Researchers from the University of Wisconsin-Madison Challenge the Efficacy of Score-based Generative Models: A Surprising Revelation of Gaussian Mimicry in High-Quality Data Generation
Score-based Generative Models (SGMs) are a prominent approach in generative modeling, celebrated for their capacity to produce high-quality samples from intricate, high-dimensional data distributions. This method has garnered empirical success and is bolstered by robust theoretical convergence properties. Notably, it has been established that SGMs can generate samples from a distribution closely approximating the ground truth when the underlying score function is effectively learned, affirming the efficacy of SGM as a generative model.
Recently developed theories offer a comprehensive set of error bounds to assess the disparity between the learned and ground-truth distribution. This discussion encompasses various statistical distances, such as total variation, KL divergence, and Wasserstein distance.
These theoretical breakthroughs imply that SGMs exhibit robust imitation abilities, demonstrating their capacity to approximate the ground-truth distribution closely. This approximation is particularly effective when the target distribution’s score function (gradient of log density) along the diffusion process is learned efficiently. These discoveries suggest that SGMs can successfully emulate the ground-truth distribution if the crucial score function is effectively mastered.
Researchers introduce a counter-example that challenges this prevailing notion. Through a sample complexity argument, they delineate a specific scenario where the score function is learned successfully. Despite this, SGMs in this particular setting can only produce samples that exhibit Gaussian blurring of training data points, resembling the outcomes of kernel density estimation. This discovery echoes recent findings indicating that SGMs may show a potent memorization effect and encounter challenges in generating diverse samples.
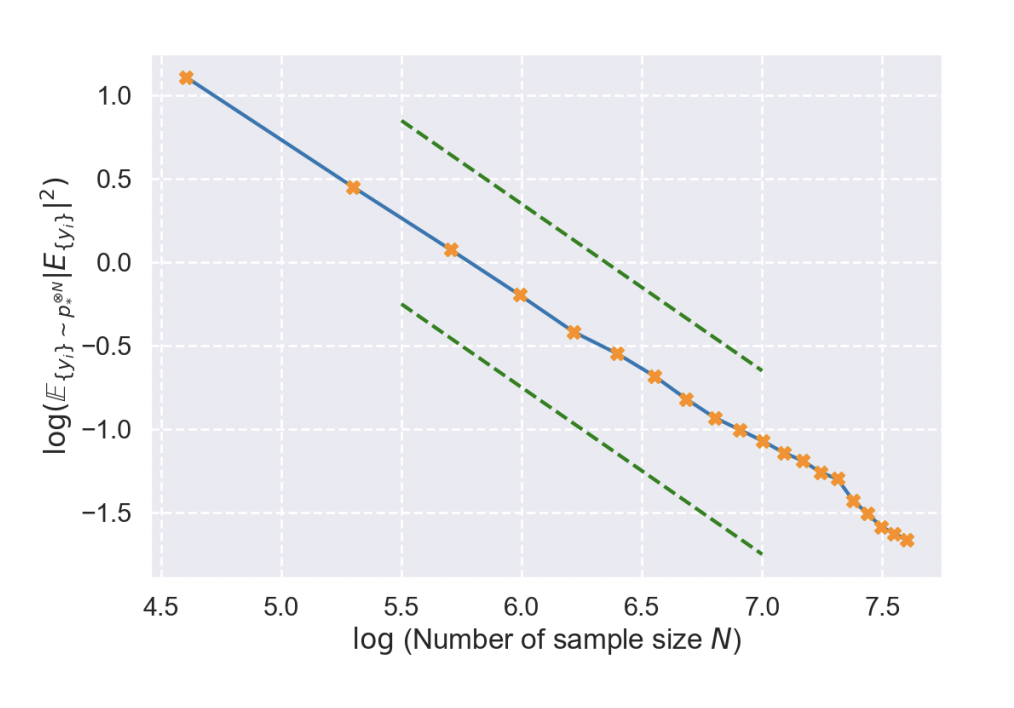
They establish the score-matching error of the empirical optimal score function and provide a detailed non-asymptotic error bound that accounts for sample complexity. The implication of this result is significant, as it suggests that Score-based Generative Models (SGMs) equipped with the empirical optimal score function can generate a distribution that closely aligns with the target distribution.
They demonstrate that SGMs equipped with the empirical optimal score function exhibit characteristics reminiscent of a Gaussian Kernel Density Estimation (KDE). This finding implies that such SGMs manifest robust memorization effects and encounter difficulties in generating novel samples.
In other words, despite the theoretical support for their score-matching capabilities, SGMs in this configuration tend to generate samples that closely mimic the training data, limiting their ability to produce diverse and novel instances. This result provides insight into the limitations and potential challenges associated with relying solely on the empirical optimal score function in the context of SGMs.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Arshad is an intern at MarktechPost. He is currently pursuing his Int. MSc Physics from the Indian Institute of Technology Kharagpur. Understanding things to the fundamental level leads to new discoveries which lead to advancement in technology. He is passionate about understanding the nature fundamentally with the help of tools like mathematical models, ML models and AI.
Credit: Source link
Comments are closed.