Researchers Introduce ‘RANKGEN’: A Deep Encoder Model (1.2B Parameters) Which Maps Prefixes And Generations From Any Pretrained English Language Model To A Shared Vector Space
Language models (LM) are widely used to assign probabilities to the text. Current language models frequently give a high probability to the output sequences that are repetitious, nonsensical, or unrelated to the prefix given as an input sequence, thus resulting in the model-generated text containing such artifacts. To solve this problem, google researchers have proposed the RANKGEN, a 1.2 billion parameter encoder model. It translates both human-written and model-generated continuations of the prefixes to a common vector space RANKGEN that performs the dot product of the generations with the prefix and provides the rank to determine compatibility between a particular prefix and generations from any external LM.
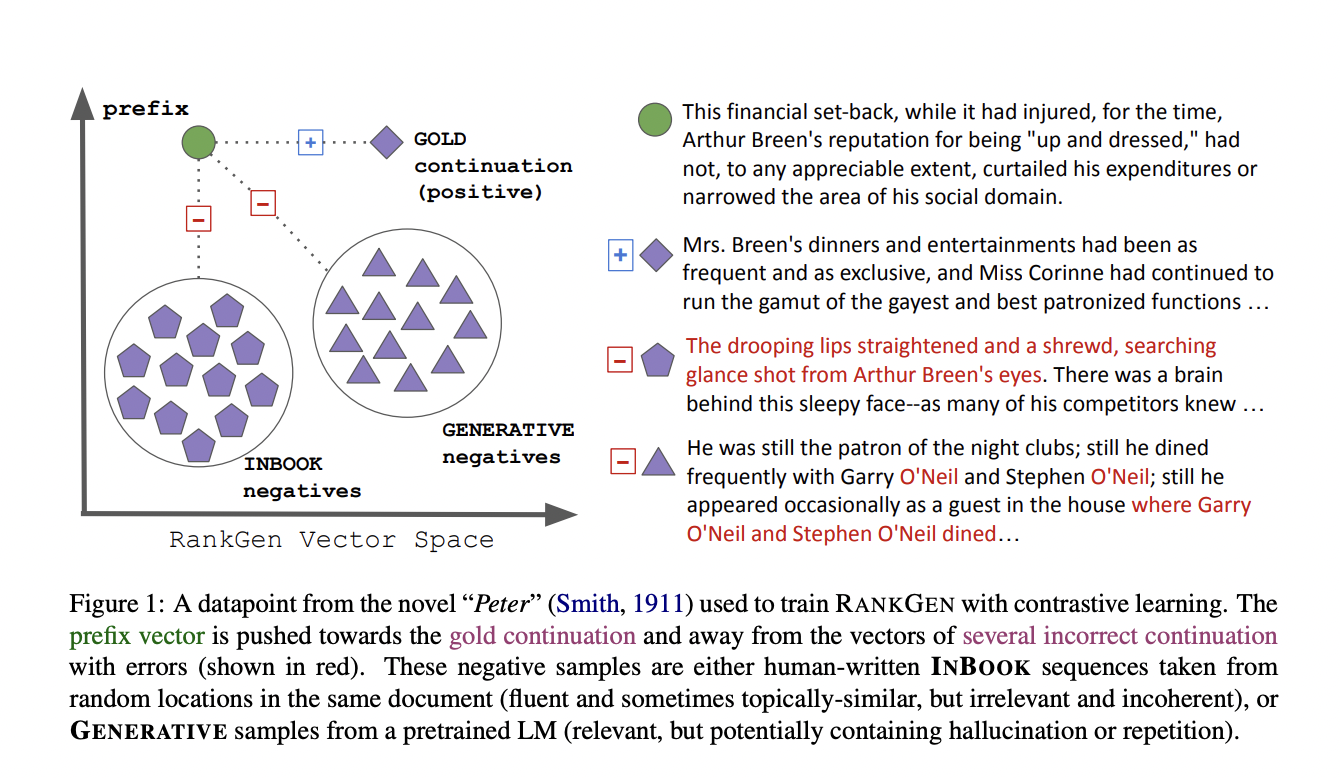
The significant contribution of the research is to utilize large-scale contrastive learning to train RANKGEN, which encourages prefixes to be closer to their gold continuation and to be far away from wrong negatives, as depicted in figure 1. The main goal is to forecast two sequences rather than a single token for prediction. Thus RANKGEN is inspired to intend long-distance associations between the prefix and continuation rather than depending on local context.
Figure 1 shows there are two strategies adopted for negative samples.
RANKGEN is a deep encoder network that uses a common vector space to protrude prefixes and generations. The two strategies, i.e., INBOOK negatives and GENERATIVE negatives, are adopted for selecting the negative samples. An input to the RANKGEN is the fixed size vectors, i.e., prefix, prefix’s ground-truth continuation, and LM-generated continuations. During the training phase, a contrastive goal drives the prefix vector towards the gold continuation vector while keeping it away from the generation vector and any other continuation vectors in a similar minibatch. Once the model is trained, the dot product of the RANKGEN vectors of a prefix and a candidate continuation represents their compatibility score.
To measure the performance of the proposed approach. MAUVE, an artificial text creation metric with an excellent correlation to human judgments, was used to compare RANKGEN variations and baseline decoding algorithms. RANKGEN exceeds nucleus and typical sampling by a wide margin. It also beats other re-ranking methods, such as those based on LM perplexity and unigram overlap. The greatest average MAUVE score of 85.0 is obtained by including RANKGEN in the beam search. Despite this, human assessment is done through blind A/B testing to check if individuals prefer RANKGEN-decoded continuations over nucleus-sampled continuations. From the results, it is depicted that people highly prefer RANKGEN outcomes to the nucleus sampling having 74.5 % fondness by majority vote, p < 0.001.
The analysis of the acquired results is performed to have an insight into the qualities of RANKGEN. To better understand human judgment, the annotators explain that the proposed approach provides the text with better continuity and flow with the prefix, fewer commonsense errors, and less repetition and contradiction. Compared to the time trade-off, RANKGEN takes a fraction more time than the state-of-art techniques.
Despite using the RANKGEN only for text generation, it can also be utilized as a retriever and for suffix identification. But still, it faces limitations compared to other decoding methods, i.e., the need for overgeneration. While RANKGEN is efficient by itself, producing numerous samples significantly increases decoding time. Furthermore, RANKGEN might be subject to adversarial instances, such as garbled writing that receives a high RANKGEN score due to white-box assaults.
RANKGEN, a deep encoder neural network, is proposed that provides scores for continuations given a prefix as an input, and it can easily integrate into the text generation system. It considerably outpaces state-of-art techniques for both automatic and manual evaluation. This research can be further extended to train large RANKGEN models (T5-XXL) with a larger length of prefix and suffix, discovering the other uses of RANKGEN like dialog generation, etc.
This Article is written as a summary article by Marktechpost Staff based on the paper 'RANKGEN: Improving Text Generation with Large Ranking Models'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper, github. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.