Researchers Introduce ‘Lensless’ Imaging Through Advanced Machine Learning For Next-Generation Image Sensing Solutions
This Article Is Based On The Research Article 'Lensless' imaging through advanced machine learning for next generation image sensing solutions'. All Credit For This Research Goes To The Researchers Of This Paper 👏👏👏 Please Don't Forget To Join Our ML Subreddit
A camera typically requires a lens system to capture a focused image, and the lensed camera has been the dominating imaging solution for millennia. A complicated lens system is necessary to get high-quality, bright, and aberration-free imaging with a lensed camera. In recent decades, the desire for smaller, lighter, and less expensive cameras has exploded. Next-generation cameras with high functionality that are small enough to be deployed anyplace are needed. However, the lens system and the focusing distance required by refractive lenses limit the lensed camera’s compactness.

The lensless camera has recently gained popularity. By substituting computing for various parts of the optical system, recent improvements in computing technology can simplify the lens system. Due to image reconstruction computers, the entire lens can be removed, resulting in a lensless camera that is ultra-thin, lightweight, and low-cost. However, the image reconstruction technique has yet to be perfected, resulting in poor imaging quality and a lengthy calculation time for the lensless camera.
Researchers recently devised a new image reconstruction method that reduces computing time while maintaining excellent image quality. A vital member of the research team says, “Without the restrictions of a lens, the lensless camera might be ultra-miniature, allowing novel uses that are beyond our imagination.”


The lensless camera’s conventional optical hardware comprises a thin mask and an image sensor. The mask and sensor can be produced combined in established semiconductor manufacturing techniques for future production. The mask optically encodes the incident light, which casts patterns on the sensor. Although the casted patterns are utterly incomprehensible to the naked eye, they can be decoded using explicit knowledge of the optical system. A mathematical procedure is then used to rebuild the image.
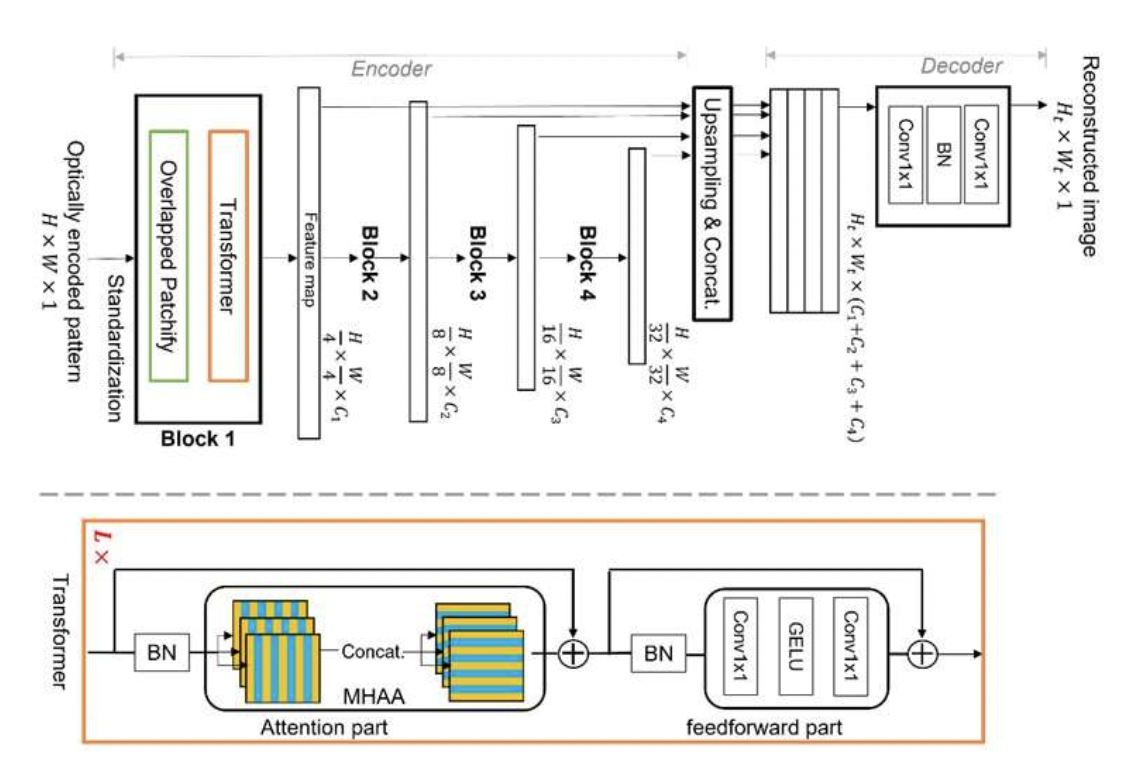
A lensless camera with a mask encodes the scene optically with a thin mask and reconstructs the image later. One of the most critical topics in lensless imaging is improving picture reconstruction. Traditional model-based reconstruction methods, which rely on physical system knowledge, are vulnerable to errors in system modeling. Reconstruction using a pure data-driven deep neural network (DNN) removes this constraint, potentially improving reconstruction quality. However, existing pure DNN reconstruction algorithms do not outperform model-based approaches for lensless imaging. In lensless optics, the multiplexing property makes global features critical for understanding the optically encoded pattern.
Furthermore, all available DNN reconstruction methods use convolutional networks (FCNs), which are inefficient global feature reasoning. This analysis proposes a fully connected neural network with a transformer for picture reconstruction for the first time. The proposed architecture improves the reconstruction by improving global feature reasoning. The suggested architecture’s superiority is demonstrated in an optical experiment by comparing it to model-based and FCN-based techniques.

