Robot reinforcement learning: safety in real-world applications
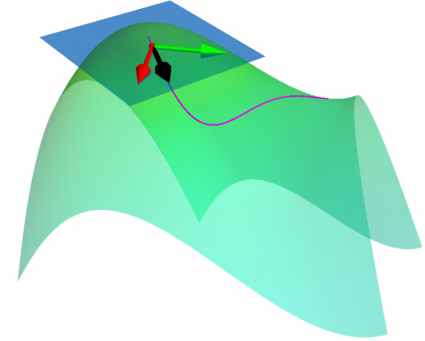
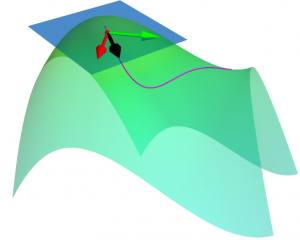
How can we make a robot learn in the real world while ensuring safety? In this work, we show how it’s possible to face this problem. The key idea to exploit domain knowledge and use the constraint definition to our advantage. Following our approach, it’s possible to implement learning robotic agents that can explore and learn in an arbitrary environment while ensuring safety at the same time.
Safety and learning in robots
Safety is a fundamental feature in real-world robotics applications: robots should not cause damage to the environment, to themselves, and they must ensure the safety of people operating around them. To ensure safety when we deploy a new application, we want to avoid constraint violation at any time. These stringent safety constraints are difficult to enforce in a reinforcement learning setting. This is the reason why it is hard to deploy learning agents in the real world. Classical reinforcement learning agents use random exploration, such as Gaussian policies, to act in the environment and extract useful knowledge to improve task performance. However, random exploration may cause constraint violations. These constraint violations must be avoided at all costs in robotic platforms, as they often result in a major system failure.
