Researchers Open-Source WiSE-FT Algorithm For Fine Tuning AI Models
This research summary article is based on the paper 'Robust fine-tuning of zero-shot models'
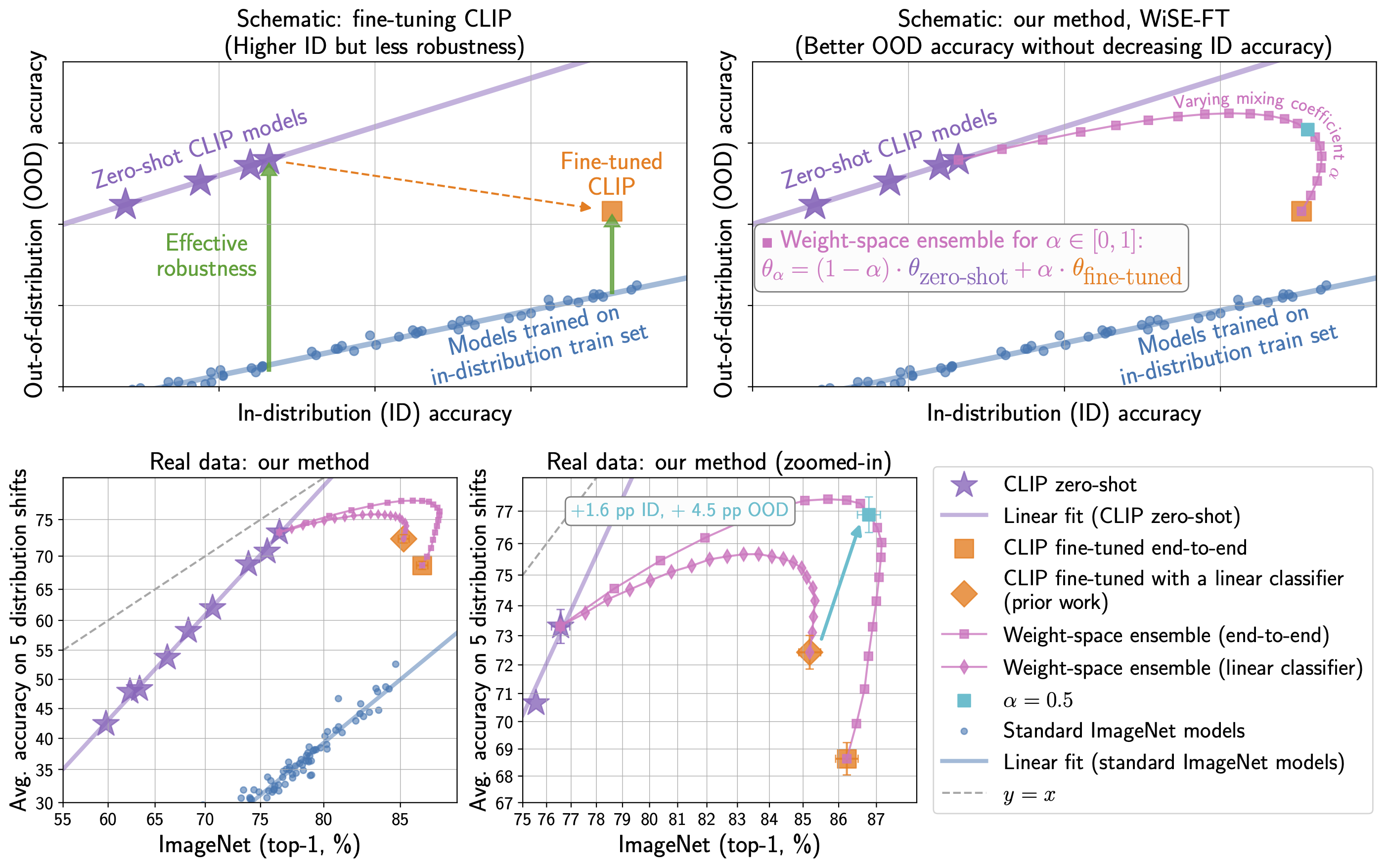
When making zero-shot inference, large pre-trained models like CLIP or ALIGN provide consistent accuracy across various data distributions (i.e., without fine-tuning on a specific dataset). While existing fine-tuning methods vastly improve accuracy on a given target distribution, they frequently compromise robustness to distribution shifts. This conflict can be resolved by presenting a simple and effective strategy for enhancing robustness while fine-tuning: assembling the zero-shot and fine-tuned models (WiSE-FT).
