Researchers from the University of Wisconsin–Madison Propose Eventful Transformers: A Cost-Effective Approach to Video Recognition with Minimal Loss in Accuracy
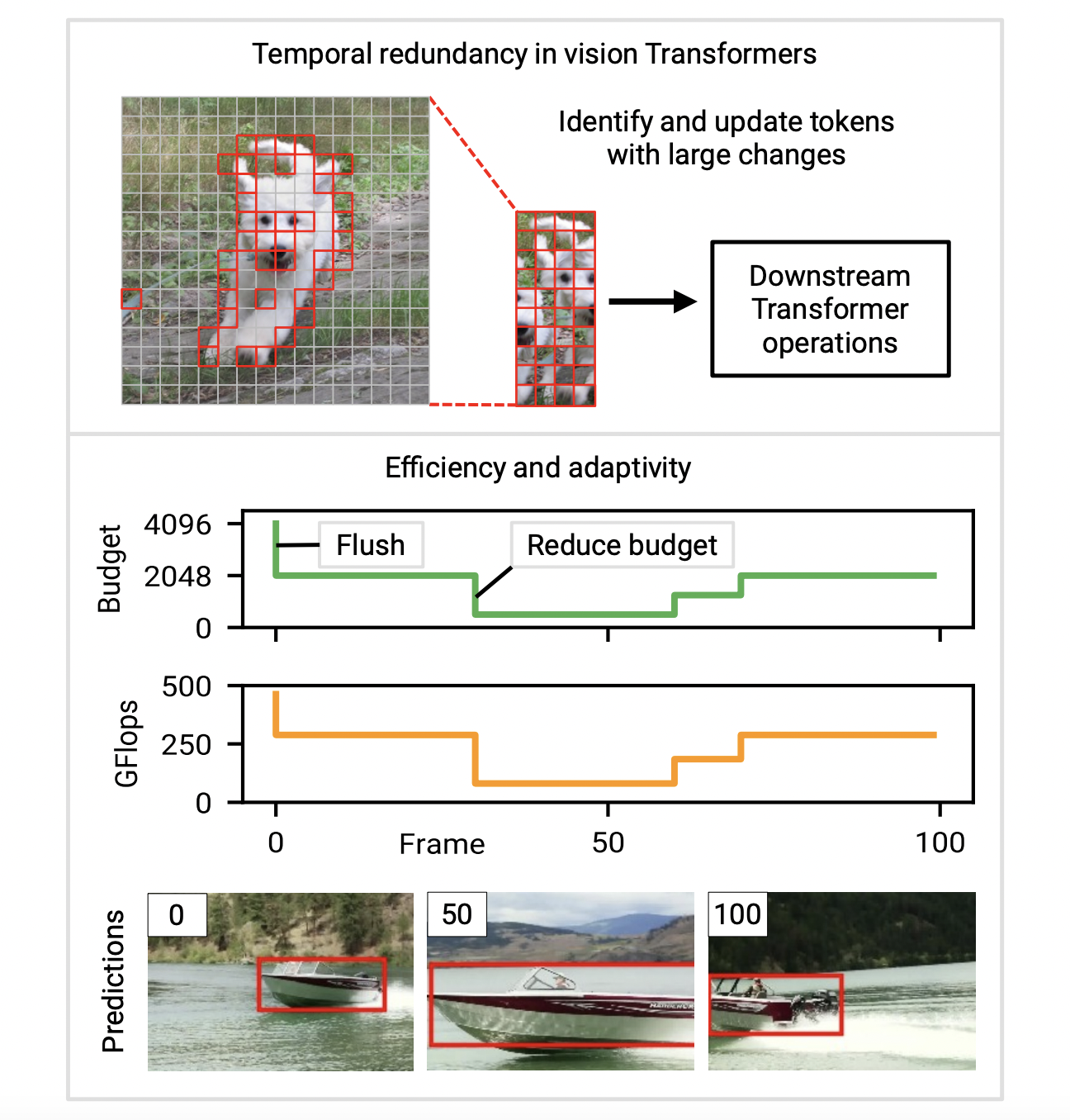
Transformers originally intended for language modeling have lately been investigated as a possible architecture for vision-related tasks. With state-of-the-art performance in applications including object identification, picture classification, and video classification, Vision Transformers have demonstrated excellent accuracy across a variety of visual recognition issues. The high processing cost of vision Transformers is one of their main disadvantages. Vision Transformers sometimes demand orders of magnitude more processing than standard convolutional networks (CNNs), up to hundreds of GFlops per picture. The vast amount of data involved in video processing further increases these expenses. The potential of this otherwise interesting technology is hindered by the high computing requirements that prevent vision Transformers from being used on devices with little resources or that require low latency.