While the robotic framework is challenging, it is also a very well-known and well-studied problem: thus, we can exploit some key results and knowledge from the field. Indeed, often a robot’s kinematics and dynamics are known and can be exploited by the learning systems. Also, physical constraints e.g., avoiding collisions and enforcing joint limits, can be written in analytical form. All this information can be exploited by the learning robot.
Our approach
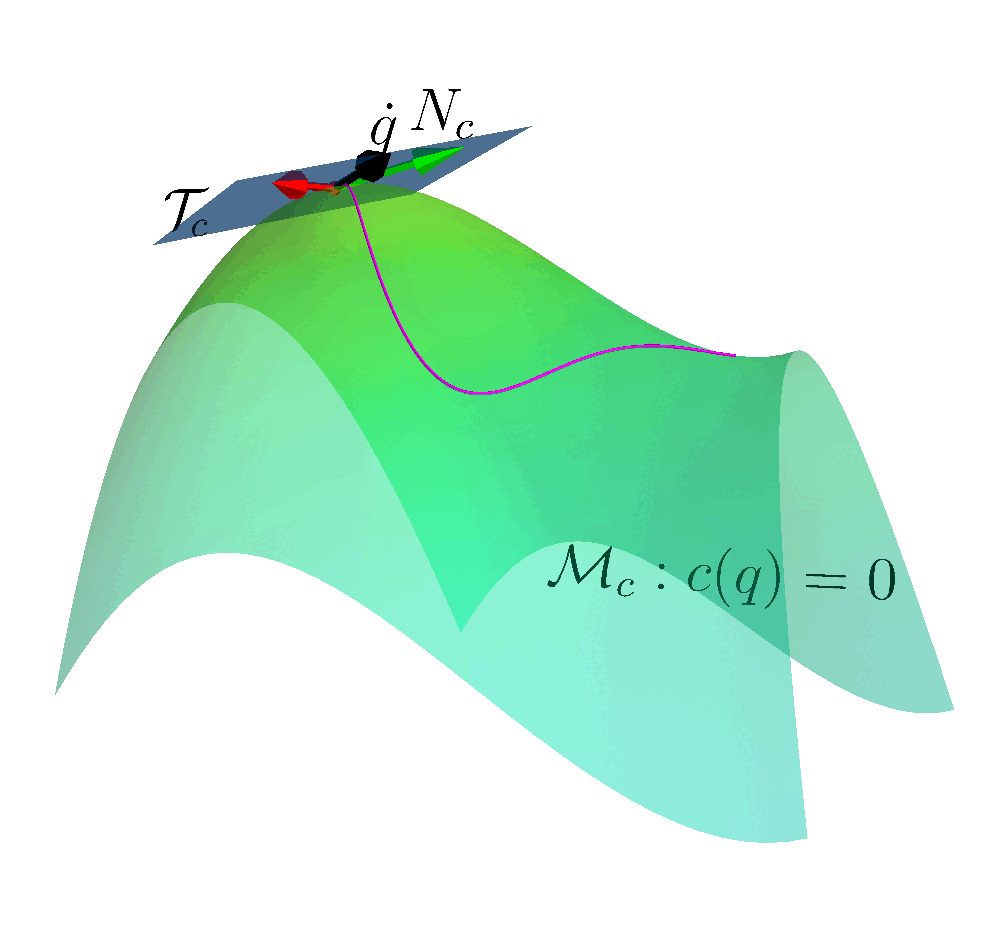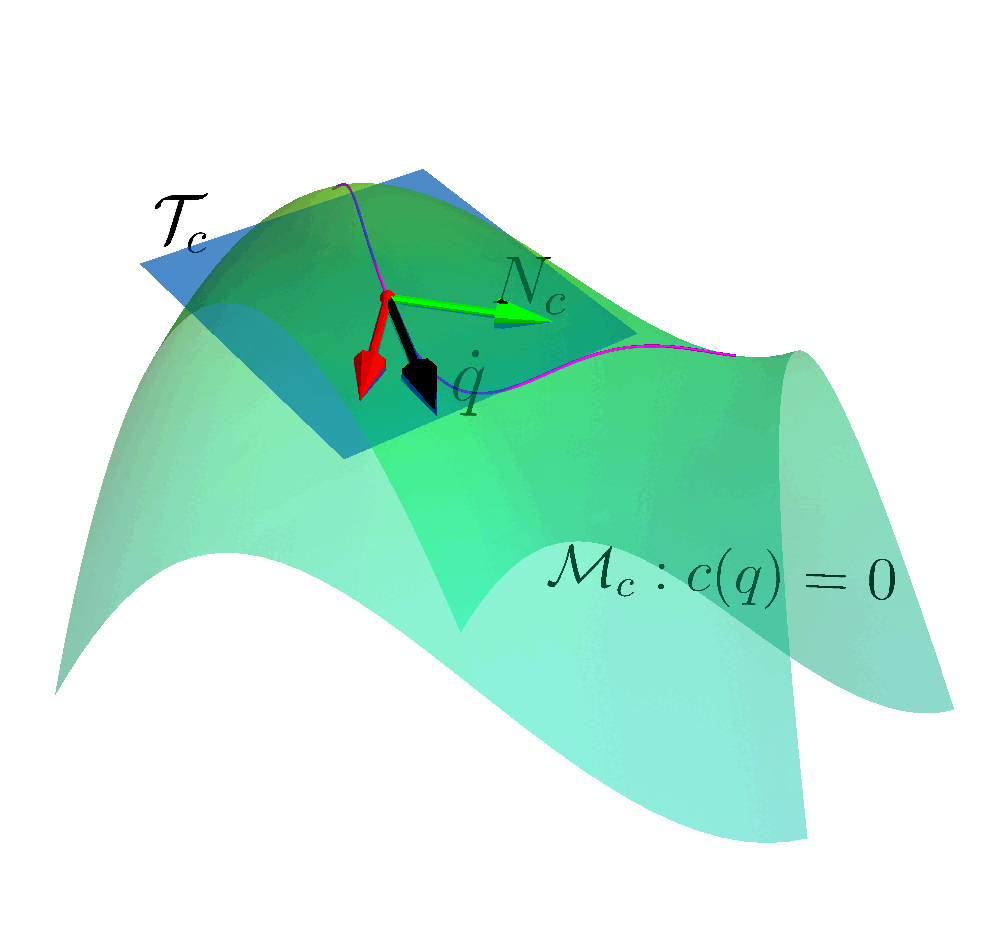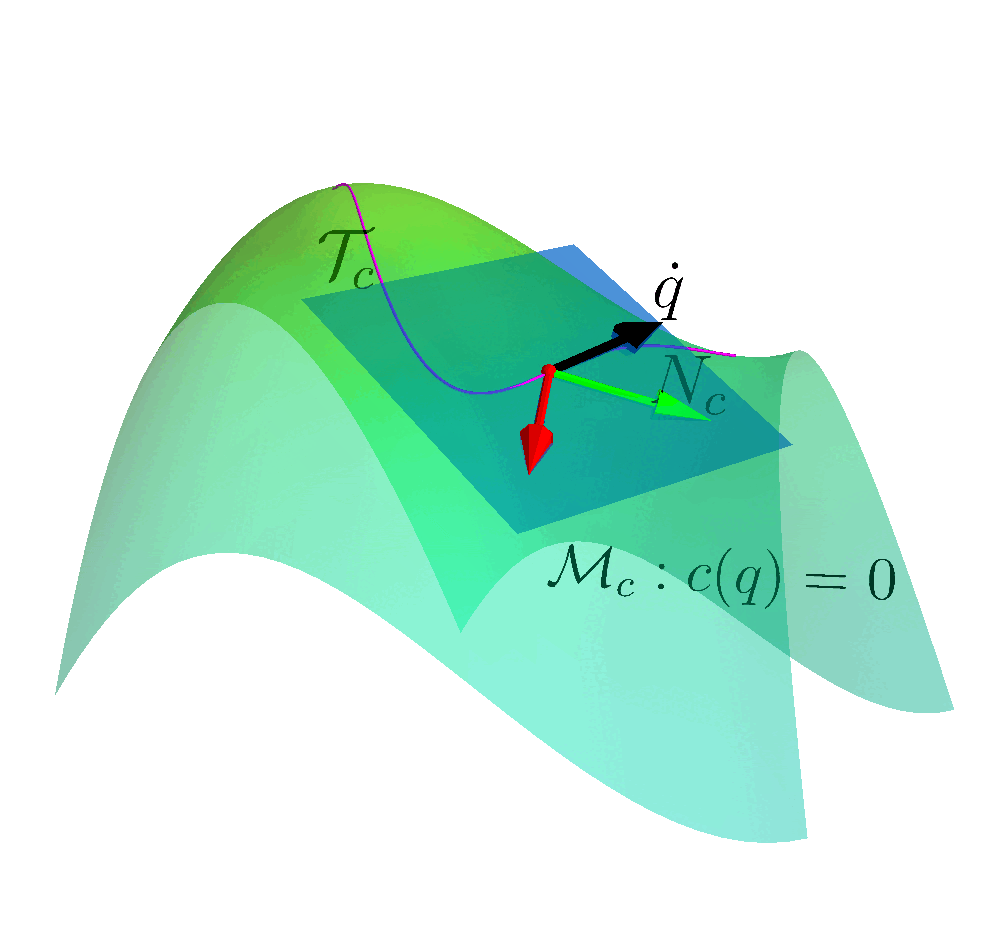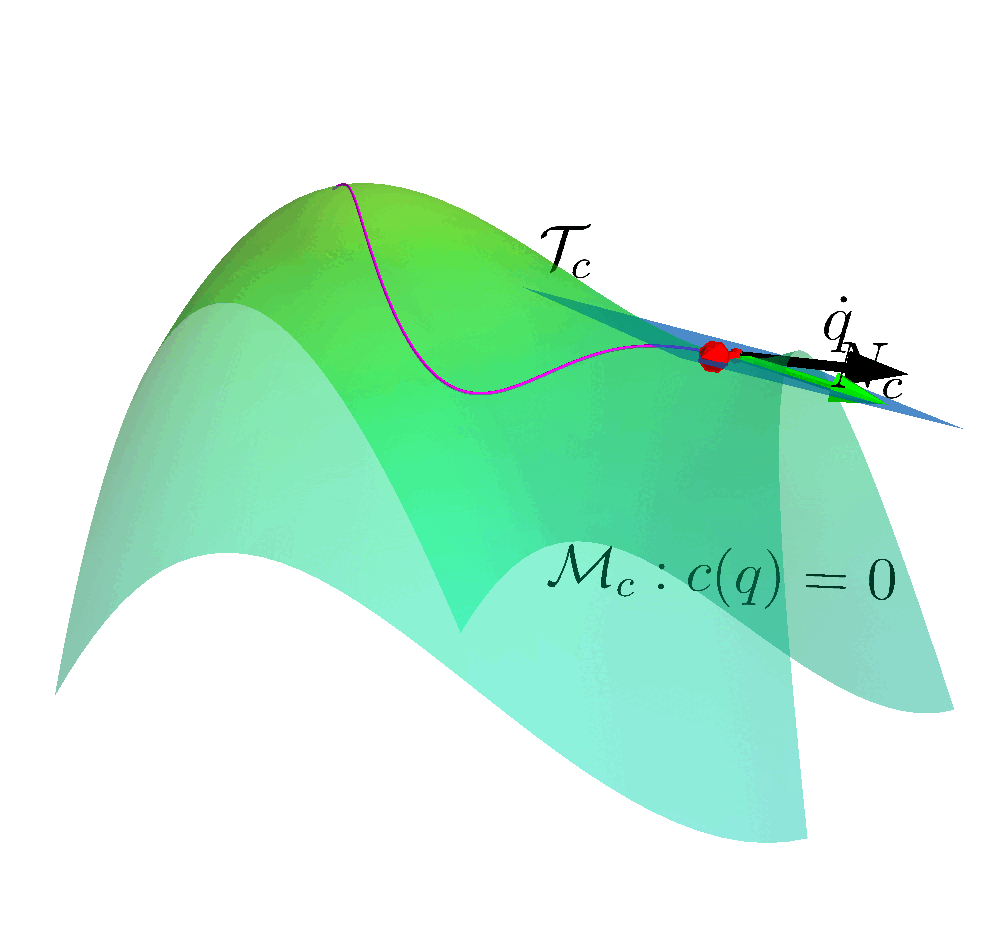
Many reinforcement learning approaches try to solve the safety problem by incorporating the constraint information in the learning process. This approach often results in slower learning performances, while not being able to ensure safety during the whole learning process. Instead, we present a novel point of view to the problem, introducing ATACOM (Acting on the TAngent space of the COnstraint Manifold). Different from other state-of-the-art