Researchers Introduce ‘Alpa’: A Compiler System for Distributed Deep Learning, Built on Top of Machine Learning Parallelization Approaches, That Automatically Generates Parallel Execution Plans Covering All Data, Operator, and Pipeline Parallelisms
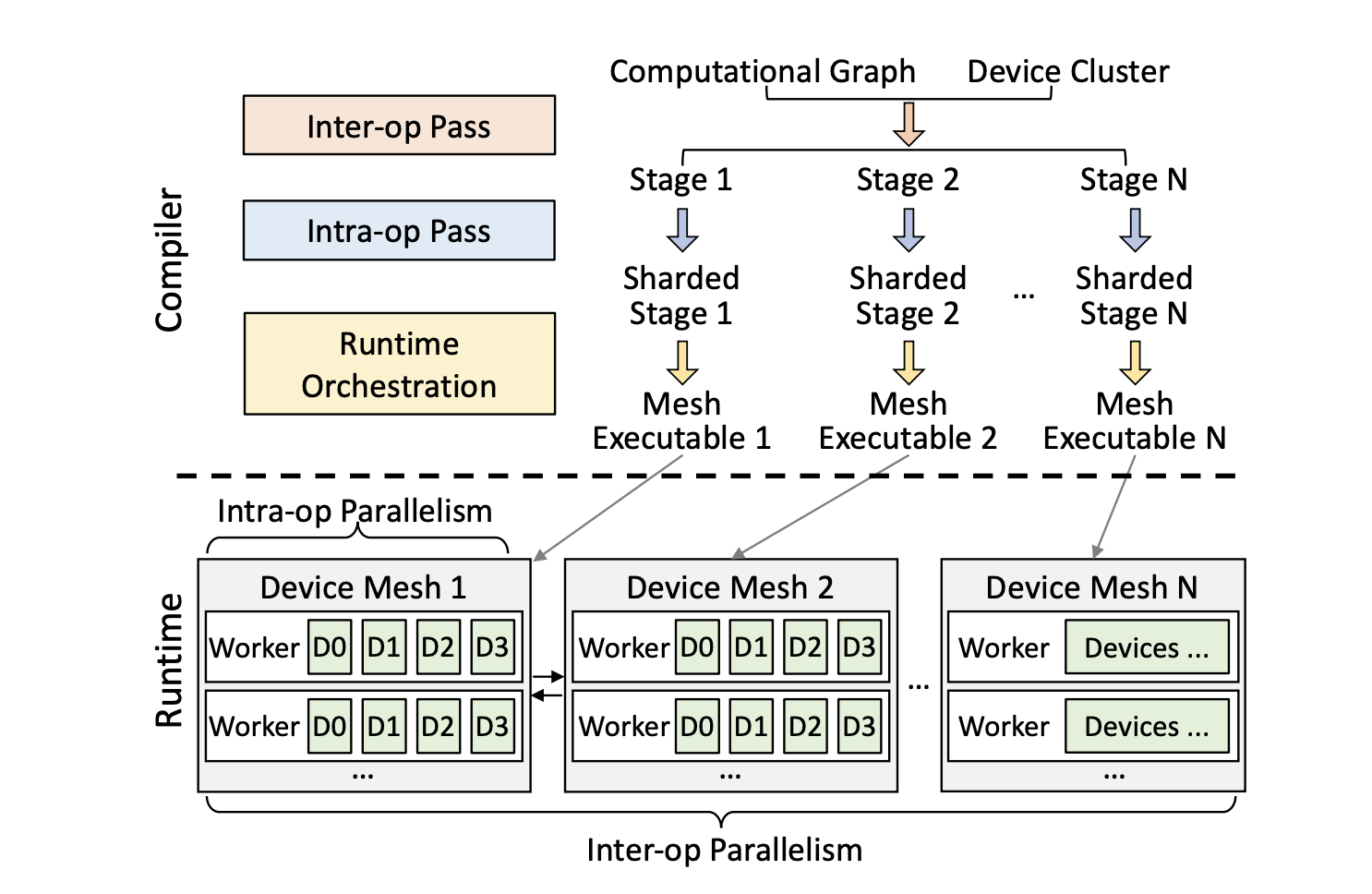

Training extremely massive deep learning (DL) models on clusters of high-performance accelerators necessitate significant engineering effort for model definition and training cluster environment specifications and typically necessitates tuning a complex combination of data, operator, and pipeline parallelization approach for individual network operators.
Automating the parallelization of large-scale models could speed up DL development and deployment, but due to the intricate structures involved, it remains a difficult undertaking. To address this problem, a group of researchers from UC Berkeley, Amazon Web Services, Google, Shanghai Jiao Tong University, and Duke University proposed Alpa, a compiler system for distributed DL on GPU clusters that can automatically generate parallelization plans that match or outperform hand-tuned model-parallel training systems, even on the models for which they were designed.
The team creates a two-level parallel execution plan space in which plans are stated hierarchically utilizing inter and intra-operator parallelisms, and tractable optimization methods are used to derive efficient execution plans at each level. Alpa, a compiler system for distributed DL on GPU clusters, is being developed by the team. Alpa includes a collection of compilation passes that use hierarchical optimization methods to build execution plans.
It includes a new runtime architecture for orchestrating inter-op parallelism between stages and device meshes, as well as a number of system optimizations for better compilation and cross-mesh communication. Alpa is being tested on big models with billions of parameters by the team.

Data, operator, and pipeline parallelisms are the most common types of DL parallelization techniques. The training data is divided across distributed workers in data parallelism, with each worker computing parameter updates on its own data split. Meanwhile, operator parallelism divides the computation of a single operator into parts and computes each portion in parallel across numerous devices. Pipeline parallelism is a technique that divides the training batch into micro-batches and then pipes the backward and forward passes across micro-batches on distributed workers.
The team reclassifies existing parallelization methodologies into two orthogonal categories: intra-operator and inter-operator parallelisms, departing from the usual paradigm. inter-operator parallelism divides the model into disjoint stages and pipelines the execution of stages on various sets of devices, whereas intra-operator parallelism slices the model into disjoint stages and pipes the execution of stages on different sets of devices.
By stating the plan in each parallelism category, a parallel execution plan can be written hierarchically, resulting in two significant benefits: 1) In a compute cluster, it becomes possible to take advantage of the asymmetric nature of communication bandwidth and map intra-operator parallelism to devices with high communication bandwidth while orchestrating inter-operator parallelism between distant devices with lower bandwidth; and 2) Each level can be solved optimally as a separate tractable sub-problem, resulting in significant performance gains when training large models.
Overall, Alpa’s unique contribution as a compiler is that it builds model-parallel execution plans by hierarchically optimizing the plan at two levels: intra-op parallelism and inter-op parallelism.
The researchers examined Alpa’s performance against two state-of-the-art distributed systems, Nvidia’s Megatron-LM v2 and Microsoft’s DeepSpeed, on the training of large-scale models with billions of parameters, such as GPT-3, GShard Mixture-of-Experts (MoE), and Wide-ResNet.
Alpa’s performance on GPT models was comparable to that of the specialist Megatron-LM system in the tests. Alpa obtained a 3.5x speedup on two nodes and a 9.7x speedup on four nodes when compared to the hand-tuned DeepSpeed on GShard MoE models.
Paper: https://arxiv.org/pdf/2201.12023.pdf
Suggested

Credit: Source link
Comments are closed.