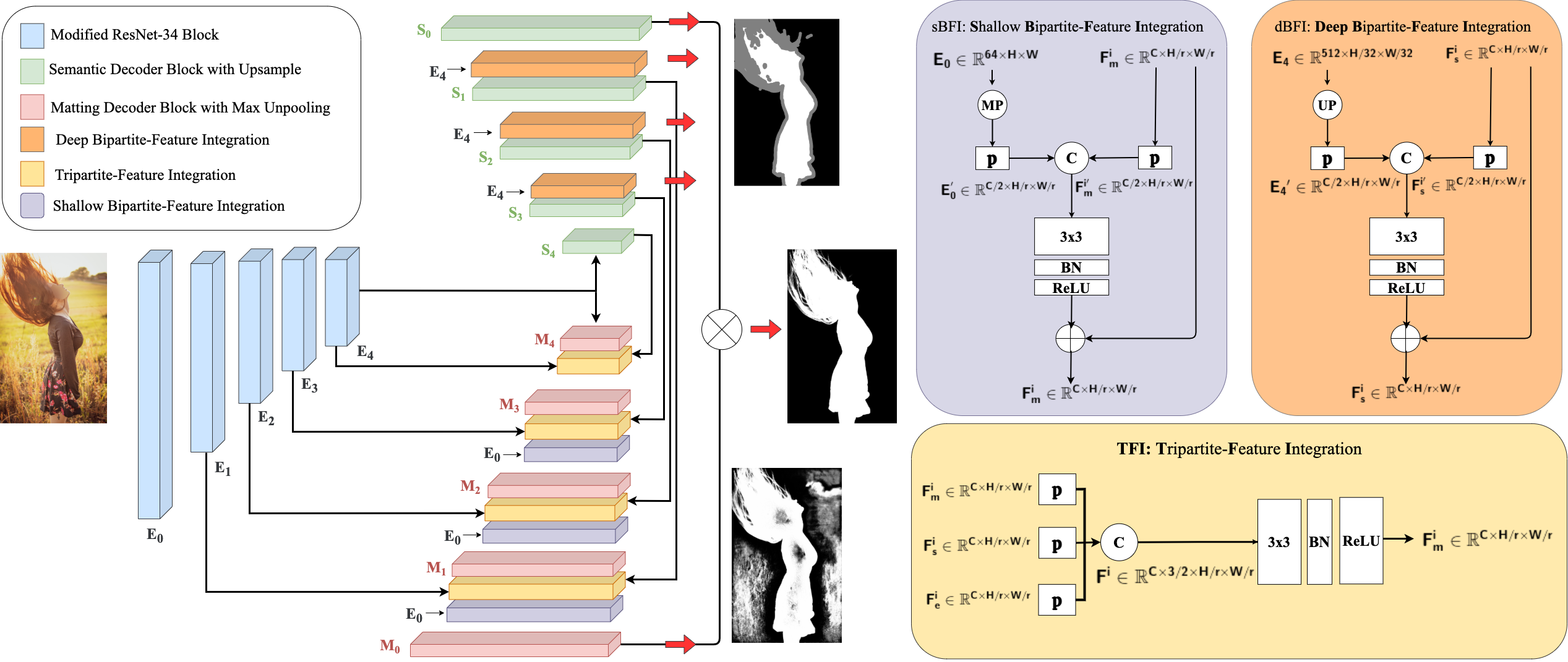
Based on the findings, the team offers P3M-Net, a novel automatic portrait matting model that can serve as a powerful trimap-free matting baseline for the P3M challenge. Technically, they use the basic structure of the multi-task framework introduced in, which learns common visual characteristics via a sharing encoder and task-aware features via a segmentation decoder and a matting decoder.
They created a deep Bipartite-Feature Integration (dBFI) module to improve the network’s robustness to privacy-preserving training data by leveraging deep features with high-level semantics, a Shallow Bipartite-Feature Integration (sBFI) module to improve the network’s ability to extract fine details in portrait images by extracting shallow features in the matting decoder, and a Tripartite-Feature Integration (TFI) module to improve the network’s ability to obtain fine.
The researchers then create numerous P3MNet variations based on both CNN and vision transformer backbones and compare their generalization abilities. Extensive tests on the P3M-10k benchmark provide significant empirical insights into the generalization capacities of various matting models in the PPT scenario and show that P3M-Net and its variations surpass all previous trimap-free matting approaches by a large margin.
Although the P3M-Net model outperforms earlier techniques, there is still a performance disparity between face-blurred and normal non-privacy portrait photos, particularly in the face regions. The question of how to narrow the performance difference by compensating for the lack of facial characteristics in face-blurred training data remains unanswered.
To address this issue, they developed a simple but successful Copy and Paste technique (P3M-CP) that can borrow facial information from publicly available celebrity photographs without compromising privacy and lead the network to re-acquire the face context at both the data and feature levels. P3M-CP simply adds a few extra computations during training, but it allows the matting model to analyze both face blurred and non-privacy images without much effort during inference.
The team is working on P3M-Net ablation research using the P3M-500-P and P3M-500-NP validation sets. In comparison to earlier methods, the simple multi-task baseline without any of the proposed modules can yield a fairly decent outcome. Because of the valuable semantic data from the encoder and segmentation decoder for matting, SAD drops dramatically to 11.32 and 13.7 with TFI. Furthermore, on the P3M-500-P, sBFI (dBFI) reduces SAD from 11.32 to 9.47 (9.76) and on the P3M-500-NP, from 13.7 to 12.36 (12.45), showing their usefulness in delivering meaningful guidance from important visual cues. The SAD reduces from 15.13 to 8.73 and 17.01 to 11.23 with all three modules, suggesting that the proposed modules increase relative performance by roughly 50%.
Conclusion: Adobe researchers conduct the first study on the privacy-preserving portrait matting (P3M) challenge in response to growing privacy concerns in this publication. They build the first large-scale anonymized portrait dataset, P3M-10k, which contains 10,000 face-blurred photos and ground truth alpha mattes, and describe the privacy-preserving training (PPT) setup. The PPT setting has no effect on trimap-based approaches, while trimap-free methods perform differently depending on their model structures, according to the researchers. The researchers anticipate that this study will provide a new viewpoint on picture matting research and raise community awareness of privacy problems.
Paper: https://arxiv.org/pdf/2203.16828v1.pdf
Github: https://github.com/vitae-transformer/vitae-transformer-matting
Suggested
Credit: Source link
Comments are closed.