approaches, ATACOM tries to create a safe action space in which every action is inherently safe. To do so, we need to construct the constraint manifold and exploit the basic domain knowledge of the agent. Once we have the constraint manifold, we define our action space as the tangent space to the constraint manifold.
We can construct the constraint manifold using arbitrary differentiable constraints. The only requirement is that the constraint function must depend only on controllable variables i.e. the variables that we can directly control with our control action. An example could be the robot joint positions and velocities.
We can support both equality and inequality constraints. Inequality constraints are particularly important as they can be used to avoid specific areas of the state space or to enforce the joint limits. However, they don’t define a manifold. To obtain a manifold, we transform the inequality constraints into equality constraints by introducing slack variables.
With ATACOM, we can ensure safety by taking action on the tangent space of the constraint manifold. An intuitive way to see why this is true is to consider the motion on the surface of a sphere: any point with a velocity tangent to the sphere itself will keep moving on the surface of the sphere. The same idea can be extended to more complex robotic systems, considering the acceleration of system variables (or the generalized coordinates, when considering a mechanical system) instead of velocities.
The above-mentioned framework only works if we consider continuous-time systems, when the control action is the instantaneous velocity or acceleration. Unfortunately, the vast majority of robotic controllers and reinforcement learning approaches are discrete-time digital controllers. Thus, even taking the tangent direction of the constraint manifold will result in a constraint violation. It is always possible to reduce the violations by increasing the control frequency. However, error accumulates over time, causing a drift from the constraint manifold. To solve this issue, we introduce an error correction term that ensures that the system stays on the reward manifold. In our work, we implement this term as a simple proportional controller.
Finally, many robotics systems cannot be controlled directly by velocity or accelerations. However, if an inverse dynamics model or a tracking controller is available, we can use it and compute the correct control action.
