Researchers from Yale and Google Introduce HyperAttention: An Approximate Attention Mechanism Accelerating Large Language Models for Efficient Long-Range Sequence Processing
The rapid advancement of large language models has paved the way for breakthroughs in natural language processing, enabling applications ranging from chatbots to machine translation. However, these models often need help processing long sequences efficiently, essential for many real-world tasks. As the length of the input sequence grows, the attention mechanisms in these models become increasingly computationally expensive. Researchers have been exploring ways to address this challenge and make large language models more practical for various applications.
A research team recently introduced a groundbreaking solution called “HyperAttention.” This innovative algorithm aims to efficiently approximate attention mechanisms in large language models, particularly when dealing with long sequences. It simplifies existing algorithms and leverages various techniques to identify dominant entries in attention matrices, ultimately accelerating computations.

HyperAttention’s approach to solving the efficiency problem in large language models involves several key elements. Let’s dive into the details:
- Spectral Guarantees: HyperAttention focuses on achieving spectral guarantees to ensure the reliability of its approximations. Utilizing parameterizations based on the condition number reduces the need for certain assumptions typically made in this domain.
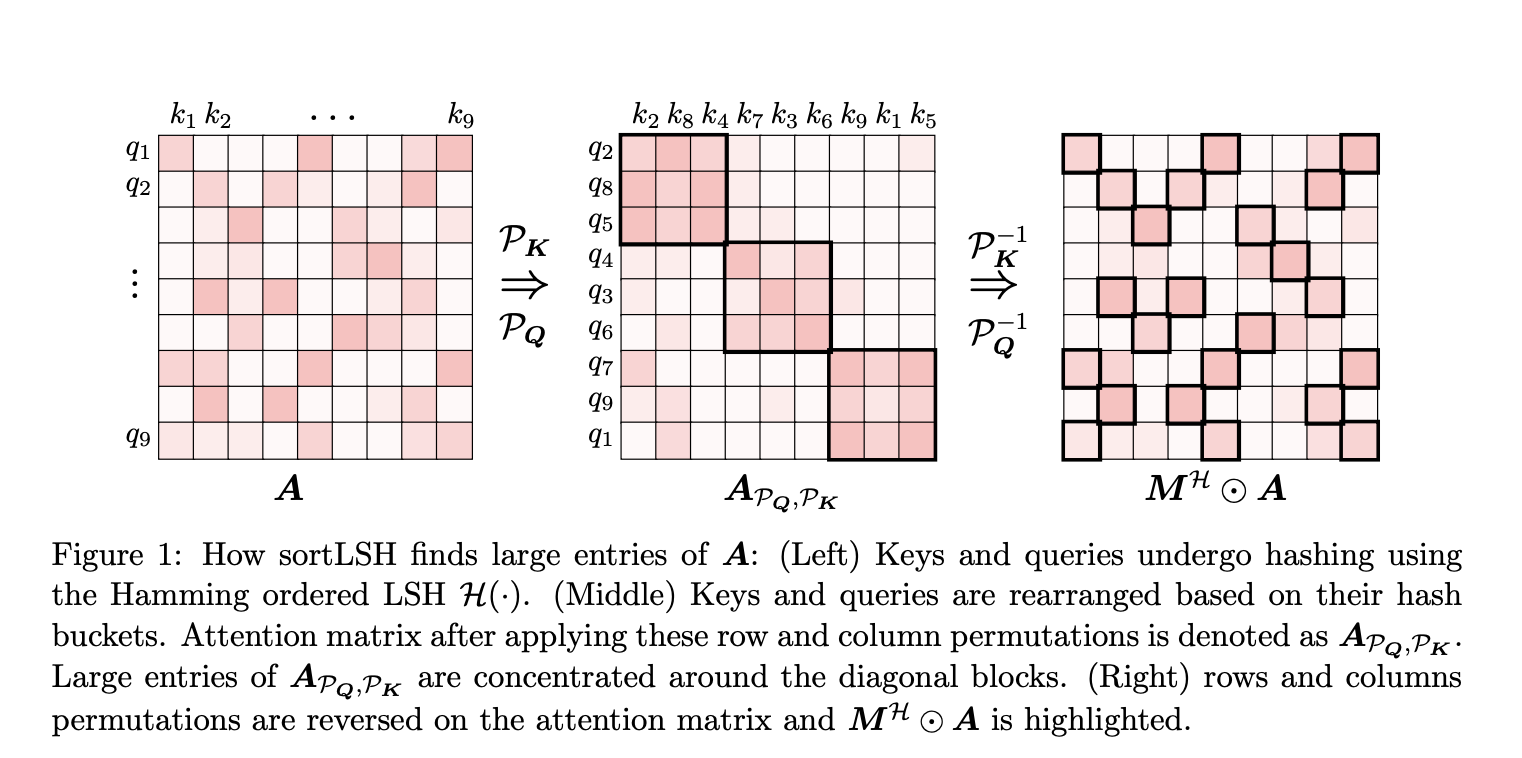
- SortLSH for Identifying Dominant Entries: HyperAttention uses the Hamming sorted Locality-Sensitive Hashing (LSH) technique to enhance efficiency. This method allows the algorithm to identify the most significant entries in attention matrices, aligning them with the diagonal for more efficient processing.
- Efficient Sampling Techniques: HyperAttention efficiently approximates diagonal entries in the attention matrix and optimizes the matrix product with the values matrix. This step ensures that large language models can process long sequences without significantly dropping performance.
- Versatility and Flexibility: HyperAttention is designed to offer flexibility in handling different use cases. As demonstrated in the paper, it can be effectively applied when using a predefined mask or generating a mask using the sortLSH algorithm.

The performance of HyperAttention is impressive. It allows for substantial speedups in both inference and training, making it a valuable tool for large language models. By simplifying complex attention computations, it addresses the problem of long-range sequence processing, enhancing the practical usability of these models.


In conclusion, the research team behind HyperAttention has made significant progress in tackling the challenge of efficient long-range sequence processing in large language models. Their algorithm simplifies the complex computations involved in attention mechanisms and offers spectral guarantees for its approximations. By leveraging techniques like Hamming sorted LSH, HyperAttention identifies dominant entries and optimizes matrix products, leading to substantial speedups in inference and training.
This breakthrough is a promising development for natural language processing, where large language models play a central role. It opens up new possibilities for scaling self-attention mechanisms and makes these models more practical for various applications. As the demand for efficient and scalable language models continues to grow, HyperAttention represents a significant step in the right direction, ultimately benefiting researchers and developers in the NLP community.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Madhur Garg is a consulting intern at MarktechPost. He is currently pursuing his B.Tech in Civil and Environmental Engineering from the Indian Institute of Technology (IIT), Patna. He shares a strong passion for Machine Learning and enjoys exploring the latest advancements in technologies and their practical applications. With a keen interest in artificial intelligence and its diverse applications, Madhur is determined to contribute to the field of Data Science and leverage its potential impact in various industries.
Credit: Source link
Comments are closed.