Researchers Introduce a Deep Learning Approach, ‘DeepDPM’, that Supports Deep Clustering without Knowing the Number of Clusters
This article is based on the research paper 'DeepDPM: Deep Clustering With an Unknown Number of Clusters'. All credit for this research goes to the researchers of this paper 👏👏👏 Please don't forget to join our ML Subreddit
Clustering is an unsupervised machine learning technique for discovering and grouping related data points in huge datasets. It organizes data into structures that are easier to comprehend and manipulate.
Deep clustering frameworks combine feature extraction, dimensionality reduction, and clustering into a single end-to-end model, allowing deep neural networks to learn appropriate representations that adapt to the model’s assumptions and criteria.
Deep clustering is parametric, which means it requires a predetermined cluster or class number, similar to other clustering algorithms. However, given the comparative complexity of DNN designs, determining the ideal cluster number may be highly computationally costly.

In this summary article, we will talk about a new approach called DeepDPM, proposed by a research team at the Ben-Gurion University of Negev in their recent paper, “Deep Clustering With an Unknown Number of Clusters.” DeepDPM is a powerful deep nonparametric technique that eliminates the requirement to predefine the number of clusters in clustering tasks and instead infers it. The suggested technique achieves SOTA outcomes while being similar to prominent parametric methods and outperforming existing nonparametric methods using both traditional and deep approaches.
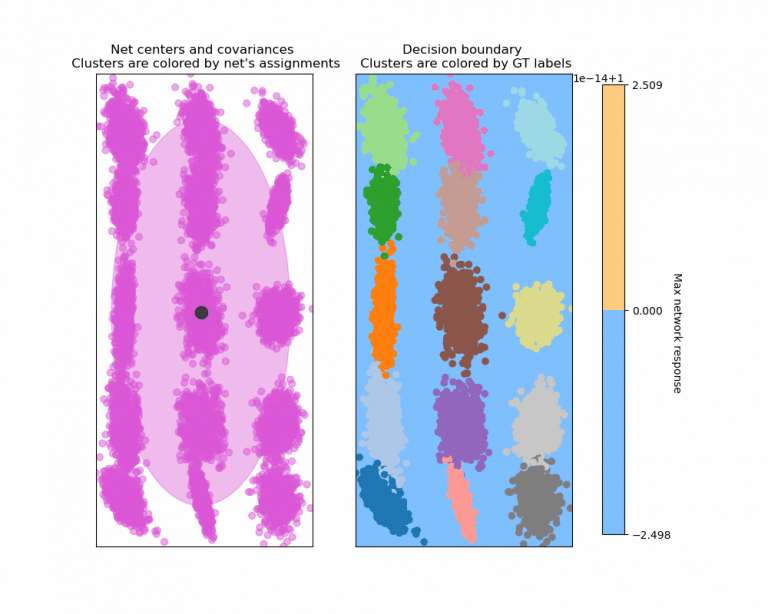
DeepDPM is an approach that allows users to infer and alter the number of clusters during training. It is divided into two sections:
- For each input data point, a clustering net creates soft cluster assignments.
- Subclustering nets use previously created soft cluster assignments as inputs and create soft subcluster assignments. This will subsequently be utilized to enable split and merge choices to adapt to and modify the number of clusters dynamically.
To make the DeepDPM more resilient and efficient, a new loss function is inspired by the expectation-maximization process in Bayesian Gaussian mixed models (EM-GMM).

On commonly used image and text datasets at varied sizes, the researchers compared DeepDPM against both conventional parametric, classical nonparametric, and deep nonparametric approaches. When comparing all approaches, the assessments demonstrate that DeepDPM nearly uniformly gets the greatest performance across all datasets, approaching SOTA levels. DeepDPM is also resilient to both class imbalance and starting cluster value. It can greatly reduce resource utilization by eliminating the need to constantly train deep parametric techniques for model selection.
Despite having several advantages, DeepDPM, like most clustering algorithms, would fail to recover if the input features were weak. Furthermore, parametric approaches (e.g., SCAN) may also be a somewhat better alternative if parameter numbers are known and the dataset is balanced.
The researchers state that adapting DeepDPM to streaming data or hierarchical situations is an intriguing direction to work in the future. Furthermore, the achieved results would improve on a more sophisticated framework.
This team hopes that their work will inspire others working in deep clustering to investigate additional nonparametric techniques.
Paper: https://arxiv.org/pdf/2203.14309.pdf
Github: https://github.com/BGU-CS-VIL/DeepDPM
Credit: Source link
Comments are closed.