Revolutionizing Mathematical Problem Solving: OpenAI’s Innovative Approach Leveraging Process Supervision Over Outcome Supervision
Recent years have seen massive advancements in the capability of massive language models to carry out complicated multi-step reasoning. Modern models, despite their sophistication, continue to make senseless errors. Two types of supervision can be used to train more accurate models: outcome supervision, which provides feedback on the ultimate result, and process supervision, which provides feedback on each intermediate stage in the reasoning process. Aligned artificial general intelligence (AGI) requires that hallucinations be reduced. Such hallucinations might prove disastrous in fields where complex problems necessitate multiple lines of reasoning. Improving one’s ability to reason depends on recognizing and controlling hallucinations.
One such strategy is training reward models to distinguish between good and bad results. The reward model can subsequently be integrated into an RL pipeline or utilized for an RS search. While effective, the resulting system relies on the accuracy of the reward model to function.
OpenAI uses a technique called Process Supervision for its training. Process supervision allows the model to follow human-approved associations, while Outcome Supervision only rewards the correctness of the final result. The outcomes of Chain-of-Thought thinking are more trustworthy.
Process oversight has a lot going for it. It gives more specific responses since it pinpoints where problems have occurred. It also has various benefits related to AI alignment, including being simpler for people to understand and providing more direct rewards to models that adhere to a line of reasoning approved by humans. In contrast to process-supervised reward models (PRMs), which get feedback at each stage of the model’s reasoning process, outcome-supervised reward models (ORMs) are trained using only the ultimate result of the model’s reasoning process. Models trained using outcome supervision frequently exploit fallacious reasoning within logical reasoning to arrive at the correct final result. It has been demonstrated that process oversight can reduce this mismatched conduct.
Uesato discovered that, despite these benefits, outcome, and process supervision led to a similar ultimate performance in elementary mathematics. The in-depth evaluation of result versus process supervision differs primarily in three ways:
- Train and test on the more difficult MATH dataset.
- Employ a more capable base model.
- Use substantially more human feedback.
Here are some of the most significant contributions made by researchers:
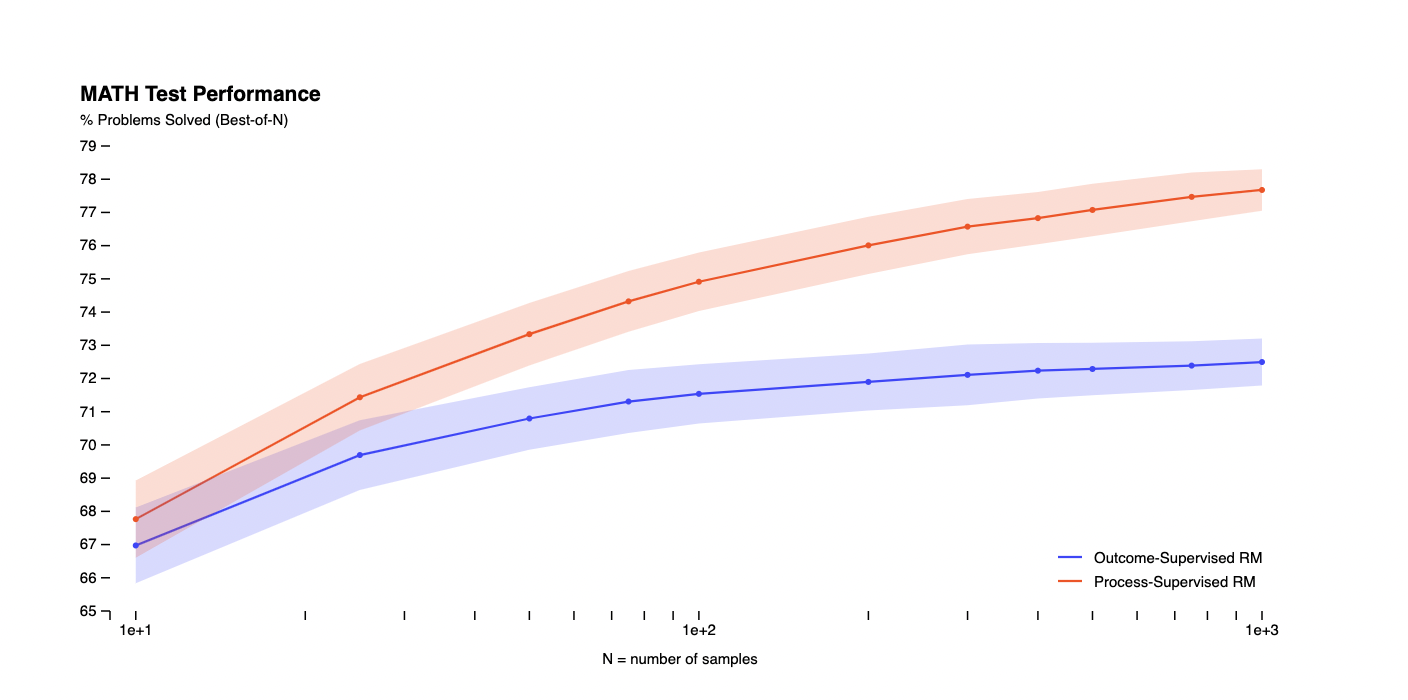
Researchers find process supervision can provide more trustworthy reward models during training than outcome supervision. The state-of-the-art PRM can solve 78.2% of a sample of problems from the MATH test set.
They demonstrate the ability of a big reward model to effectively execute large-scale data collection ablations and to successfully imitate human supervision for smaller reward models.