Results
We tried ATACOM on a simulated air hockey task. We use two different types of robots. The first one is a planar robot. In this task, we enforce joint velocities and we avoid the collision of the end-effector with table boundaries.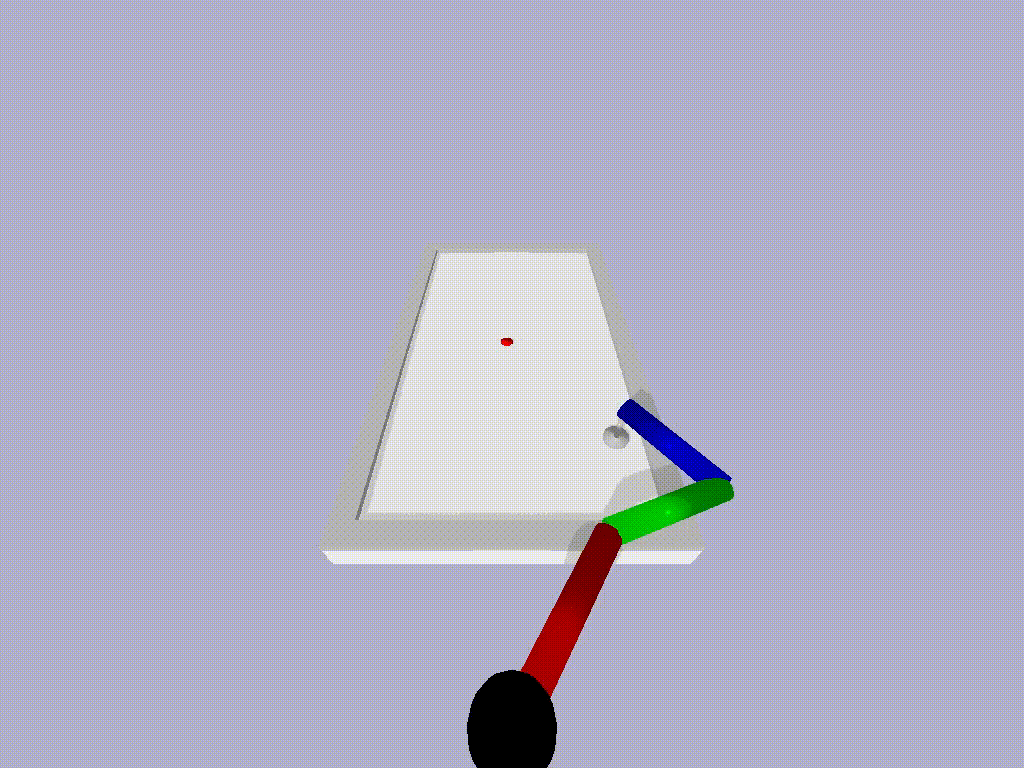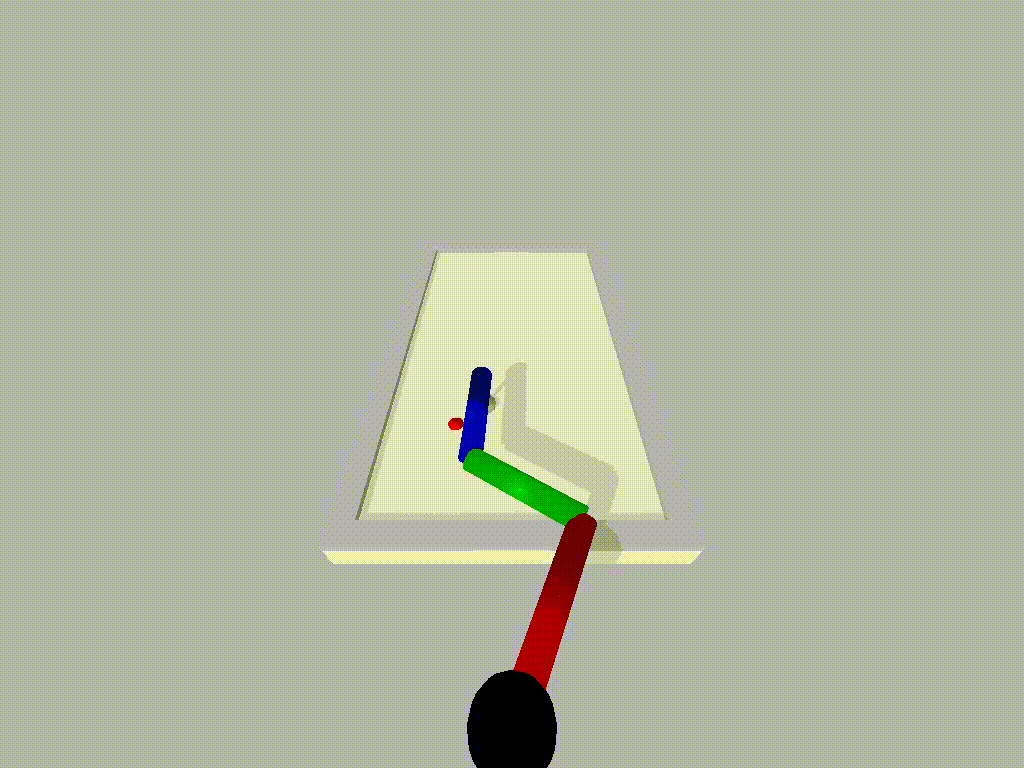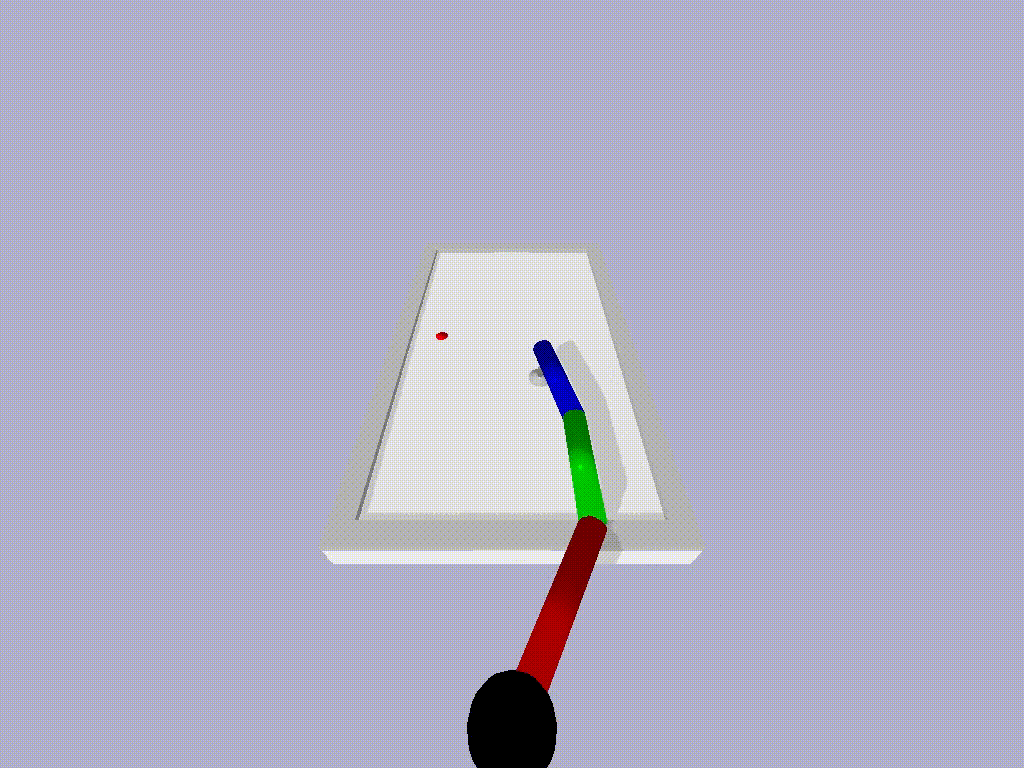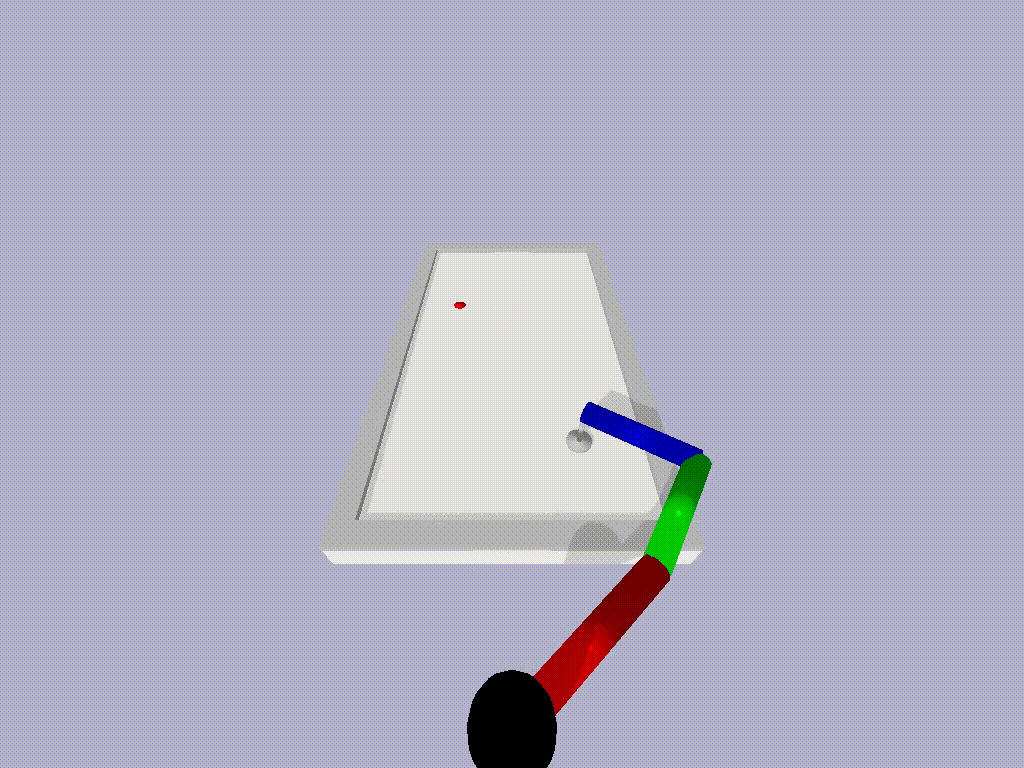
The second robot is a Kuka Iiwa 14 arm. In this scenario, we constrained the end-effector to move on the planar surface and we ensure no collision will occur between the robot arm and the table.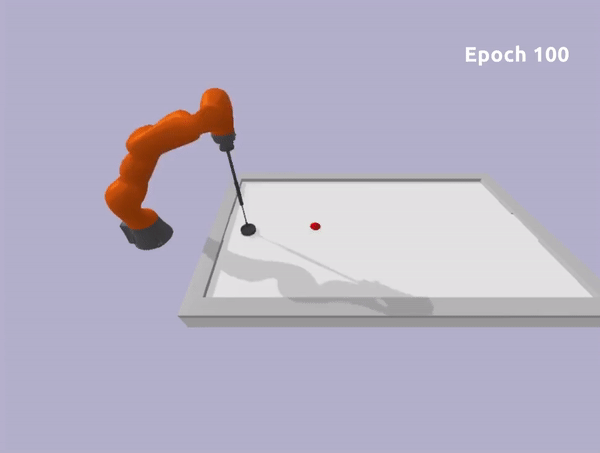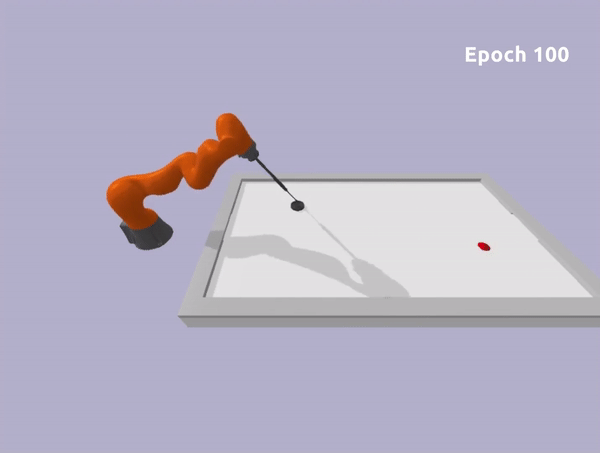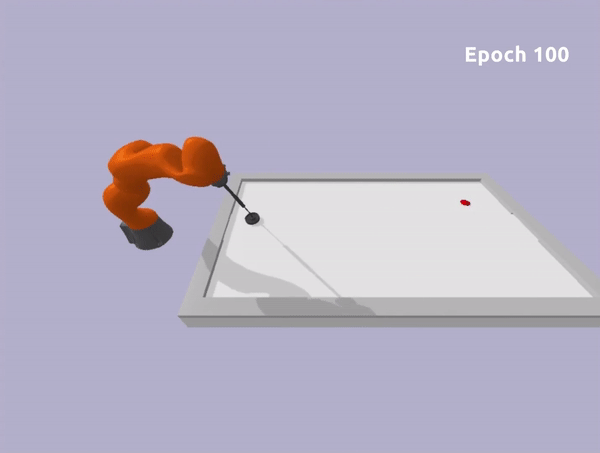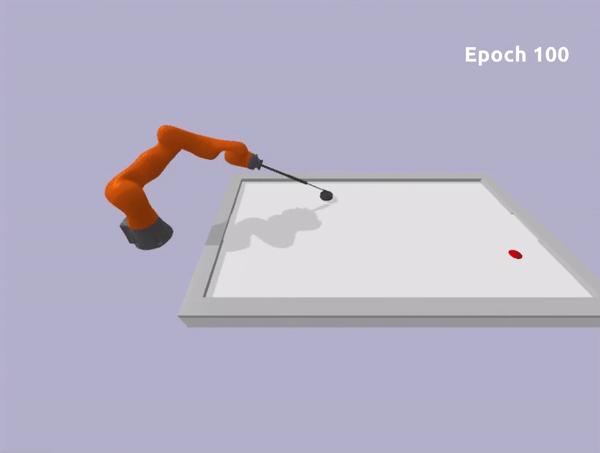
In both experiments, we can learn a safe policy using the Soft Actor-Critic algorithm as a learning algorithm in combination with the ATACOM framework. With our approach, we are able to learn good policies fast and we can ensure low