Researchers Introduce ‘SeMask’: An Effective Transformer-Framework That Incorporates Semantic Information Into The Encoder With The Help Of A Semantic Attention Operation
After demonstrating the transformer’s efficiency in the visual domain, the research community has focused on extending its use to several fields. One of these is semantic segmentation, a critical application for many areas, such as autonomous drive or medical diagnosis. The classical approach to this topic has been to use an existing pre-trained Transformer Layer as an encoder, tuning it for the segmentation task. However, this approach lacks insight into the semantic context during fine-tuning due to the relatively small dataset size compared to the one used for pre-training.
The Picsart AI Research team, together with the SHI Lab and IIT Roorkee, proposed the SeMask framework to incorporate semantic information into a generic hierarchical vision transformer architecture (such as Swin Transformer) through two techniques. First, a Semantic Layer is added after the Transformer Layer; second, two decoders are used: a lightweight semantic decoder used only for training and a feature decoder. The comparison of the existing methods general pipeline and SeMask is shown in the image below.

Architecture Overview
In SeMask, the RGB input of size H x W x 3 is first split into 4 x 4 patches (“patch partition” block in the image below). This initial tiny patch size allows precise prediction in segmentation. The patches are treated as tokens and passed to the encoder, which has a linear embedding layer in the first stage to change each token’s feature dimension. The encoding step is divided into four subsequent stages, each of them is named SeMask block and is comprised of two layers: the Transformer layer, with NA number of Swin Transformer blocks to extract image-level context information from the image, and the Semantic Layer with NS number of SeMask attention blocks to decouple semantic information from the features. In each stage, the resolution of the original image is subsequently squeezed from 1/4 to 1/32, while the channel dimension increases. The semantic layer takes as input the features from the Transformer layer and returns two outputs: the intermediate semantic-prior maps and the semantically masked features (this name will be justified later). The formers are aggregated using a lightweight upsample operation to predict the semantic-prior during training (the channel dimension K in the image is the number of classes), while the latter are aggregated using semantic FPN (Feature Pyramid Network), which fuses the features with convolution, up-sampling and sum operation to produce the final prediction. The loss function used is a sum of two per-pixel cross-entropy losses, where the one from the lightweight decoder is weighted by a factor set α = 0.4 to give more importance to the decoder used for final prediction.

A focus on the encoder
As already said, the two main components of the decoder are the Transformer and the Semantic layers. The transformer layer is composed of different shifted window attention blocks from the Swim Transformer, which was introduced by Microsoft and uses a shifting window mechanism to overcome the limitations of static patches of the original Vision Transformer.
The real innovation in this work is the semantic layer, which takes as input the output Y of the Transformer layer and aims to model the semantic context, which is used as a prior to calculating a segmentation score. This score is needed to update the feature maps based on indications of the semantic nature present in the image. The semantic layer divides the features Y into three entities: Semantic Query (Sq), Semantic Key (Sk), and Feature Value (Yv). Summarizing, Sq returns the semantic maps, and a segmentation score is calculated using Sk and Sq. The score is passed through a linear layer and multiplied with a learnable scalar λ used for smooth finetuning. After adding a residual connection, the modified features with semantic information are obtained, called semantically masked features. Plus, Sq is passed to the lightweight decoder to predict the semantic-prior map. Below, a graphical representation of this procedure is shown.

