Researchers Introduce ‘Colossal-AI’: A PyTorch-Based Deep Learning System For Large-Scale Parallel Training

Deep learning models are already revolutionizing the way we think about AI. One such type is the ‘transformer model,’ which takes an attention mechanism that differentiates between each part of input data with increased weighting given to those parts deemed most important – it’s used primarily in NLP and Computer Vision CV (1).
The larger model sizes that come with better performance significantly impact the memory wall of current accelerator hardware, such as GPU. Training large models such as the Vision Transformer, BERT, and GPT on a single GPU or machine can be arduous. AI researchers are constantly trying to find ways for their models to be used in a distributed environment. But distributed environments often require domain expertise in computer architecture and system design, which is challenging to acquire without experience or knowledge from working hands-on with these topics.
Researchers from HPC-AI Technology Inc. and the National University of Singapore (NUS) have introduced “Colossal-AI,” a PyTorch-based open-source system that makes distributed training in AI much more accessible for all.
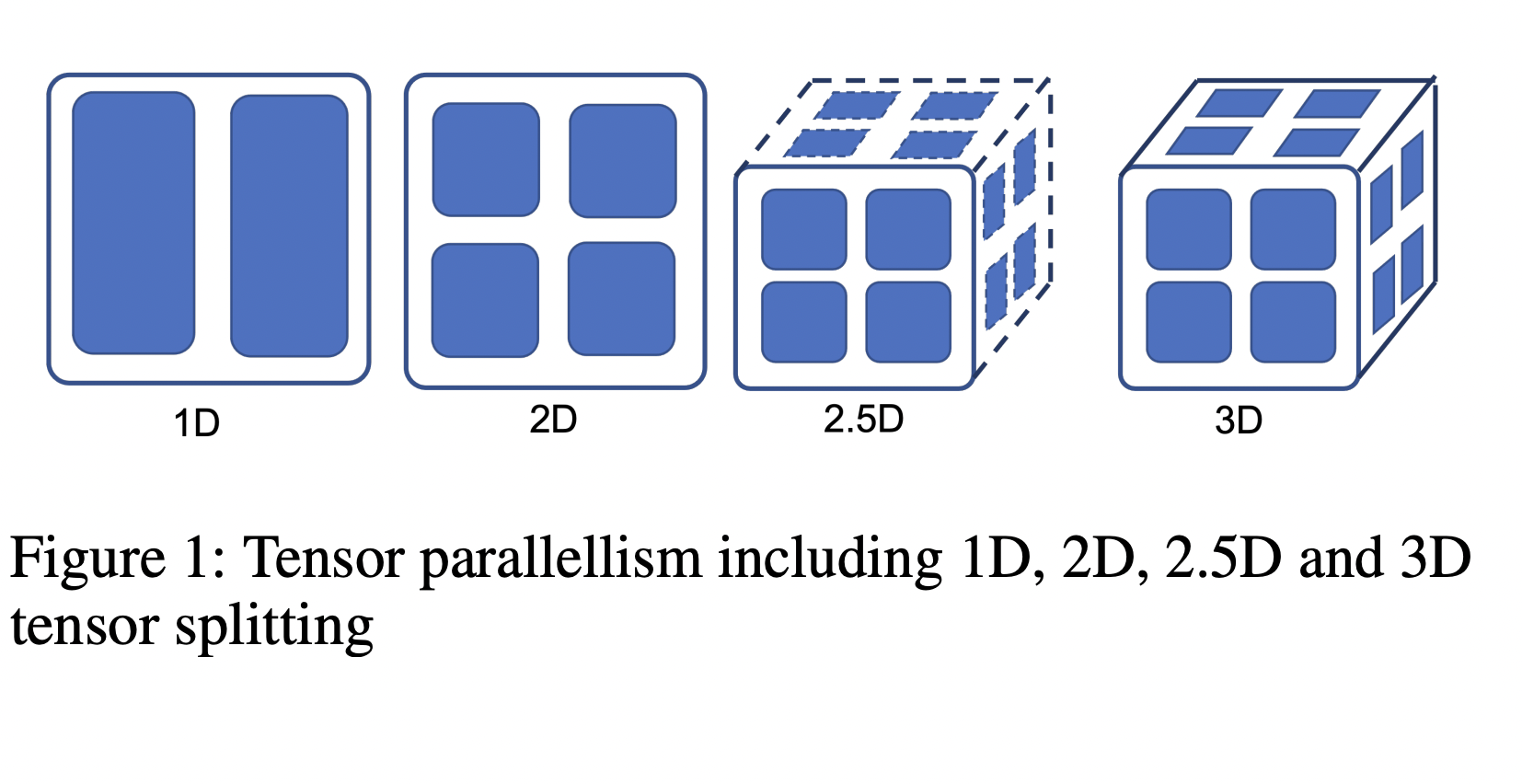
Colossal-AI allows users to set up combinations of data, pipeline, sequence, and multiple tensor parallelism. A user can use tensor parallelism to make a distributed model. This is just like how they make a single-GPU model. In this work, the researchers separated the model building from how it is distributed. They support many types of models, including 2D, 2.5D, and 3D tensor parallelism, sequence parallelism, and activation checkpointing.
The researchers have included methods like zero redundancy optimizer and offload by DeepSpeed and 1D tensor parallelism by Megatron-LM to make this system as good and robust as possible. In terms of Colossal-AI’s design, it is simple. Each part of the system does one specific thing. The parts all have a common interface for users to customize them. That way, when you need another feature in the future, it will be easy to add. One of the best features of this tensor parallelism technique is that it delivers superior memory efficiency. The current methods like Megatron do not fully remove all levels or redundancy when training, leading to slower processing speeds for models with higher accuracy rates.
To test the accuracy and efficiency of proposed algorithms, researchers conducted experiments on CIFAR10 dataset with Vision Transformer (ViT Tiny).

If you are a researcher or developer looking to easily scale your training on clusters and train with less time, fewer computing resources, then Colossal-AI may be the tool for you. This paper provides an overview of how it works as well as links to their Github codes so that others can use this software. We hope this article has been enlightening!
Paper: https://arxiv.org/pdf/2110.14883v1.pdf
Github: https://github.com/hpcaitech/colossalai
References:
- https://en.wikipedia.org/wiki/Transformer_(machine_learning_model)
Suggested
Credit: Source link
Comments are closed.