constraint violations at any timestep. Unfortunately, the constraint violation cannot be zero due to discretization, but it can be reduced to be arbitrarily small. This is not a major issue in real-world systems, as they are affected by noisy measurements and non-ideal actuation.
Is the safety problem solved now?
The key question to ask is if we can ensure any safety guarantees with ATACOM. Unfortunately, this is not true in general. What we can enforce are state constraints at each timestep. This includes a wide class of constraints, such as fixed obstacle avoidance, joint limits, surface constraints. We can extend our method to constraints considering not (directly) controllable variables. While we can ensure safety to a certain extent also in this scenario, we cannot ensure that the constraint violation will not be violated during the whole trajectory. Indeed, if the not controllable variables act in an adversarial way, they might find a long-term strategy to cause constraint violation in the long term. An easy example is a prey-predator scenario: even if we ensure that the prey avoids each predator, a group of predators can perform a high-level strategy and trap the agent in the long term.
Thus, with ATACOM we can ensure safety at a step level, but we are not able to ensure long-term safety, which requires reasoning at trajectory level. To ensure this kind of safety, more advanced techniques will be needed.
Find out more
The authors were best paper award finalists at CoRL this year, for their work: Robot reinforcement learning on the constraint manifold.
- Read the paper.
- The GitHub page for the work is here.
- Read more about the winning and shortlisted papers for the CoRL awards here.
tags: c-Research-Innovation

Puze Liu
is a PhD student in the Intelligent Autonomous Systems Group, Technical University Darmstadt
Puze Liu
is a PhD student in the Intelligent Autonomous Systems Group, Technical University Darmstadt

Davide Tateo
is a Postdoctoral Researcher at the Intelligent Autonomous Systems Laboratory in the Computer Science Department of the Technical University of Darmstadt
Davide Tateo
is a Postdoctoral Researcher at the Intelligent Autonomous Systems Laboratory in the Computer Science Department of the Technical University of Darmstadt

Haitham Bou-Ammar
leads the reinforcement learning team at Huawei technologies Research & Development UK and is an Honorary Lecturer at UCL
Haitham Bou-Ammar
leads the reinforcement learning team at Huawei technologies Research & Development UK and is an Honorary Lecturer at UCL

Jan Peters
is a full professor for Intelligent Autonomous Systems at the Technische Universitaet Darmstadt and a senior research scientist at the MPI for Intelligent Systems
Jan Peters
is a full professor for Intelligent Autonomous Systems at the Technische Universitaet Darmstadt and a senior research scientist at the MPI for Intelligent Systems
Credit: Source link
Comments are closed.