Researchers From UC Berkeley and Google Introduce an AI Framework that Formulates Visual Question Answering as Modular Code Generation
The domain of Artificial Intelligence (AI) is evolving and advancing with the release of every new model and solution. Large Language Models (LLMs), which have recently got very popular due to their incredible abilities, are the main reason for the rise in AI. The subdomains of AI, be it Natural Language Processing, Natural Language Understanding, or Computer Vision, all of these are progressing, and for all good reasons. One research area that has recently garnered a lot of interest from AI and deep learning communities is Visual Question Answering (VQA). VQA is the task of answering open-ended text-based questions about an image.
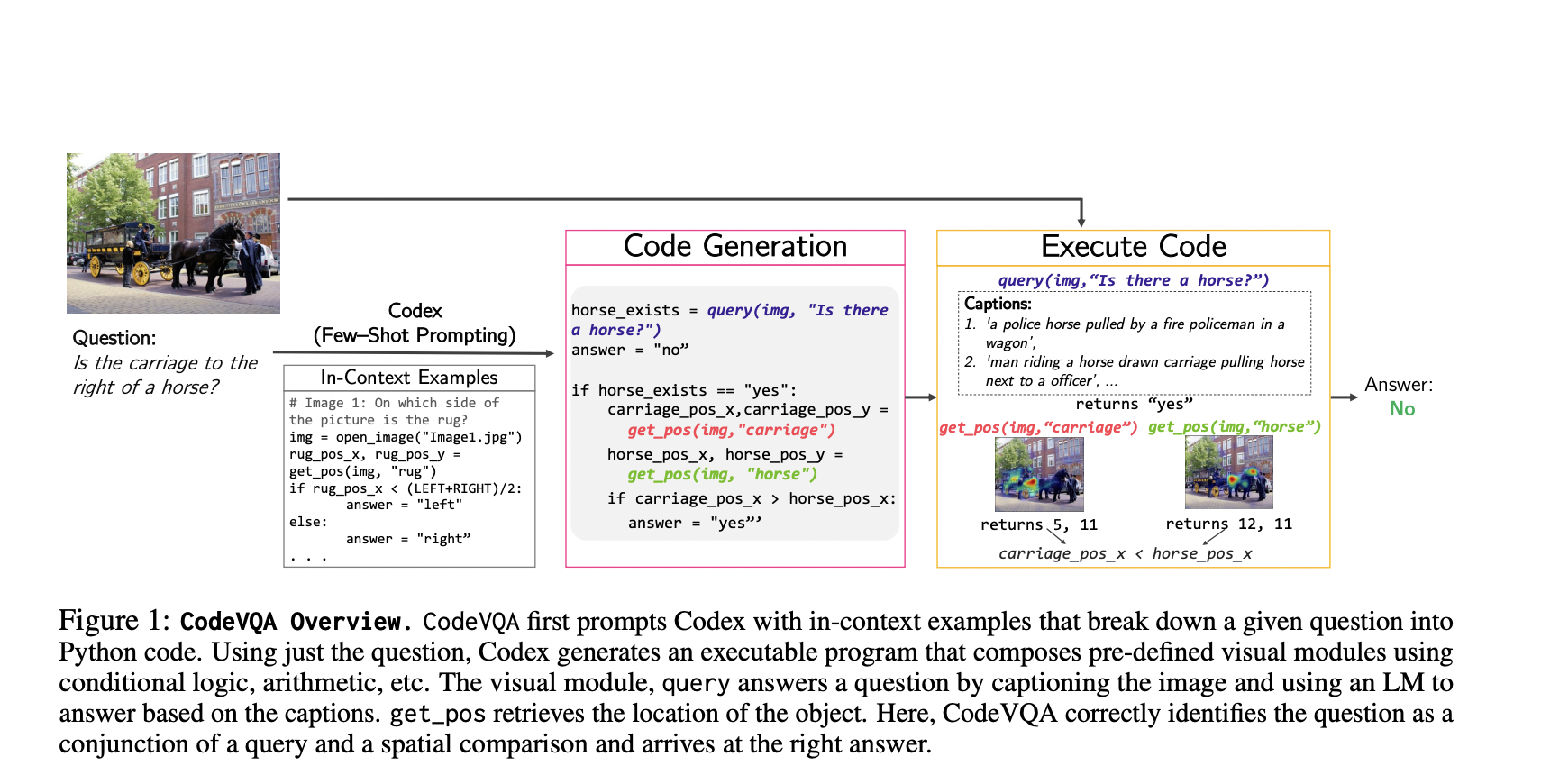
Systems adopting Visual Question Answering attempt to appropriately answer questions in natural language regarding an input in the form of an image, and these systems are designed in a way that they understand the contents of an image similar to how humans do and thus effectively communicate the findings. Recently, a team of researchers from UC Berkeley and Google Research has proposed an approach called CodeVQA that addresses visual question answering using modular code generation. CodeVQA formulates VQA as a program synthesis problem and utilizes code-writing language models which take questions as input and generate code as output.
This framework’s main goal is to create Python programs that can call pre-trained visual models and combine their outputs to provide answers. The produced programs manipulate the visual model outputs and derive a solution using arithmetic and conditional logic. In contrast to previous approaches, this framework uses pre-trained language models, pre-trained visual models based on image-caption pairings, a small number of VQA samples, and pre-trained visual models to support in-context learning.
To extract specific visual information from the image, such as captions, pixel locations of things, or image-text similarity scores, CodeVQA uses primitive visual APIs wrapped around Visual Language Models. The created code coordinates various APIs to gather the necessary data, then uses the full expressiveness of Python code to analyze the data and reason about it using math, logical structures, feedback loops, and other programming constructs to arrive at a solution.
For evaluation, the team has compared the performance of this new technique to a few-shot baseline that does not use code generation to gauge its effectiveness. COVR and GQA were the two benchmark datasets used in the evaluation, among which the GQA dataset includes multihop questions created from scene graphs of individual Visual Genome photos that humans have manually annotated, and the COVR dataset contains multihop questions about sets of images in the Visual Genome and imSitu datasets. The outcomes showed that CodeVQA performed better on both datasets than the baseline. In particular, it showed an improvement in the accuracy by at least 3% on the COVR dataset and by about 2% on the GQA dataset.
The team has mentioned that CodeVQA is simple to deploy and utilize because it doesn’t require any additional training. It makes use of pre-trained models and a limited number of VQA samples for in-context learning, which aids in tailoring the created programs to particular question-answer patterns. To sum up, this framework is powerful and makes use of the strength of pre-trained LMs and visual models, providing a modular and code-based approach to VQA.
Check Out The Paper and GitHub link. Don’t forget to join our 24k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.