Researchers From Tsinghua University Introduce A Novel Machine Learning Algorithm Under The Meta-Learning Paradigm
Recent achievements in supervised tasks of deep learning can be attributed to the availability of large amounts of labeled training data. Yet it takes a lot of effort and money to collect accurate labels. In many practical contexts, only a small fraction of the training data have labels attached. Semi-supervised learning (SSL) aims to boost model performance using labeled and unlabeled input. Many effective SSL approaches, when applied to deep learning, undertake unsupervised consistency regularisation to use unlabeled data.
State-of-the-art consistency-based algorithms typically introduce several configurable hyper-parameters, even though they attain excellent performance. For optimal algorithm performance, it is common practice to tune these hyper-parameters to optimal values. Unfortunately, hyper-parameter searching is often unreliable in many real-world SSL scenarios, such as medical image processing, hyper-spectral image classification, network traffic recognition, and document recognition. This is because the annotated data are scarce, leading to high variance when cross-validation is adopted. Having algorithm performance sensitive to hyper-parameter values makes this issue even more pressing. Moreover, the computational cost may become unmanageable for cutting-edge deep learning algorithms as the search space grows exponentially concerning the number of hyper-parameters.
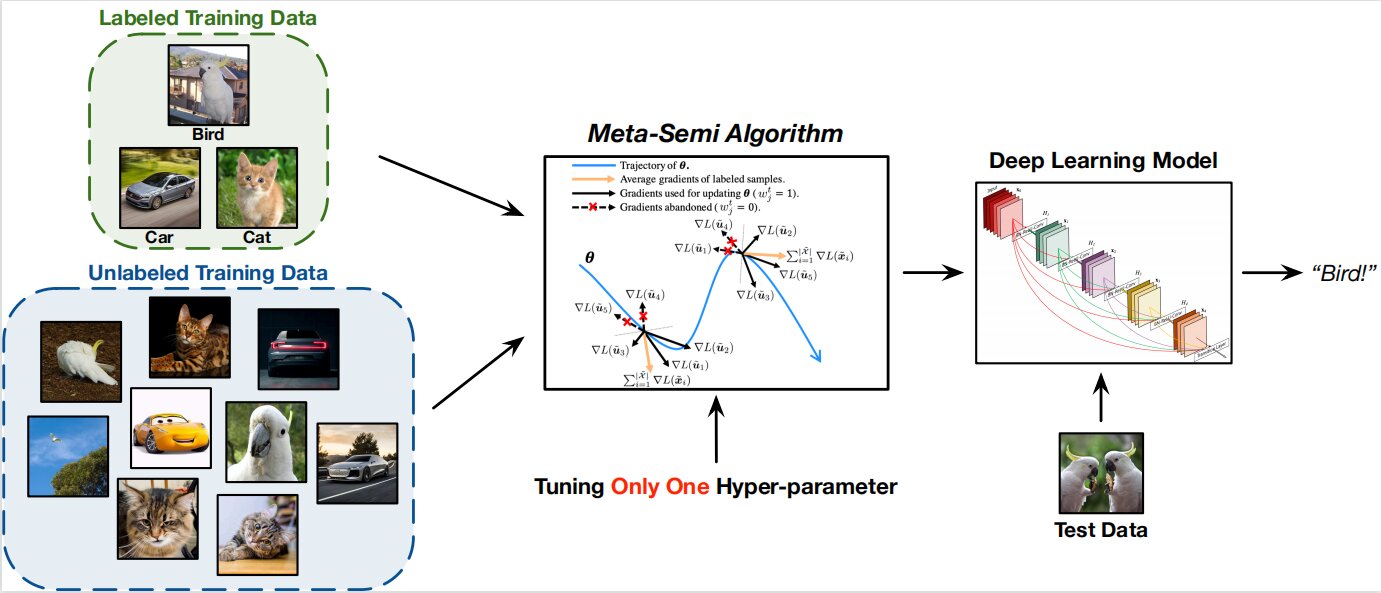
Researchers from Tsinghua University introduced a meta-learning-based SSL algorithm called Meta-Semi to leverage the labeled data more. Meta-Semi achieves outstanding performance in many scenarios by adjusting just one more hyper-parameter.
The team was inspired by the realization that the network may be trained successfully using the appropriately “pseudo-labeled” unannotated examples. Specifically, during the online training phase, they produce pseudo-soft labels for the unlabeled data based on the network predictions. Next, they remove the samples with unreliable or incorrect pseudo labels and use the remaining data to train the model. This work shows that the distribution of correctly “pseudo-labeled” data should be comparable to that of the labeled data. If the network is trained with the former, the final loss on the latter should also be minimized.
They defined the meta-reweighting objective to minimize the final loss on the labeled data by selecting the most appropriate weights (weights throughout the paper always refer to the coefficients used to reweight each unlabeled sample rather than referring to the parameters of neural networks). The researchers encountered computing difficulties when tackling this problem using optimization algorithms.
For this reason, they suggest an approximation formulation from which a closed-form solution can be derived. Theoretically, they demonstrate that each training iteration only needs a single meta gradient step to achieve the approximate solutions.
In conclusion, they suggest a dynamic weighting approach to reweight previously pseudo-labeled samples with 0-1 weights. The results show that this approach eventually reaches the stationary point of the supervised loss function. In popular image classification benchmarks (CIFAR-10, CIFAR-100, SVHN, and STL-10), the proposed technique has been shown to perform better than state-of-the-art deep networks. For the difficult CIFAR-100 and STL-10 SSL tasks, Meta-Semi gets much higher performance than state-of-the-art SSL algorithms like ICT and MixMatch and obtains somewhat better performance than them on CIFAR-10. Moreover, Meta-Semi is a useful addition to consistency-based approaches; incorporating consistency regularisation into the algorithm further boosts performance.
According to the researchers, Meta-Semi requires a little more time to train is a drawback. They plan to look into this issue in the future.
Check out the Paper and Reference Article. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.