Researchers from the University of Toronto Unveil a Surprising Redundancy in Large Materials Datasets and the Power of Informative Data for Enhanced Machine Learning Performance
With the advent of AI, its use is being felt in all spheres of our lives. AI is finding its application in all walks of life. But AI needs data for the training. AI’s effectiveness relies heavily on data availability for training purposes.
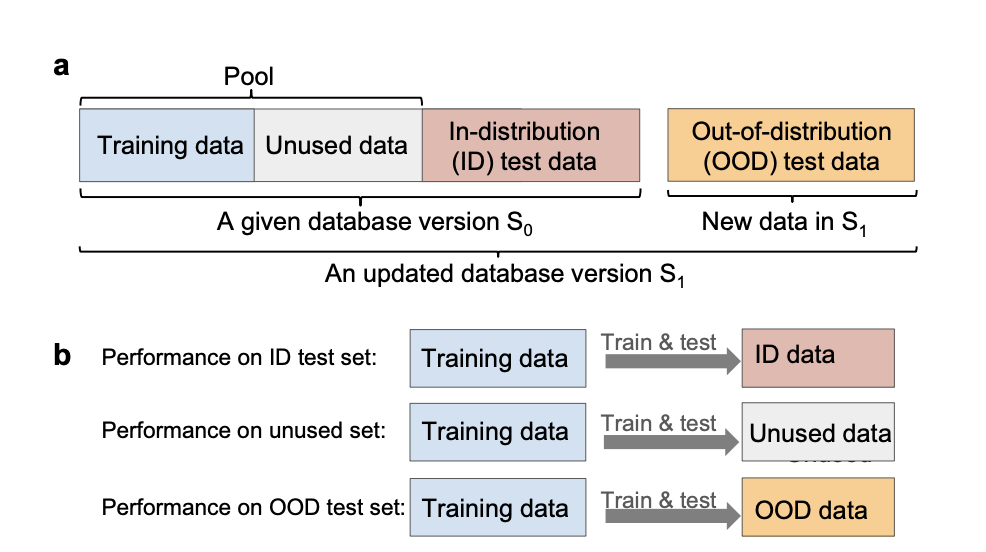
Conventionally, achieving accuracy in training AI models has been linked to the availability of substantial amounts of data. Addressing this challenge in this field involves navigating an extensive potential search space. For example, The Open Catalyst Project, uses more than 200 million data points related to potential catalyst materials.
The computation resources required for analysis and model development on such datasets are a big problem. Open Catalyst datasets used 16,000 GPU days for analyzing and developing models. Such training budgets are only available to some researchers, often limiting model development to smaller datasets or a portion of the available data. Consequently, model development is frequently restricted to smaller datasets or a fraction of the available data.
A study by University of Toronto Engineering researchers, published in Nature Communications, suggests that the belief that deep learning models require a lot of training data may not be always true.
The researchers said that we need to find a way to identify smaller datasets that can be used to train models on. Dr. Kangming Li, a postdoctoral scholar at Hattrick-Simpers, used an example of a model that forecasts students’ final scores and emphasized that it performs best on the dataset of Canadian students on which it is trained, but it might not be able to predict grades for students from of other countries.
One possible solution is finding subsets of data inside incredibly huge datasets to address the issues raised. These subsets should contain all the diversity and information in the original dataset but be easier to handle during processing.
Li developed methods for locating high-quality subsets of information from materials datasets that have already been made public, such as JARVIS, The Materials Project, and Open Quantum Materials. The goal was to gain more insight into how dataset properties affect the models they train.
To create his computer program, he used the original dataset and a much smaller subset with 95% fewer data points. The model trained on 5% of the data performed comparably to the model trained on the entire dataset when predicting the properties of materials within the dataset’s domain. According to this, machine learning training can safely exclude up to 95% of the data with little to no effect on the accuracy of in-distribution predictions. The overrepresented material is the main subject of the redundant data.
According to Li, the study’s conclusions provide a way to gauge how redundant a dataset is. If adding more data doesn’t improve model performance, it is redundant and doesn’t provide the models with any new information to learn.
The study supports a growing body of knowledge among experts in AI across multiple domains: models trained on relatively small datasets can perform well, provided the data quality is high.
In conclusion, the significance of information richness is stressed more than the volume of data alone. The quality of the information should be prioritized over gathering enormous volumes of data.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Rachit Ranjan is a consulting intern at MarktechPost . He is currently pursuing his B.Tech from Indian Institute of Technology(IIT) Patna . He is actively shaping his career in the field of Artificial Intelligence and Data Science and is passionate and dedicated for exploring these fields.
Credit: Source link
Comments are closed.