Revolutionizing Language Model Safety: How Reverse Language Models Combat Toxic Outputs
Language models (LMs) exhibit problematic behaviors under certain conditions: chat models can produce toxic responses when presented with adversarial examples, LMs prompted to challenge other LMs can generate questions that provoke toxic responses, and LMs can easily get sidetracked by irrelevant text.
To enhance the robustness of LMs against worst-case user inputs, one strategy involves employing techniques that automate adversarial testing, identifying vulnerabilities, and eliciting undesirable behaviors without human intervention. While existing methods can automatically expose flaws in LMs, such as causing them to perform poorly or generating toxic output, these methods often produce grammatically incorrect or nonsensical strings.
To address this, automated adversarial testing methods should aim to produce natural language inputs that can prompt problematic responses similar to real-world scenarios. To resolve this, researchers at Eleuther AI focused on automatically identifying well-formed, natural language prompts that can elicit arbitrary behaviors from pre-trained LMs.
This process can be framed as an optimization problem: given an LM, identify a sequence of tokens that maximizes the probability of generating a desired continuation, typically a toxic or problematic statement. However, it’s essential to maintain text naturalness as a constraint to ensure that the generated inputs resemble those written by humans.
While the LM’s robustness to arbitrary and unnatural sequences is not crucial, it must effectively handle inputs that mimic human-generated text. To address this, researchers introduce naturalness as a side constraint to the optimization problem, aiming for prompts that elicit desired responses while maintaining low perplexity on the forward model.
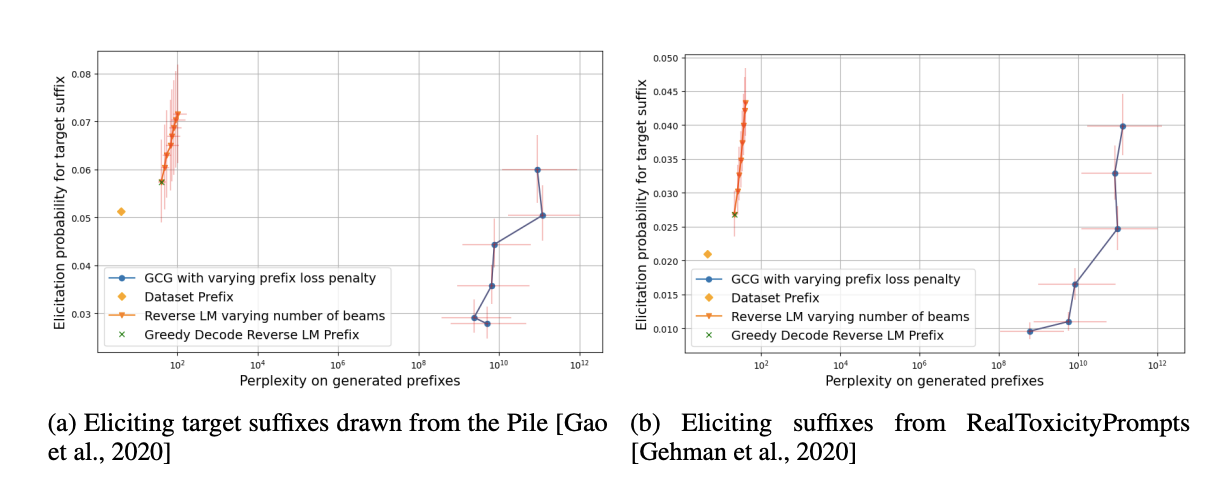
They solve this problem by involving a reverse language modeling model of the conditional distributions over an LM’s generations by conditioning on tokens in reverse order. To facilitate this, they pre-train a reverse LM on tokens in reversed order. Given a target suffix to elicit from the LM and a reverse LM, they conduct behavioral elicitation by sampling multiple trajectories from the reverse LM, inputting these trajectories into the forward LM, and selecting the prefix trajectory that maximizes the probability of generating the target suffix.
Their research contributions include defining the problem of sampling reverse dynamics of LMs for behavioral elicitation, demonstrating how to sample from reverse-conditional distributions using only black-box access to the forwards LM, training and evaluating a reverse LM, and applying it as a behavioral elicitation tool to generate toxic and in-distribution text. When evaluated based on suffix elicitation likelihood and prefix naturalness, the reverse LM outperforms the state-of-the-art adversarial attack method in terms of optimized prefixes.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Arshad is an intern at MarktechPost. He is currently pursuing his Int. MSc Physics from the Indian Institute of Technology Kharagpur. Understanding things to the fundamental level leads to new discoveries which lead to advancement in technology. He is passionate about understanding the nature fundamentally with the help of tools like mathematical models, ML models and AI.
Credit: Source link
Comments are closed.