Researchers Introduce A Machine Learning-Based Algorithm For Efficiently Approximating Matrix Multiplies
One of the most important and computationally demanding processes in machine learning is matrix multiplication. As a result, much research has been done on matrix multiplies that can be approximated well. Researchers attempt to develop a learning-based system that performs far better than current approaches in this study. It runs 100 times faster than actual matrix products and ten times faster than the most popular approximative algorithms, according to experiments utilizing hundreds of matrices from various fields. The approach also has the intriguing virtue of requiring zero multiply-adds when one matrix is known beforehand, which is a typical scenario.
These findings point to a more promising foundation for machine learning than the sparsified, factorized, and scalar quantized matrix products that have lately been the subject of intensive study and hardware investment: a combination of hashing, averaging, and byte shuffling. The main difficulty is minimizing the amount of computation time needed to approximate linear processes with a certain level of precision. When one obtains a data matrix A whose rows are samples and wants to apply a linear operator B to these samples, this situation naturally occurs in machine learning and data mining. B might be, among other things, a linear classifier, a linear regressor, or an embedding matrix.
As a practical illustration, take the job of approximating a softmax classifier trained to predict picture labels using embeddings obtained from a neural network. Here, columns of B are the weight vectors for each class, while the rows of A are the embeddings for each picture. By computing the product AB and obtaining the argmax inside each result row, classification is accomplished. On the CIFAR-10 and CIFAR-100 datasets, our technique outperformed its top competitors. The results are shown in the figure below.

Instead, MADDNESS1 applies a nonlinear preprocessing function and simplifies the problem to table lookups. Furthermore, when B is known ahead of time, such as when applying a trained linear model to new data, MADDNESS does not require any multiply-add operations. The approach is most closely connected to vector similarity search methods. Instead of utilizing a costly quantization function with multiple multiply-adds, a family of quantization functions with no multiply-adds has been presented.
The paper’s contributions can be summarised as follows:
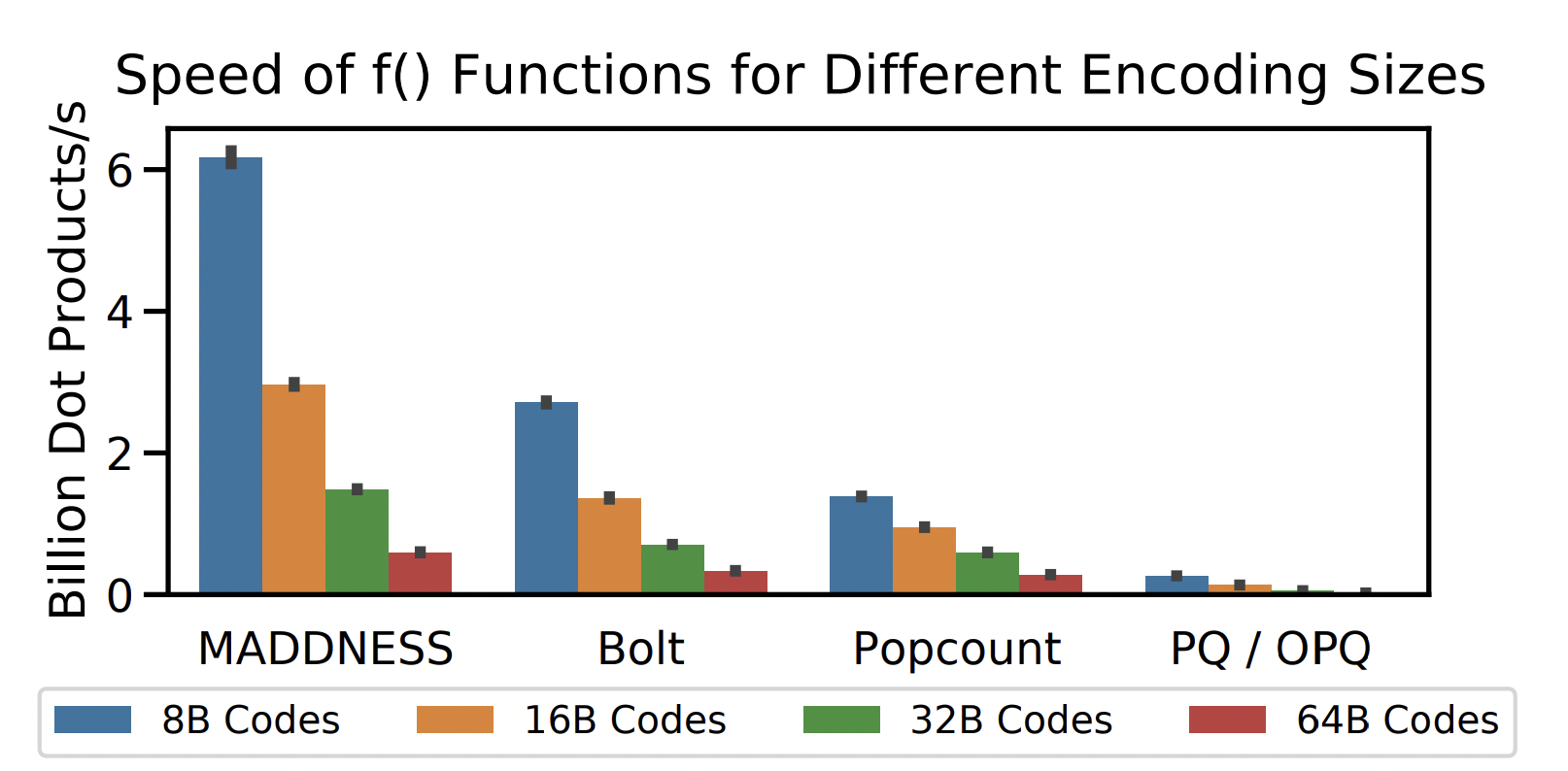
- A fast family of learning vector quantization algorithms capable of encoding more than 100GB of data per second in a single CPU thread.
- A low-bandwidth integer summing technique that avoids upcasting, saturation, and overflow.
- A method for approximate matrix multiplication based on these functions. Experiments on hundreds of different matrices show that our approach surpasses existing options substantially. It also includes theoretical quality assurances.
The critical empirical conclusion is that the proposed MADDNESS approach delivers order-of-magnitude speedups over existing AMM methods and up to two-order-of-magnitude speedups over the packed baseline. Up to three orders of magnitude can also compress matrixes. These findings are computed on a CPU and are only available when a training set for one matrix exists. Researchers claim higher performance only when one matrix is larger than the other and both matrices are tall. This is the regime in which the high-speed (but less accurate) encoding function is advantageous.
When the more extensive matrix is known ahead of time, the approach loses usefulness; this assumption is frequent in similarity search and eliminates the requirement for a quick encoding function. The approximate integer summation and fused table lookups are likely usable even without any of these assumptions, but establishing this is a task for the future. The source code of MADDNESS is freely available on GitHub.
This Article is written as a summary article by Marktechpost Staff based on the paper 'Multiplying Matrices Without Multiplying'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper, github. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.