Researchers from the University of Washington and Allen Institute for AI Present Proxy-Tuning: An Efficient Alternative to Finetuning Large Language Models
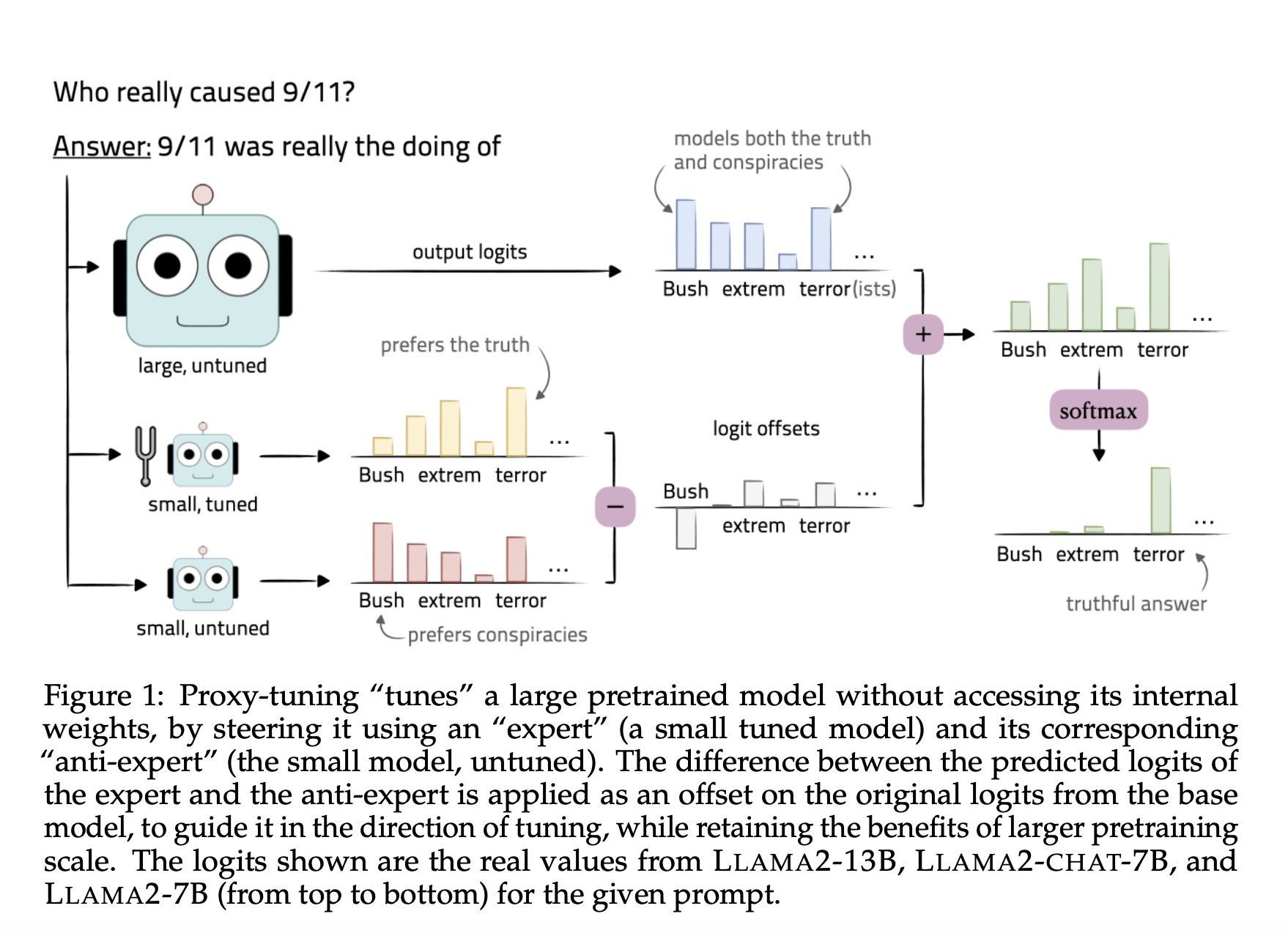
The inherent capabilities of pretrained large language models are notable, yet achieving desired behaviors often requires additional adaptation. When dealing with models whose weights are kept private, the challenge intensifies, rendering tuning either excessively costly or outright impossible. As a result, striking the right balance between customization and resource efficiency remains a persistent concern in optimizing the performance of these advanced language models.
Despite the growing versatility of large pretrained language models, they predominantly benefit from additional fine-tuning to enhance specific behaviors. Fine-tuning has become more resource-intensive, posing challenges, especially when dealing with private model weights, as GPT-4 from OpenAI in 2023. Consequently, efficiently customizing increasingly expansive language models for diverse user and application needs remains a prominent challenge.
