Researchers Propose ‘ProxyFL’: A Novel Decentralized Federated Learning Scheme For Multi-Institutional Collaborations Without Sacrificing Data Privacy

Tight rules generally govern data sharing in highly regulated industries like finance and healthcare. Federated learning is a distributed learning system that allows multi-institutional collaborations on decentralized data while also protecting the data privacy of each collaborator. Institutions in these disciplines are unable to aggregate and communicate their data, limiting research and model development progress. More robust and accurate models would result from sharing information between institutions while maintaining individual data privacy.
For example, in the healthcare industry, histopathology has undergone increasing digitization, providing a unique opportunity to improve the objectivity and accuracy of diagnostic interpretations through machine learning. The preparation, fixation, and staining techniques utilized at the preparation site, among other things, cause significant variation in digital photographs of tissue specimens.
Because of this diversity, medical data must be integrated across numerous organizations. On the other hand, medical data centralization involves regulatory constraints as well as workflow and technical challenges, such as managing and distributing the data. Because each histopathology image is often a gigapixel file, often one or more gigabytes in size, the latter is very important in digital pathology.
Researchers from Layer 6 AI, the University of Waterloo, and Vector Institute recently investigated the context of multi-institutional collaboration in highly regulated areas. They developed a strategy for decentralized model training that respects data privacy in a recent study. Distributed machine learning on decentralized data could be a way to address these issues and increase machine learning adoption in healthcare and other highly regulated industries.
Federated learning (FL) is a distributed learning framework that was created to train a model using non-centralized data. It trains a model on client devices directly where data is created, with gradient updates transmitted back to the centralized server for aggregate. However, because it includes a centralized third party controlling a single model, the canonical FL arrangement is unsuitable for multi-institutional collaboration. When considering hospital collaboration, creating a single central model may be undesirable. Each hospital may desire autonomy over its own regulatory compliance and specialty-specific approach.
While it is sometimes claimed that FL improves privacy by ensuring that raw data never leaves the client’s device, it does not provide the level of security required by regulated organizations.
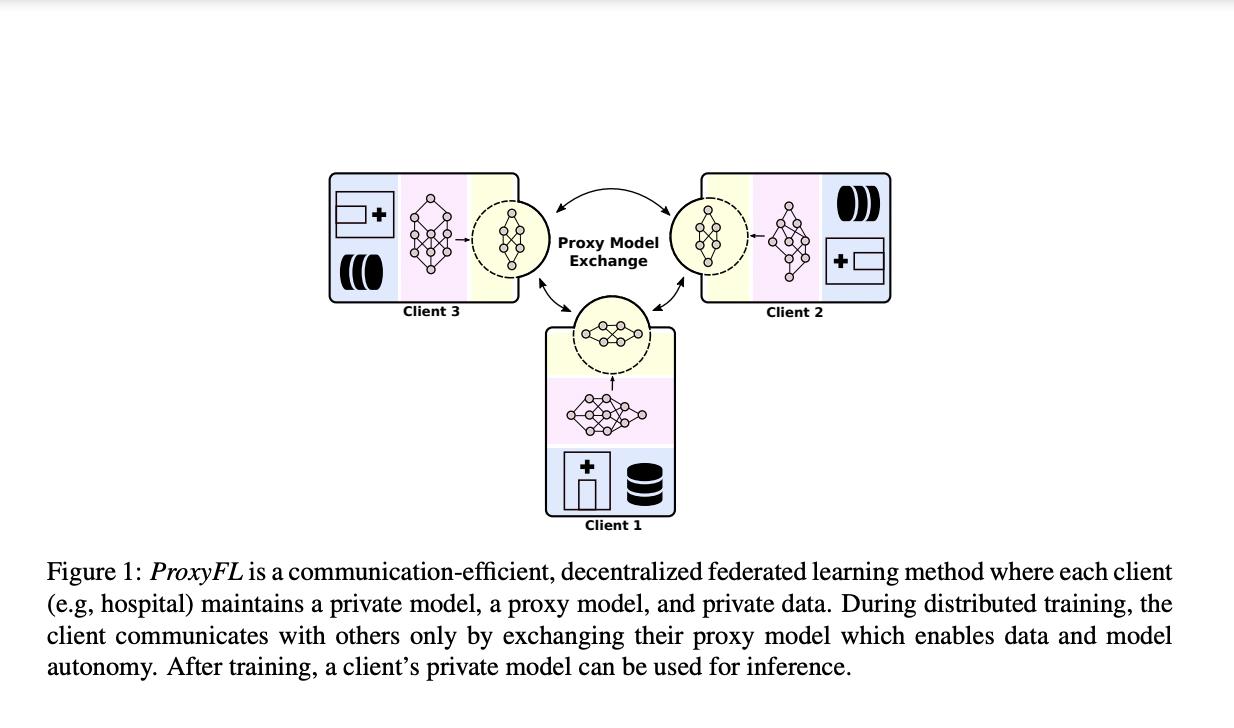
Proxy-based federated learning, or ProxyFL, is a decentralized collaboration between institutions that allows for the training of high-performance and robust models without losing data privacy or communication efficiency, according to researchers from the University of Waterloo. They have contributed a method for decentralized FL in multi-institutional collaborations that are adapted to heterogeneous data sources and preserves model autonomy for each participant, as well as the incorporation of DP for rigorous privacy guarantees analysis and the reduction of communication overhead.