They also show that the data efficiency of process supervision is increased by 2.6 times due to active learning.
To encourage further study in this area, researchers are making the entire PRM800K process supervision dataset available.
Following a similar methodology as Uesato, researchers analyze the differences between outcome and process supervision. Human-free outcome supervision is possible since all the solutions to the questions in the MATH dataset can be checked automatically. Process oversight, on the other hand, cannot be easily automated.
Management based on output vs. input
The basic approach is similar, but there are three key distinctions. Researchers begin by collecting the PRM800K dataset and running the massive tests using a more powerful model. Both outcome and process supervision resulted in roughly the same error rates for the final solution, but process supervision did so with fewer observations. Consistent with Uesato’s findings, the resulting performance is equivalent even when both the process and outcome are heavily supervised. Even when evaluated exclusively in terms of results, process supervision scales better than outcome supervision.
Alignment methods (Alignment Methods) are used in artificial intelligence to bring the actions of AI systems in line with human values, making them both safer and more consistent with those values. According to the study authors, the alignment price will affect the widespread use of the alignment technique by exerting pressure on model deployment. This could ultimately improve the systems’ performance. The term “Alignment Tax” is used to describe this unintended consequence.
In a stroke of good fortune, experimental results show that the alignment cost of process supervision is negative in mathematics, which could lead to its widespread adoption. Even though it is unclear to the researchers how far their work can be applied outside of mathematics, research process monitoring is crucial for work in other subjects. When these findings are applied broadly, process supervision improves in terms of both effectiveness and consistency method.
In mathematical reasoning, researchers have demonstrated that process supervision can be utilized to train far more trustworthy reward models than outcome supervision. Researchers also demonstrated that active learning might reduce the expense of human data collection by prioritizing which model completions should be presented to humans for evaluation. Researchers anticipate that by removing this substantial barrier to entry, further study on the alignment of large language models will be stimulated by the availability of PRM800K, the whole dataset of human feedback used to train the state-of-the-art reward model. Researchers think process supervision is currently underexplored. Therefore researchers’ looking forward to future research examining these methods’ generalizability in greater detail.
Check Out The Project Blog and Paper. Don’t forget to join our 23k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.