Researchers @ SenseTime Develop GNR: Generalizable Neural Performer for Human Novel View Synthesis
This Article Is Based On The Research Paper 'Generalizable Neural Performer: Learning Robust Radiance Fields for Human Novel View Synthesis'. All Credit For This Research Goes To The Researchers Of This Paper 👏👏👏 Please Don't Forget To Join Our ML Subreddit
Filmmaking, 3D immersive communication, and AR/VR gaming all benefit from the ability to synthesize free-viewpoint images of human actors. The most remarkable industry-level rendering outcomes, on the other hand, now necessitate both specialized studio conditions and time-consuming artistic design for each human subject.
In the topic of enhancing the generalization and robustness of free-viewpoint synthesis for arbitrary human performers from a sparse set of multi-view photos, a lot of work is being done. Major obstacles must be overcome in order to do this, as generating high-quality results necessitates the preservation of visual detail as well as multi-view uniformity.
Many prior pioneer works have failed to achieve these objectives. There have been attempts that either relies on the deployment of depth sensors for high-quality geometry reconstruction before rendering or on the development of dense camera arrays to capture the changing appearances from various viewing angles. The need for professional equipment restricts the use of such technologies in personal and everyday situations.

It’s a recent advancement in the industry to use neural networks to learn 3D geometry and appearance from data. Image integrity and reconstruction accuracy have both improved significantly thanks to implicit neural representations. Despite the significant technological advancements, these systems still suffer from case-specific optimization, pose generalization, and unrealistic rendering.
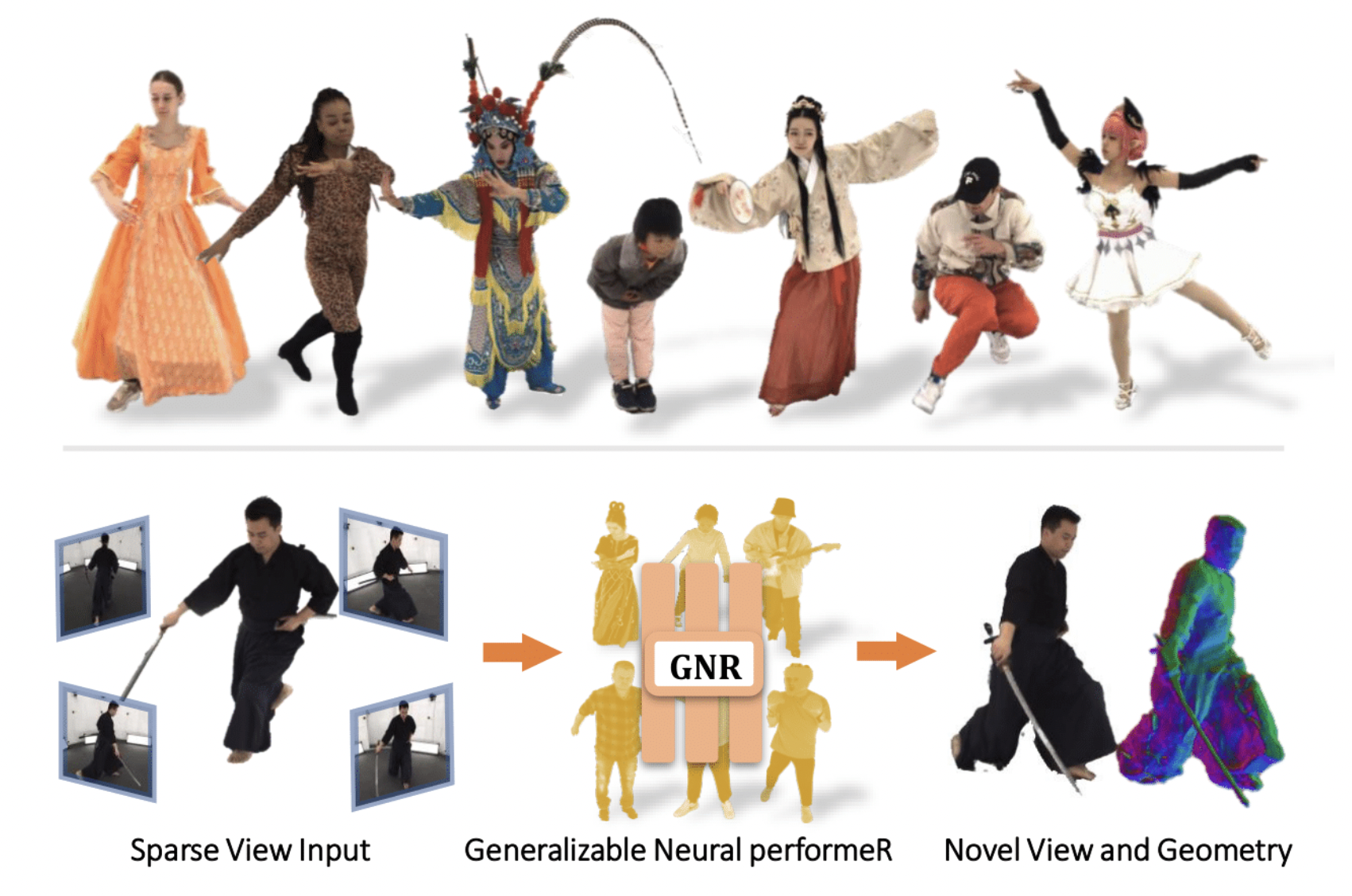
SenseTime researchers proposed Generalizable Neural PerformeR(GNR), a revolutionary framework that learns a generalizable and robust neural body representation of varied human positions, forms, and appearances, to meet the issues. In neural radiance fields learning, the team achieves this with numerous effective designs on body structural and source-view appearance conditions.
By adopting a Geometric Body Embedding technique, which extracts geometric information and body semantics from both parametric 3D human body models and multi-view source picture feature fusion, the model may represent arbitrary human performers in a single model without per-case finetuning.
The researchers proposed the Screen-Space Occlusion-Aware Appearance Blending (SSOA-AB) technique for reliably providing a faithful appearance. The main feature of this concept is to extract texture information from source views. Because the texture from source views provides authentic details, the pixel from these views might be used as a firsthand base reference color to correct the neural radiance field’s incorrect color prediction.
After conducting extensive tests on human performance datasets, the team concluded that GNR delivers the best performance rendering unique perspectives without any further unseen human finetuning. GNR delivers excellent geometry reconstruction results and beats all other approaches in terms of rendering quality. Despite the fact that other radiance-based approaches usually result in a noisy object surface, GNR suffers from the contribution of body form embedding far less.
Conclusion
Due to the differences in human subjects, creating free-viewpoint videos using a general model is a severely ill-posed task. GNR is a revolutionary method presented by SenseTime researchers. GNR successfully tailors prior knowledge of a parametric model and source photos, allowing for reliable and effective human geometry and appearance estimates. On several human datasets, qualitative and quantitative results confirm its state-of-the-art performance.
Paper: https://generalizable-neural-performer.github.io/static/gnr.pdf
Github: https://github.com/generalizable-neural-performer/gnr
Project: https://generalizable-neural-performer.github.io/genebody.html
Credit: Source link
Comments are closed.