Results
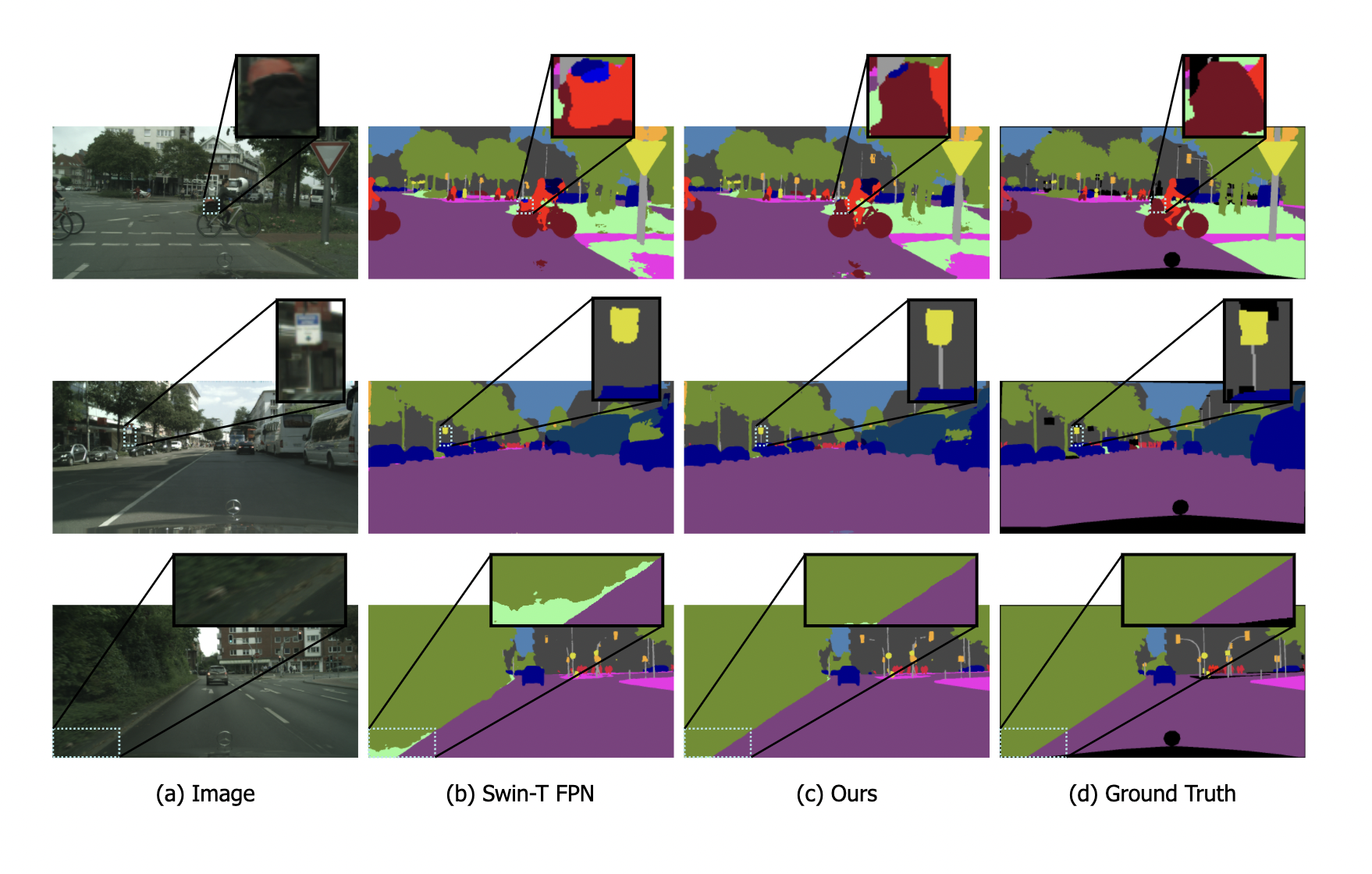
The authors validated this approach in terms of mIoU (mean intersection over unit) on two different and widely used datasets, ADE20K and Cityscapes, obtaining a new state-of-the-art of 58.22% mIoU on the ADE20K dataset and improvements of over 3% in the mIoU metric on the Cityscapes dataset. Some qualitative results are also shown below.

Conclusion
The problem addressed in this paper is that the direct tuning of pretrained transformer backbone networks as encoders for semantic segmentation does not consider the semantic context in images. To solve this issue, the author proposed the SeMask block, which uses a semantic attention operation to capture the semantic context and augment the semantic representation of the feature maps. This idea was demonstrated to be very efficient on the Cityscapes and ADE20K dataset, and, as the authors themselves pointed out at the end of the paper, it will be interesting to observe the effect of adding similar priors for other downstream vision tasks like object detection and instance segmentation.
Paper: https://arxiv.org/abs/2112.12782
Github: https://github.com/Picsart-AI-Research/SeMask-Segmentation
Suggested

Credit: Source link
Comments are closed.