Researchers from UCLA and Google Propose AVIS: A Groundbreaking AI Framework for Autonomous Information Seeking in Visual Question Answering
GPT3, LaMDA, PALM, BLOOM, and LLaMA are just a few examples of large language models (LLMs) that have demonstrated their ability to store and apply vast amounts of information. New skills such as in-context learning, code creation, and common sense reasoning are displayed. A recent push has been to train LLMs to simultaneously process visual and linguistic data. GPT4, Flamingo, and PALI are three illustrious examples of VLMs. They established new benchmarks for numerous tasks, including picture captioning, visual question answering, and open vocabulary recognition. While state-of-the-art LLMs do far better than humans can on tasks involving textual information retrieval, state-of-the-art VLMs struggle with visual information-seeking datasets like Infoseek, Oven, and OK-VQA.
For many reasons, it is difficult for today’s most advanced vision-language models (VLMs) to respond satisfactorily to such inquiries. Youngsters need to be taught to recognize fine-grained categories and specifics in images. Second, their reasoning must be more robust because they employ a smaller language model than state-of-the-art Large Language Models (LLMs). Finally, unlike image search engines, they do not examine the query image against a large corpus of images tagged with different metadata. In this study, researchers from the University of California, Los Angeles (UCLA) and Google provide a novel approach to overcoming these obstacles by merging LLMs with three different types of tools, resulting in state-of-the-art performance on visual information-seeking tasks.
- Computer programs that help with visual information extraction include object detectors, optical character recognition software, picture captioning models, and visual quality assessment software.
- An online resource for discovering data and information about the outside world
- A method of finding relevant results in an image search by mining the metadata of visually related images.
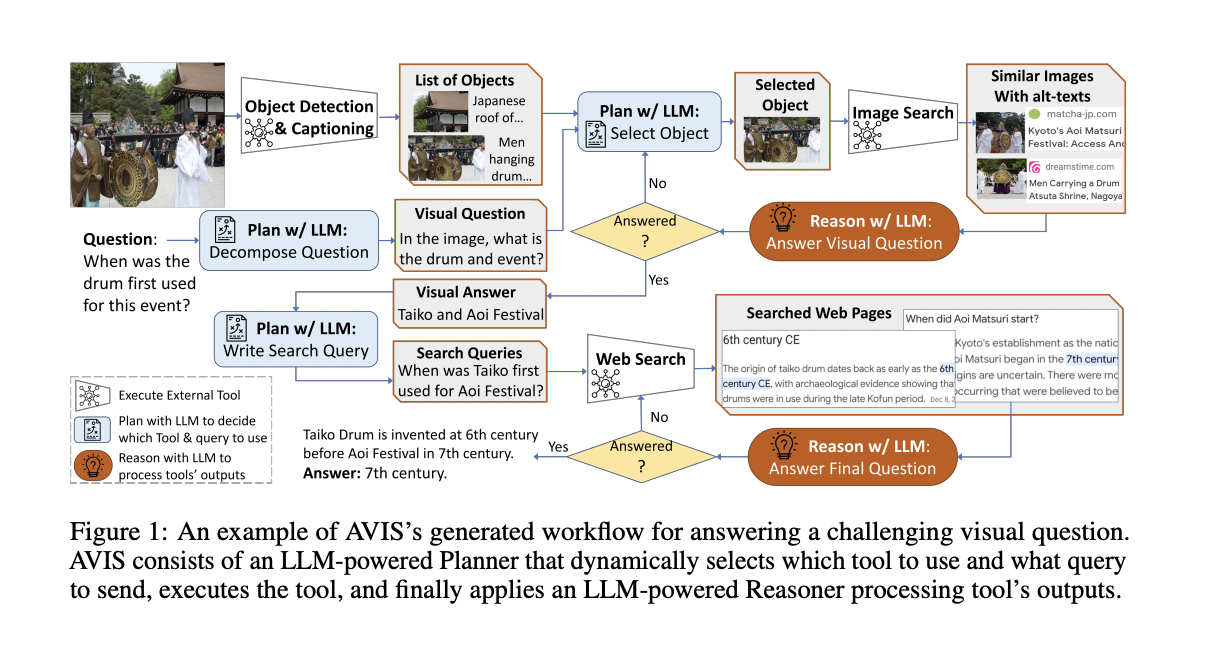
The method employs a planner driven by an LLM to decide which tool to employ and what query to send to it on the fly. In addition, researchers use a reasoner powered by LLM to examine the results of the tools and pull out the relevant data.
To begin, the LLM simplifies a query into a strategy, a program, or a set of instructions. After this, the appropriate APIs are activated to gather data. While promising in simple visual-language challenges, this approach often needs to be revised in more complex real-world scenarios. An all-encompassing strategy cannot be determined from such an initial query. Instead, it calls for continuous iteration in response to ongoing data. The capacity to make decisions on the fly is the key innovation of the proposed strategy. Planning for questions that require visual information is a multi-step process due to the complexity of the assignment. The planner must decide which API to use and what query to submit at each stage. It can only anticipate the utility of answers from sophisticated APIs like image search or predict their output after calling them. Therefore, researchers choose a dynamic strategy rather than the traditional methods, which include upfront planning of process stages and API calls.
Researchers perform a user study to understand better how people make choices while interacting with APIs to find visual information. For the Large Language Model (LLM) to make educated choices about API selection and query formulation, they compile this information into a systematic framework. There are two major ways in which the system benefits from the user data collected. They begin by building a transition graph by deducing the order of user actions. This graph defines the boundaries between states and the steps that can be taken in each. Second, they provide the planner and the reasoner with useful examples of user decision-making.
Key Contributions
- The team proposes an innovative visual question-answering framework, which uses a large language model (LLM) to strategize the use of external tools dynamically and the investigation of their outputs, therefore learning the knowledge required to deliver answers to the questions posed.
- The team uses the findings from the user study on how people make decisions to create a systematic plan. This framework instructs the Large Language Model (LLM) to mimic human decision-making when selecting APIs and building queries.
- The strategy outperforms state-of-the-art solutions on Infoseek and OK-VQA, two benchmarks for knowledge-based visual question answering. In particular, compared to PALI’s 16.0% accuracy on the Infoseek (unseen entity split) dataset, our results are substantially higher at 50.7%.
APIs and other Tools
AVIS (Autonomous Visual Information Seeking with Large Language Models) needs a robust set of resources to respond to visual inquiries requiring proper in-depth information retrieval.
- Image Captioning Model
- Visual Question Answering Model
- Object Detection
- Image Search
- OCR
- Web Search
- LLM Short QA
Limitations
Currently, AVIS’s primary function is to provide visual responses to questions. The researchers plan to broaden the scope of the LLM-driven dynamic decision-making system to incorporate additional reasoning applications. The current framework also requires the PALM model, a computationally complex LLM. They want to determine if smaller, less computationally intensive language models can make the same decisions.
To sum it up, UCLA and Google researchers have proposed a new method that gives Large Language Models (LLM) access to a wide range of resources for processing visually oriented knowledge queries. The methodology is founded on user study data on human decision-making. It uses a structured framework in which an LLM-powered planner chooses which tools to utilize and how to build queries on the fly. The selected tool’s output will be processed, and a reasoner powered by 9 LLM will extract key information. A visual question is broken down into smaller pieces, and the planner and reasoner work together to solve each one using a variety of tools until they have accumulated enough data to answer the issue.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.