One of the first techniques to leverage the temporal redundancy between succeeding inputs to lower the cost of vision Transformers when used with video data is presented in this work by researchers from the University of Wisconsin–Madison. Think of a vision Transformer that is applied to a video sequence frame-by-frame or clip-by-clip. This Transformer might be a straightforward frame-wise model (such as an object detector) or a transitional stage in a spatiotemporal model (such as the initial factorized model). They view Transformers as being applied to several different inputs (frames or clips) across time, as opposed to language processing, where one Transformer input represents a full sequence. Natural movies have a high degree of temporal redundancy and little variations between frames. Deep networks, such as Transformers, are frequently calculated “from scratch” on each frame despite this.
This method is inefficient since it throws away any potentially useful data from earlier conclusions. Their main insight is that they may make better use of redundant sequences by recycling intermediate calculations from earlier time steps. Intelligent inference. The inference cost for vision Transformers (and deep networks in general) is often set by the design. The resources that are readily available, however, could change over time in real-world applications (for instance, because of competing processes or changes in the power supply). As a result, models that allow for real-time modification of computational cost are required. Adaptivity is one of the main design goals in this study, and the approach is created to provide real-time control over the compute cost. For an illustration of how they change the computed budget during a film, see Figure 1 (lower section).
Previous studies have looked at the CNNs’ temporal redundancy and adaptivity. However, because to significant architectural differences between Transformers and CNNs, these approaches are typically incompatible with the vision of Transformers. Transformers, in particular, introduces a novel primitive—self-attention—which deviates from several CNN-based methodologies. Vision Transformers provide a great possibility despite this obstacle. It is challenging to transfer sparsity gains in CNNs—specifically, the sparsity acquired by taking into account temporal redundancy—into tangible speedups. To do this, either large constraints must be placed on the sparsity structure, or special compute kernels must be used. In contrast, it is simpler to transfer sparsity into shorter runtime using conventional operators because of the nature of Transformer operations, which is centered on manipulating token vectors. Transformers with events.
In order to facilitate effective, adaptive inference, they suggest Eventful Transformers, a novel kind of Transformer that makes use of the temporal redundancy between inputs. The word “Eventful” was coined to describe sensors called event cameras, which create sparse outputs in response to scene changes. Eventful Transformers selectively update the token representations and self-attention maps on each time step in order to track token-level changes over time. Gating modules are blocks in an Eventful Transformer that allow for runtime control of the quantity of updated tokens. Their approach works with a variety of video processing applications and may be used to pre-built models (often without retraining). Their research shows that Eventful Transformers, created from current state-of-the-art models, considerably lower computing costs while mostly maintaining the accuracy of the original model.
Their source code, which contains PyTorch modules for creating Eventful Transformers, is made available to the public. Limitations Wisionlab’s project page is located at wisionlab.com/project/eventful-transformers. On the CPU and GPU, they show speedups in wall time. Their approach, based on standard PyTorch operators, is perhaps not the best from a technical perspective. They are sure that the speedup ratios might be further increased with more work to decrease overhead (such as building a fused CUDA kernel for their gating logic). Additionally, their approach results in certain unavoidable memory overheads. Unsurprisingly, keeping certain tensors in memory is necessary for reusing computation from earlier time steps.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.