Rutgers University’s AI Researchers Propose A Slot-Based Autoencoder Architecture, Called SLot Attention TransformEr (SLATE)
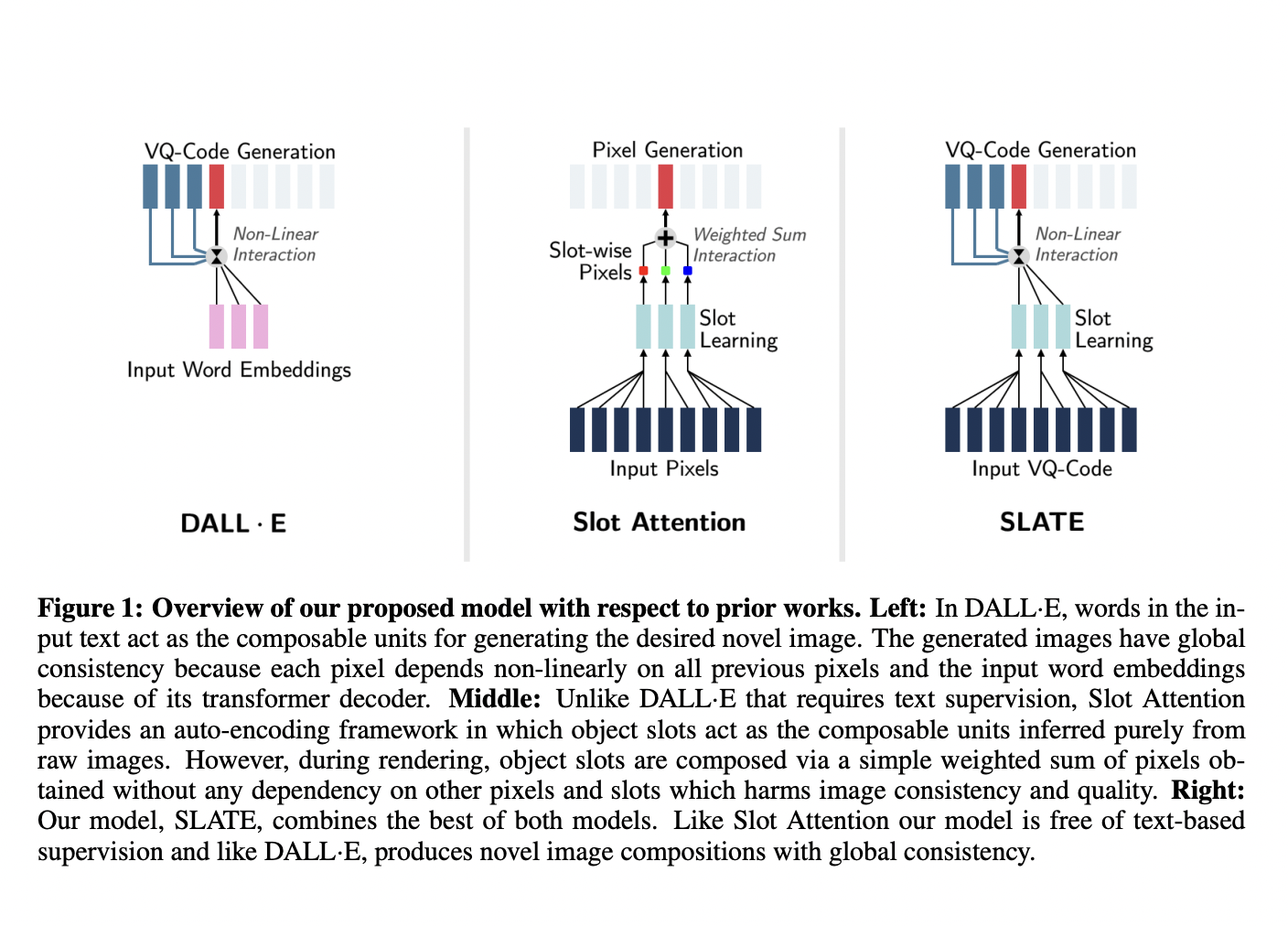

DALL·E has shown an impressive ability of composition-based systematic generalization in image generation, but it requires the dataset of text-image pairs and provides compositional clues from those texts. While the Slot Attention model can learn composable representations without text prompts, it does not have unlimited generative capacity like DALL·E for a zero-shot generation.
Researchers from Rutgers University propose a slot-based autoencoder architecture called SLot Attention TransformEr (SLATE). The SLATE model is a combination of the best from DALL·E and object-centric representation learning. In contrast to previous models, it significantly improves composition-based systematic generalization in image generation.
The research team showed that they could create a model Illiterate DALL·E (I-DALLE), which can learn object representation from images alone instead of taking text prompts. To get this done, the team begins by analyzing that existing pixel-mixture decoders for learning object-centric representations suffer from limitations such as slot decoding dilemma and independent pixels. Based on DALL·E, the research team then hypothesized that to resolve these limitations, not only does one need a composable slot but also an expressive decoder.
The SLATE architecture was proposed based on the above research findings. SLATE is a simple but novel slot autoencoding architecture that uses a slot-conditioned Image GPT decoder. Apart from this, the research group also proposed a method to build up visual concepts from learned slots. This is similar to text prompts in DALL·E and allows them to program sentences of images made up of these slot types.

The main contributions of the research work include:
- To achieve the first text-free DALL·E model.
- The first object-centric representation learning on transformer.
- They explained that the proposed model significantly improves the systematic generalization ability of object-centric representation models.
- In terms of performance, the proposed model is much simpler than previous approaches.
Github: https://github.com/singhgautam/slate
Paper: https://arxiv.org/pdf/2110.11405.pdf
Project: https://sites.google.com/view/slate-autoencoder
Suggested
Credit: Source link
Comments are closed.