Researchers, Including Yann Lecun, Propose ‘projUNN’: An Efficient Method For Training Deep Neural Networks With Unitary Matrices
This research summary is based on the paper 'projUNN: efficient method for training deep networks with unitary matrices' Please don't forget to join our ML Subreddit
When deep networks or inputs involve extensive data sequences, learning in neural networks can be unstable. Recurrent states in vanilla recurrent neural networks (RNNs) are generated by repeatedly applying a linear transformation followed by a pointwise nonlinearity. This becomes unstable when the linear transformation’s eigenvalues are not of magnitude one.
Unitary matrices have been utilized to solve the problem of disappearing and exploding gradients because they have eigenvalues of size one, naturally, and have been. Unitary convolutional layers have recently been developed in a similar way to aid in the development of more stable deep networks with norm-preserving transformations.
The loss function’s derivative with respect to the weights is called a gradient. During backpropagation in neural networks, it is utilized to update the weights to minimize the loss function. When traveled backward with each layer, the derivative or slope continuously grows lower, resulting in a vanishing gradient. When the weight update is exponentially small, the training time is excessively long. In the worst-case scenario, the neural network training may be stopped entirely. Exploding gradients, on the other hand, occur when the slope increases with each successive layer during backpropagation. The gradient will never converge due to the high weights, causing it to oscillate around the minima without ever reaching a global minima point.
The efficient unitary recurrent neural network (EUNN) is a popular method for parameterizing unitary matrices by composing unitary transformations such as Given rotations and Fourier transformers.

While using unitary matrices in each layer is efficient, maintaining long-range stability by confining network parameters to be strictly unitary comes at the cost of costly parameterization and longer training times.
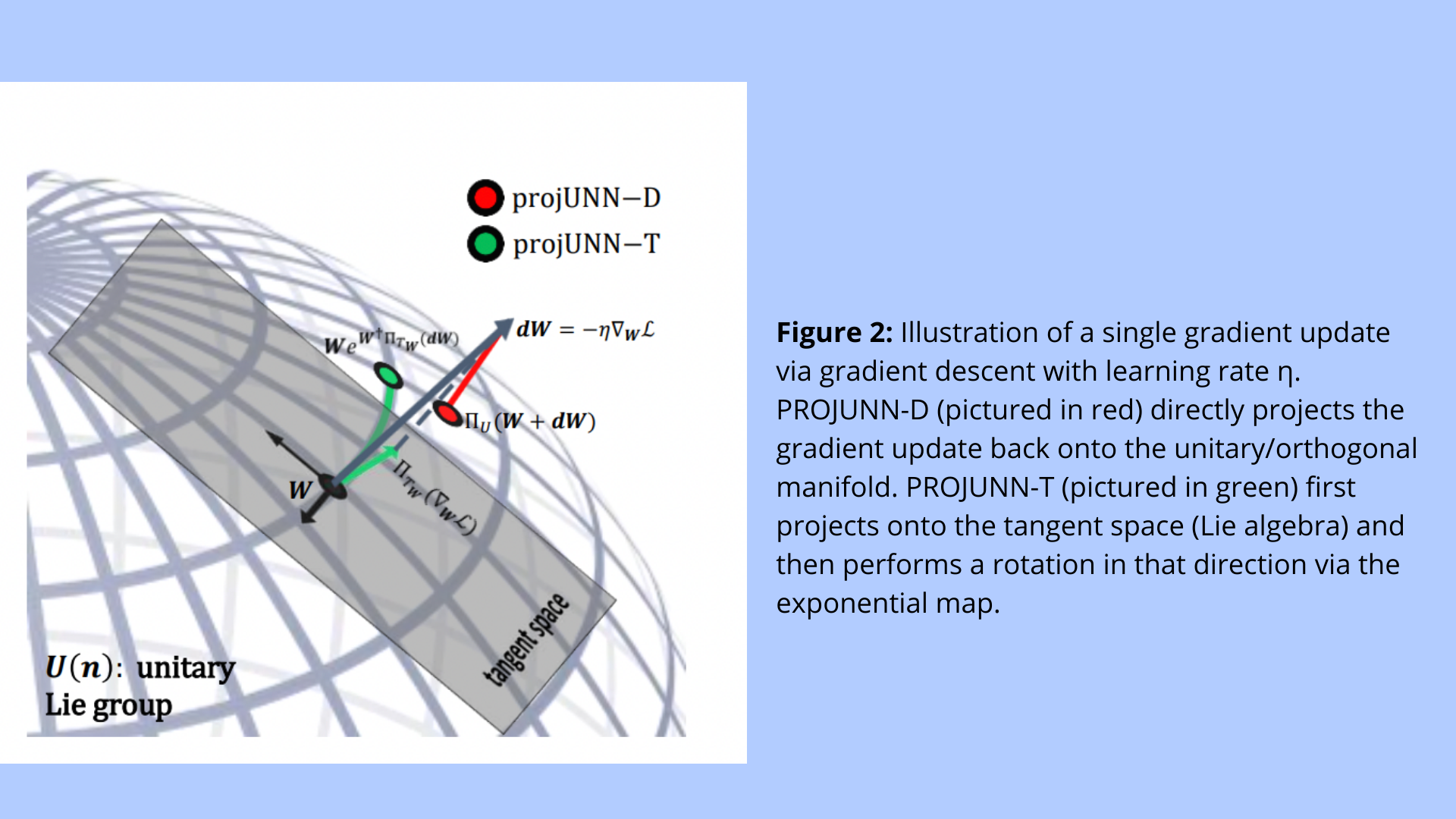
Motivated by the low rank of gradients in neural networks, the researchers from MIT, Facebook AI, and New York University undertook a study to prove that gradient updates to unitary/orthogonal matrices may be efficiently executed in low-rank conditions. Their research introduces a new paradigm called PROJUNN, in which matrices are directly updated via gradient-based optimization, then projected back onto the closest unitary (PROJUNN-D) or transferred in the gradient direction (PROJUNN-T). PROJUNN equals or exceeds existing standards of state-of-the-art unitary neural network algorithms in RNN learning challenges. Compared to other unitary RNN algorithms, this technique has the lowest time complexity. It is notably successful in the most extreme scenario where rank-one matrices represent gradients.
Though the model is described in the context of RNNs, PROJUNN has a direct extension to the situation of orthogonal/unitary convolution. The researchers use [TK21] to perform unitary/orthogonal convolution in the Fourier domain. In the convolutional scenario, this technique performs well, especially for big filters with numerous channels.
Paper: https://arxiv.org/pdf/2203.05483.pdf
Suggested
Credit: Source link
Comments are closed.