The decoding technique, which is based on picture reconstruction technology, is still difficult. Traditional model-based decoding methods imitate the physical process of lensless optics by solving a “convex” optimization problem to reconstruct the image. This indicates that the reconstruction outcome is sensitive to the physical model’s faulty approximations. Model-based techniques use knowledge of the physical system to recreate the image. A precise pattern is cast on the sensor when using an ideal point light source to illuminate the mask-based lensless system. The point spread function (PSF) is a pattern determined by the physical system.
Furthermore, because the optimization problem needs iterative calculation, the computation required to solve it is time-consuming. Deep learning may overcome the drawbacks of model-based decoding by learning the model and decoding the image in a non-iterative direct approach. Existing convolutional neural networks (CNN)-based deep learning algorithms for lensless photography, on the other hand, are unable to produce high-quality images.
They are inefficient because CNN analyses images based on surrounding “local” pixel relationships. In contrast, lensless optics turn local information in the scene into overlapping “global” information on all image sensor pixels through a phenomenon known as “multiplexing.”
The Tokyo Tech research team is investigating this multiplexing property and has already suggested a revolutionary picture reconstruction machine learning technique. The proposed algorithm is based on Vision Transformer (ViT), a cutting-edge machine learning technique that excels at global feature reasoning. This enables it to learn image features in a hierarchical form efficiently. As a result, the suggested method may effectively handle the multiplexing property while also avoiding the drawbacks of traditional CNN-based deep learning, resulting in improved image reconstruction.
While iterative processing in traditional model-based methods takes a long time, the suggested way is faster since direct reconstruction is achievable with an iterative-free processing algorithm built via machine learning. As the machine learning system learns the physical model, the impact of model approximation errors is significantly decreased. Furthermore, the proposed ViT-based method uses global image features and can interpret casted patterns over a large region on the image sensor. In contrast, traditional machine learning-based decoding methods rely on CNN to understand local associations.

In summary, the suggested technique uses the ViT architecture to overcome the limits of traditional methods like iterative image reconstruction-based processing and CNN-based machine learning, allowing for the acquisition of high-quality images quickly. The research team also conducted optical experiments, which suggest that the lensless camera with the proposed reconstruction method can produce high-quality and visually appealing images. At the same time, the speed of post-processing computation is fast enough for real-time capture (as reported in their most recent publication).
Paper: https://opg.optica.org/ol/abstract.cfm?uri=ol-47-7-1843
Source: https://phys.org/news/2022-04-lensless-imaging-advanced-machine-image.html
Credit: Source link
Comments are closed.