The team found many significant issues. Clients may not wish to share the structure and parameters of their private model with others. Disclosing model structure exposes confidential information, increases the danger of adversarial assaults, and exposes private data about local datasets. In addition to model heterogeneity, clients may not wish to entrust the management of a shared model to a third party, preventing centralized model averaging approaches. Information sharing must also be efficient, robust, and peer-to-peer.
To overcome the issues mentioned above, the team adds an additional proxy model with specific settings for each client. It acts as a link between the client and the rest of the world. For compatibility, all clients agree on a standard proxy model architecture as part of the communication protocol. Each client trains its private and proxy models together in each round of ProxyFL so that they can benefit from one another.
The proxy can extract meaningful information from private data through differentially personal training, which can then be shared with other customers without breaking privacy limitations. Then, according to a communication network defined by an adjacency matrix and de-biasing weights, each client transmits its proxy to its out-neighbors and receives new proxies from its in-neighbors. Finally, each client collects all of the proxies they’ve received and changes their existing proxy.
Because the proxy model is the only entity that a client discloses, each client must verify that this sharing does not jeopardize their data’s privacy. Because arbitrary post-processing on a DP-mechanism does not compromise its guarantee, the proxy can be released as long as it was trained using one. On a client-by-client basis, privacy guarantees are tracked. Every customer in a multi-institutional partnership has a responsibility to ensure the privacy of the data it has gathered. As a result, each client keeps track of the parameters for its own proxy model training and can opt-out of the protocol once its privacy budget has been met.
When each approach was trained on a multi-origin real-world dataset, namely The Cancer Genome Atlas, the sub-type classification results for internal and external data under two different DP settings (strong and weak privacy) were reported (TCGA). ProxyFL, FML, and FedAvg were the three FL approaches that were compared.
On the internal test data, ProxyFL outperforms FML and FedAvg in terms of overall accuracy for both privacy settings. All three approaches perform similarly on external test data, with FedAvg marginally ahead when implementing stricter privacy guarantees. Because of the smaller variance in both privacy settings, ProxyFL has considerably better convergence than FML. The FedAvg central model demonstrates no increase in performance when high privacy is implemented across both test datasets. Because they exchange lightweight proxy models rather than larger private models, both ProxyFL and FML are more communication efficient than FedAvg. Still, ProxyFL has the lowest communication overhead due to fewer model exchanges.
Conclusion
ProxyFL protects data and model privacy while facilitating distributed training through a decentralized and communication-efficient method. Experiments show that ProxyFL is competitive in terms of model correctness, communication efficiency, and privacy preservation when compared to alternative baselines. Furthermore, the method was tested in a real-world scenario with four medical institutions working together to train pan-cancer classification models. Some FL approaches for private knowledge transfer, unlike ProxyFL, require a public dataset. This distinction is crucial because large-scale public datasets are not readily available in highly controlled domains. Access to a publicly available dataset broadens the range of approaches that may be applied and opens up new avenues for future research.
Paper: https://arxiv.org/pdf/2111.11343v1.pdf
Github: https://github.com/layer6ai-labs/ProxyFL
Suggested
Credit: Source link
Comments are closed.