An approach for fine-tuning AI models that enhance robustness during distribution shift has been open-sourced by researchers from the University of Washington (UW), Google Brain, and Columbia University. According to tests, WISE-FT improves accuracy by up to 6% on specific computer vision (CV) benchmarks.
WiSE-FT increases accuracy during distribution shift compared to ordinary fine-tuning while maintaining excellent precision on the target distribution. WiSE-FT improves accuracy under distribution shift by 4 to 6 percentage points (pp) over previous work on ImageNet and five derived distribution shifts while boosting ImageNet accuracy by 1.6 pp.
On a diverse collection of six more distribution shifts, WiSE-FT produces similarly high robustness benefits (2 to 23 pp) and accuracy advantages of 0.8 to 3.3 pp compared to ordinary fine-tuning on seven regularly used transfer learning datasets. During fine-tuning or inference, these benefits come at no additional processing cost.
The WiSE-FT algorithm combines the weights of a fine-tuned model with the consequences of the original model. The resulting ensemble model has improved accuracy when the input data patterns diverge from the training data while maintaining high accuracy on in-distribution data. A CLIP-based image classifier fine-tuned using WiSE-FT outperformed other strong models in experiments utilizing shifted copies of the ImageNet benchmark dataset.
Because building deep learning models from scratch involves enormous datasets and a lot of computing power, many developers are starting to use pre-trained models like CLIP or GPT-3. While these models can be utilized in a zero-shot/few-shot context, requiring no updates to the model weights, they are frequently fine-tuned by using a task-specific dataset to perform further training updates to the model weights.

However, this can sometimes result in a final model that performs well on in-distribution data but poorly on out-of-distribution data or data with statistics that differ from the training data.
The team looked into ways to improve the durability of fine-tuned models because this distribution shift occurs regularly in a production scenario. The resulting process is a linear interpolation of the weights of the original and fine-tuned models, which may be implemented “in a few lines of PyTorch.” A mixing coefficient can give one of the two a more significant influence on the final output. Still, the researchers found that a neutral mixture “yields near to optimal performance” in various studies.
WiSE-FT does not require additional computing during the fine-tuning or inference processes and the robustness benefits. ImageNet-V2, ImageNet-R, ImageNet Sketch, ObjectNet, and ImageNet-A were used to fine-tune the model, tested on five distinct distribution-shifted datasets produced from ImageNet. On both the reference ImageNet test data and the shifted datasets, the final model beat earlier fine-tuned CLIP classifiers using WiSE-FT.
Ensembling standard models (in output-space) with a robust model significantly improves their resilience. When two non-robust models are combined, there are no advances in inadequate robustness.
Compared to ordinary fine-tuning, WiSE-FT can significantly enhance performance under distribution shift with minimal or no loss of accuracy on the target distribution. WiSE-FT is the first step toward more advanced fine-tuning strategies. Future work expects to continue using the stability of zero-shot models to develop more dependable neural networks.
Object detection, fine-tuning and natural language processing are two promising areas for future research. Furthermore, while the interpolation parameter choice of 0.5 provides good overall performance, determining the best value for various target distributions is left to future research.
Paper: https://arxiv.org/pdf/2109.01903.pdf
Github: https://github.com/mlfoundations/wise-ft
Suggested
Credit: Source link
Comments are closed.