Revolutionizing AI Efficiency: Meta AI’s New Approach, READ, Cuts Memory Consumption by 56% and GPU Use by 84%
Multiple Natural Language Processing (NLP) tasks have been completed using a large-scale transformers architecture with state-of-the-art outcomes. Large-scale models are typically pre-trained on generic web-scale data and then fine-tuned to specific downstream goals. Multiple gains, including better model prediction performance and sample efficiency, have been associated with increasing the size of these models. However, the cost of fine-tuning these models is now out of reach for most people. Since 2018, the cost of advancing AI technology has been unfeasible due to the exponential growth of model size relative to GPU memory.
To overcome the difficulties of fine-tuning all the parameters, parameter-efficient transfer learning (PETL) has emerged as a viable option. Parameter-efficient transfer learning techniques try to efficiently adjust the pre-trained model’s parameters to the target task by utilizing smaller and more task-specific models. These approaches, however, either increase inference delay or save a negligible amount of memory during training.
A new Meta AI study addresses these issues by introducing REcurrent ADaption (READ).
READ adds a small recurrent neural network (RNN) to the backbone model and a “joiner” network that combines information from numerous sources to provide inputs for the RNN to overcome PETL’s constraints. It requires few parameters and a minimal amount of memory.
Before using READ, the method performs a forward pass through the transformer backbone, where intermediate results are cached at each transformer layer. RNN hidden states are then iteratively calculated at the encoder and decoder stages. The new final state is computed by summing the outputs of the RNN and the backbone.
Since READ is recurrent, the trainable parameters will not grow larger with deeper backbone layers, resulting in lower processing requirements. As a result, the suggested fine-tuning procedure relies solely on RNNs and feed-forward networks (FFNs) rather than an attention mechanism. By omitting pretraining and pruning, usability and training efficiency are both enhanced.
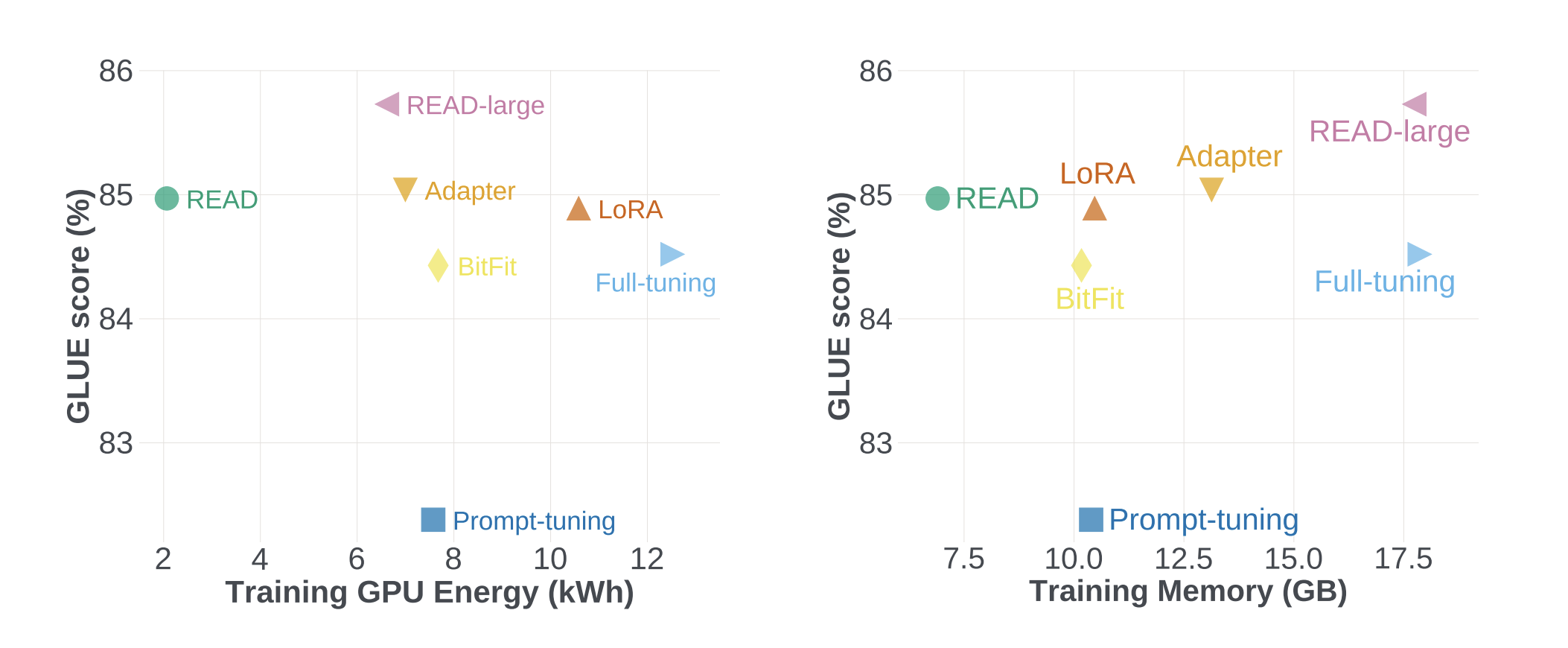
The researchers compare READ to baseline PETL methods, including BitFit, Prompt-tuning, LoRA on the GLUE and other multiple natural language processing benchmarks, and full-tuning approaches. READ outperforms various fine-tuning methods on the GLUE benchmark in terms of accuracy while also decreasing model training memory consumption by 56% and GPU energy usage by 84% compared to full-tuning. The results also suggest that READ is a backbone-size-agnostic, highly scalable approach for fine-tuning massive transformers.
As mentioned in their paper, the team could not expand the backbone due to constraints on their processing power. The researchers plan to fine-tune further READ on Llama-7B and possibly larger variations in the future. According to researchers, one of READ’s drawbacks is that it often takes more epochs than competing PETL algorithms to converge on small datasets. This means that when there are few data points to work with, even while READ is more efficient in per-unit-time computations, it may deliver little total consumption gains. They plan to investigate READ on the low-data regime. The team believes READ will open up the process of fine-tuning huge models to a wider audience of scientists and developers.
Check out the Paper. Don’t forget to join our 22k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.