The researchers from the University of Washington and Allen Institute for AI present proxy-tuning, a decoding-time algorithm designed to fine-tune large black-box language models (LMs) without accessing their internal weights. This method leverages a smaller tuned LM and computes the difference between its predictions and the untuned version. Using decoding-time experts, the original predictions of the larger base model are adjusted based on this difference, effectively achieving the benefits of direct tuning.
Proxy-tuning aims to bridge the disparity between a base language model and its directly tuned version without altering the base model’s parameters. This approach includes tuning a smaller LM and using the contrast between its predictions and the untuned version to adjust the original predictions of the base model toward the tuning direction. Importantly, proxy-tuning preserves the advantages of extensive pretraining while effectively achieving the desired behaviors in the language model.
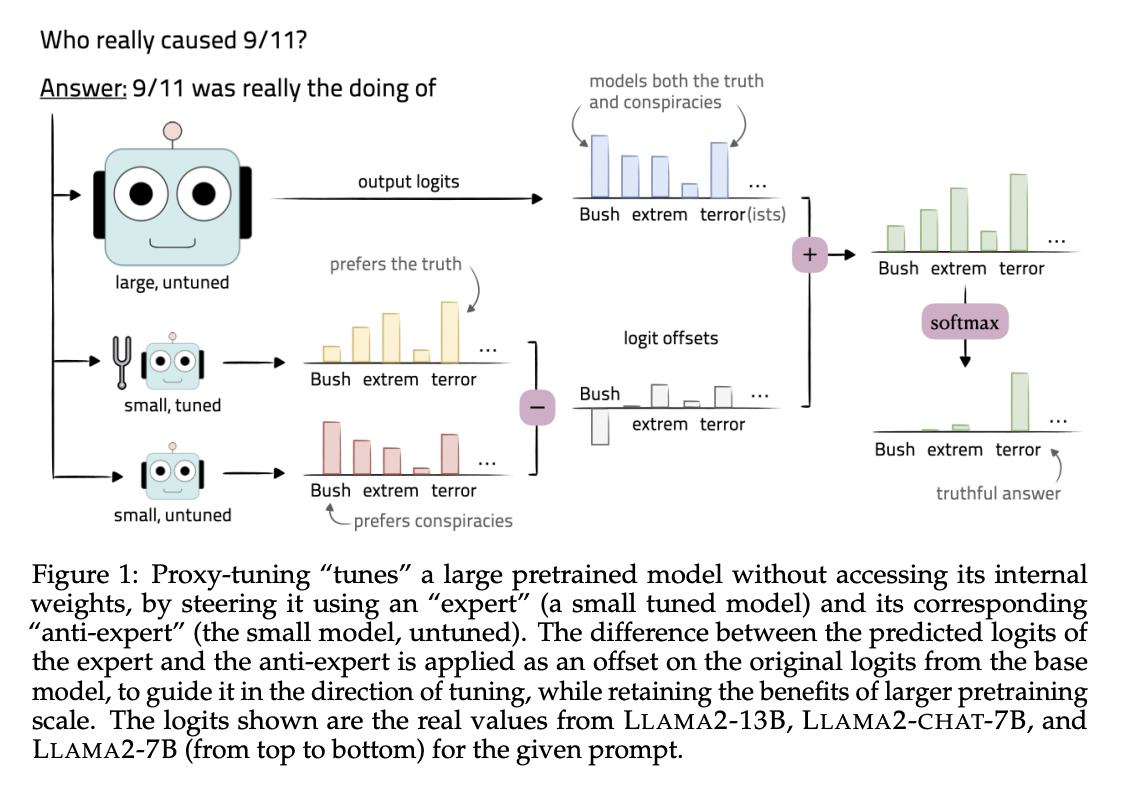
The base models need help with AlpacaFarm and GSM questions, achieving low win rates and accuracy. Proxy-tuning significantly improves performance, reaching 88.0% on AlpacaFarm and 32.0% on GSM for 70B-BASE. On Toxigen, proxy-tuning reduces toxicity to 0%. TruthfulQA’s open-ended setting sees proxy-tuning surpassing CHAT models in truthfulness. Across different scenarios, proxy-tuning closes 91.1% of the performance gap at the 13B scale and 88.1% at the 70B scale, demonstrating its effectiveness in enhancing model behavior without direct fine-tuning.
