Researchers propose ‘DualNets,’ a novel general continual learning framework comprising a fast learning and a slow learning system
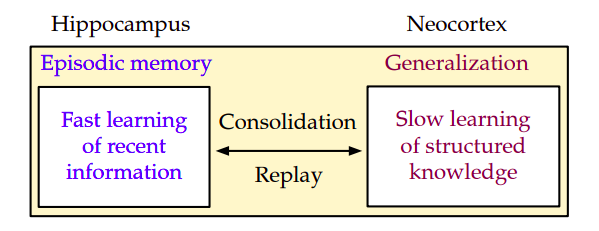
Humans have a unique ability to learn and retain knowledge throughout their lives in order to execute various cognitive tasks. Surprisingly, such talent is related to complicated connections across several interconnected brain areas. The Complementary Learning Systems (CLS) theory proposes that the brain may achieve such behaviors through two learning systems, the “hippocampus” and the “neocortex,” with the hippocampus focusing on quick learning of pattern-separated representations of specific events. The two learning systems, rapid and slow, continually interact to promote quick learning and long-term memory. Memory consolidation transfers memories from the hippocampus to the neocortex over time to build a more generic representation that enables long-term retention and generalization to new events.
The figure above depicts this rapid and slow learning paradigm. Although deep neural networks have produced excellent results in various applications, they frequently necessitate access to vast data. Even after that, they perform poorly when learning on data streams; furthermore, in the continuous learning scenario, when the stream contains input from several distributions, deep neural networks catastrophically forget previous information, further impairing overall performance. As a result, the primary goal of this research is to investigate how the CLS theory might inspire a generic continual learning framework that provides a better trade-off between preventing catastrophic forgetting and promoting information transfer.
Several continuous learning techniques are influenced by CLS theory in the literature, ranging from leveraging episodic memory to enhancing representation. However, most of these systems employ a single backbone to mimic the hippocampus and the neocortex, combining two representation types into a single network. They cannot ensure the separation of generic and task-specific representations. Furthermore, because such networks are trained to minimize solely supervised loss, they lack a distinct slow learning component that permits a generic representation.
The representation created by continuously executing supervised learning on a short quantity of memory data during constant learning can be prone to overfitting and may not transfer well across tasks. On the opposite hand, Recent research in continuous learning reveals that unsupervised representation is frequently more resistant to forgetting than supervised representation, which provides only minor advances. This conclusion encourages us to develop a unique fast-and-slow learning framework for continuous learning, consisting of two different learning systems. The rapid learner prioritizes supervised learning, whereas the slow learner prioritizes collecting better representations.
They present DualNets (for Dual Networks), an innovative and practical continual learning paradigm comprised of two independent learning systems based on the fast-and-slow learning framework. DualNets, in particular, comprise two complementary and concurrent training processes. First, only the slow network is used in the representation learning phase, which constantly improves a Self-Supervised Learning (SSL) loss to model generic, task-agnostic features. Consequently, the fast learner can use the slow representation to learn new tasks more efficiently while retaining information from previous activities. DualNets may constantly improve representation even when there are no labeled samples, which is common in real-world deployment circumstances when labeled data is delayed or even limited.
Second, and concurrently, both learners are involved in the supervised learning phase. This phase aims to train the fast learner, a lighter model that can effectively perform supervised learning on data streams. They also offer a simple feature adaption strategy to guarantee that the fast learner incorporates the slow representations into its predictions, resulting in good outcomes. The figure below displays a high-level overview of their DualNets. Finally, by design, the original DualNet employs all sluggish characteristics to learn the current sample. They should highlight that this method may degrade performance when the continuum (data stream) comprises unrelated activities. A negative transfer between jobs may result in a performance loss when all sluggish features are used.
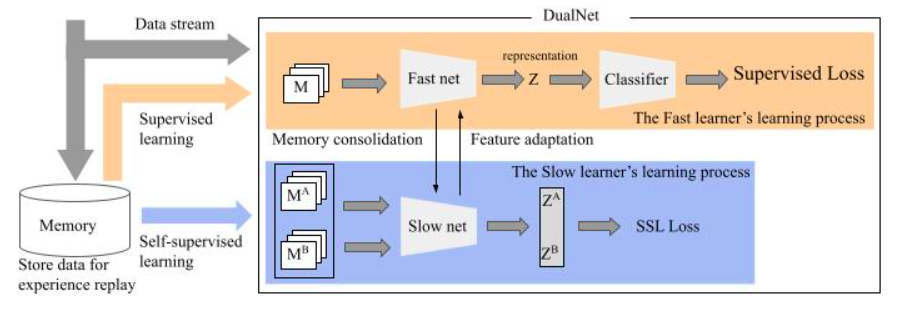
To that aim, they present DualNet++, which provides DualNet with a basic but elegant regularisation technique to mitigate negative knowledge transfer in continuous learning. DualNet++, in particular, adds a dropout layer between the interaction of fast and slow learners, preventing the fast learner from coadapting to the slow features. As a result, DualNet++ is resistant to negative information transfer in the presence of unrelated or conflicting activities during continuous learning. DualNet++ performs well on the CTrL benchmark, which was expressly developed to assess the model’s capacity to transfer knowledge in many difficult circumstances.
In summary, their study provides the following contributions:
1) They present DualNet, a unique and generalized continual learning framework informed by CLS theory, consisting of two main components of fast and slow learning systems.
2) They create realistic DualNet and DualNet++ algorithms that implement fast and slow learning techniques for continuous learning. DualNet++ is also resistant to negative information transfer.
3) Extensive trials are carried out to illustrate DualNet’s competitive performance compared to state-of-the-art (SOTA) approaches. They also present detailed analyses of DualNet’s effectiveness, resilience to slow learner objectives, and computing resource scalability.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Continual Learning, Fast and Slow'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and github link. Please Don't Forget To Join Our ML Subreddit
![]()
Content Writing Consultant Intern at Marktechpost.
Credit: Source link
Comments are closed.