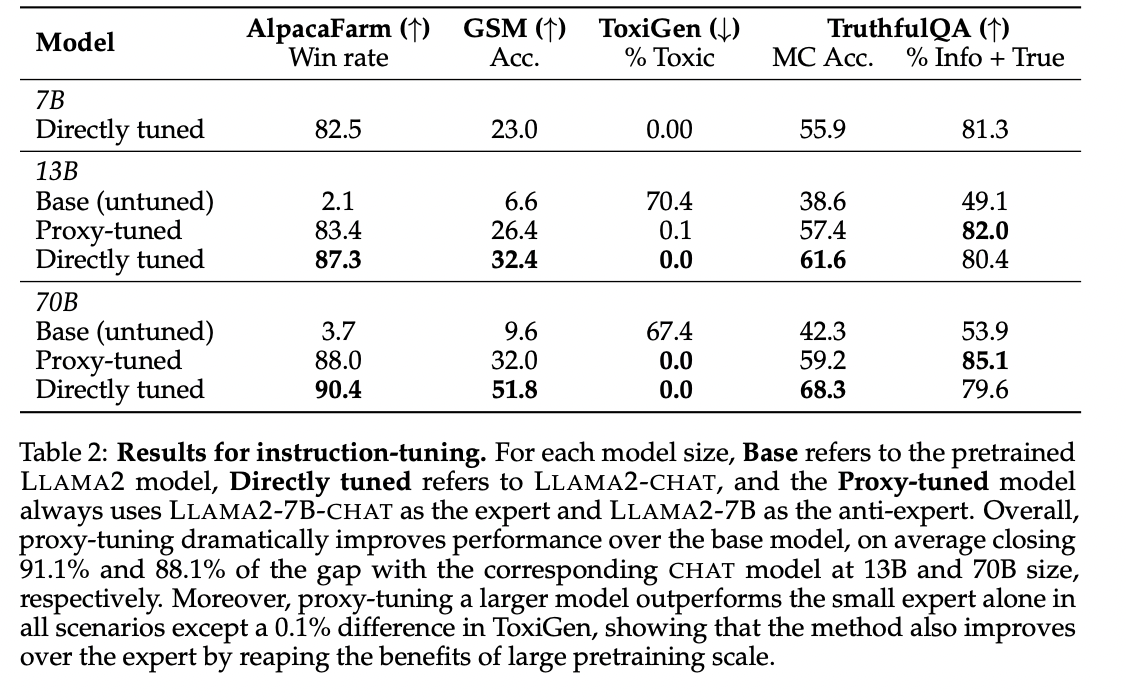
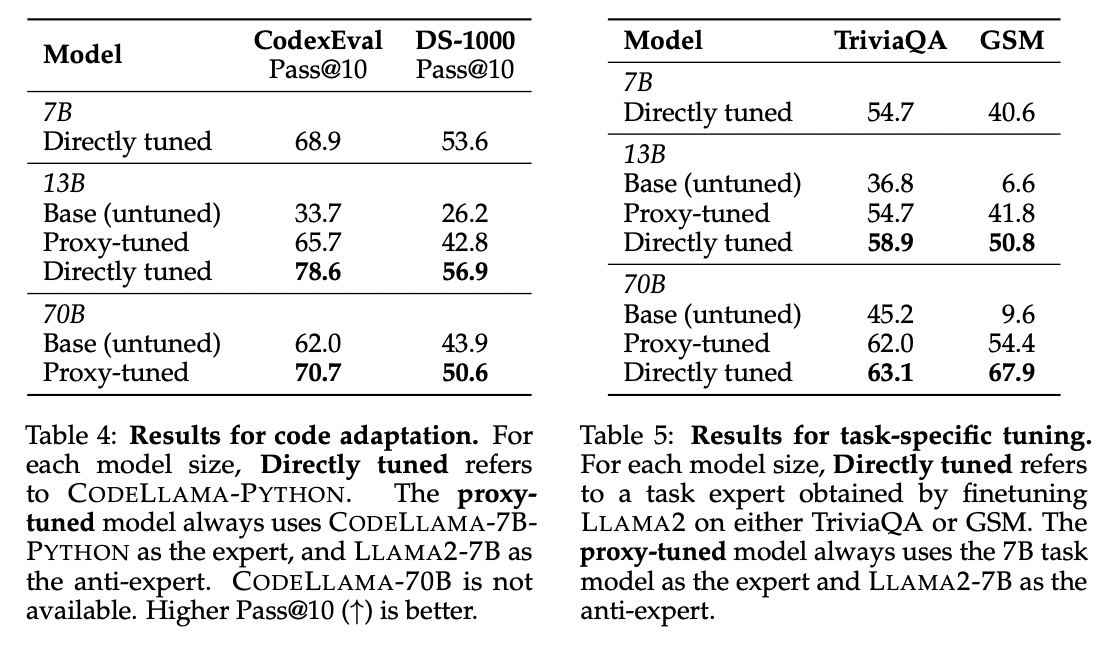
To summarise, The researchers from the University of Washington and Allen Institute for AI have proposed Proxy-tuning, which emerges as a promising approach for fine-tuning large language models at decoding time by modifying output logits. It is an efficient alternative to traditional fine-tuning, making large language models more accessible, especially for those with limited resources. The method also addresses the challenge of adapting proprietary models to diverse use cases. The conclusion invites model-producing organizations to share output probabilities for broader utilization.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
Credit: Source link
Comments are closed.