Salesforce AI Research Proposes A ‘Burn After Reading’ Framework For Data Privacy Where User Data Samples Are Immediately Deleted After They’re Processed
With the pandemic’s arrival, the internet has become an even more integral part of everyone’s daily existence. Because of the interconnectedness of our modern lives, it is now exceedingly difficult to conceal one’s digital footprint by deleting old photos, social media posts, and tweets from the cloud.
The right to privacy above convenience has been a topic of discussion, and recommender systems that actively mine user data for data-driven algorithms have stoked the fires. The Right to Be Forgotten (RTBF) is welcome protection that allows people to demand that businesses erase their records. Recently, various proposals have emerged, primarily centering on the Federated Learning framework, which aims to guarantee privacy in deep learning. Since sensitive data is only saved on a subset of nodes, asynchronous updates across many nodes are possible with federated learning. However, new research shows that the gradient-sharing method used in distributed models can leak confidential training data.
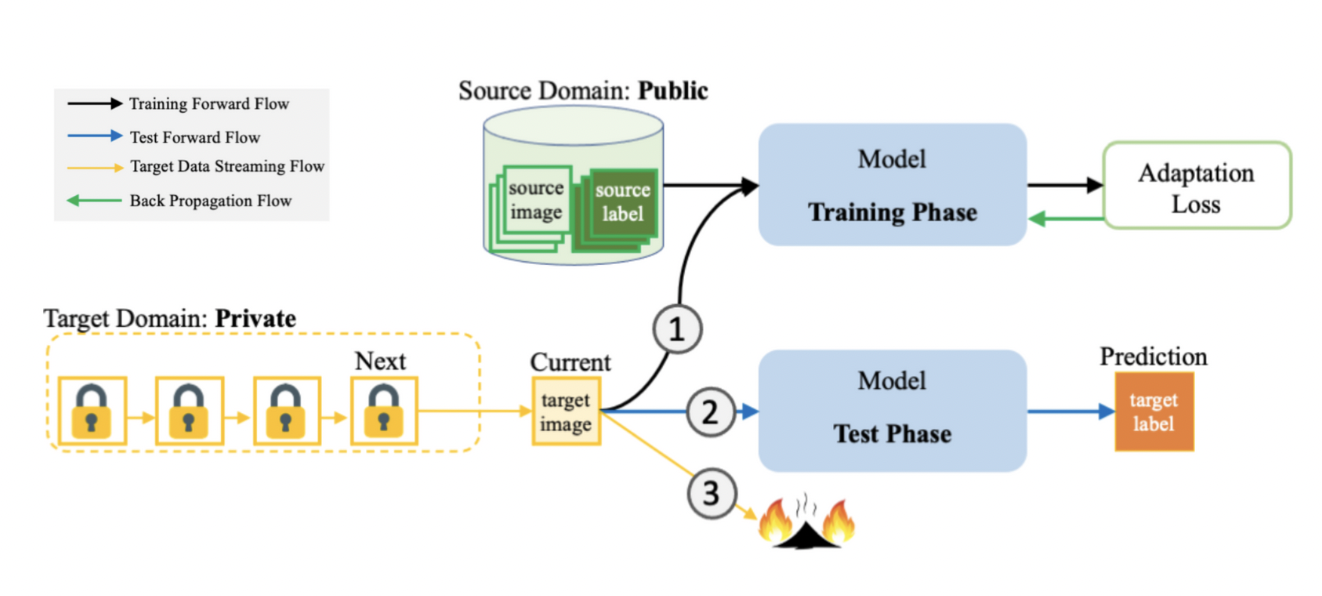
Researchers from the University of Maryland and Salesforce claim that not storing sensitive data is the most secure practice in their recent work, “Burn After Reading: Online Adaptation for Cross-domain Streaming Data.”
Unfortunately, the distribution shift from public data (the source domain) to private user data (the target domain) is not currently taken into account by any of the existing online learning frameworks, making it impossible for them to meet this demand. As a solution, they suggest a paradigm for online domain adaptation in which modified streaming data from the target domain is promptly discarded. Despite appearing to be an extended unsupervised domain adaptation (UDA) setting, the challenge cannot be performed by simply bringing offline UDA methods online.

Since there is a shortage of data in the target domain, the online UDA task requires innovative approaches. To begin, the online streaming scenario cannot afford to give the rich combinations of cross-domain mini-batches that conventional offline UDA algorithms rely on for adaptation. In particular, many adversarial-based approaches within a given domain rely on a slow annealing adversarial mechanism that calls for discerning a high number of source-target pairs to effect the necessary adaptation.
Their approach for online domain adaptation is based on cross-domain bootstrapping, which allows them to directly tackle the most fundamental difficulty of the online task. The diversity of the data across domains is increased with each online query by bootstrapping the source domain to create unique permutations with the current target query. They train a group of autonomous learners to keep the distinctions between them to make the most of different permutations. They combine the learners’ expertise by having them trade their predicted pseudo-labels on the current target query to co-supervise the training on the target domain. However, they are not allowed to exchange weights to preserve their differences. By averaging the knowledge of all the learners, they could make a more precise forecast of the present target query. They call it CroBoDo “Cross-Domain Bootstrapping for Online Domain Adaptation,”
They test the method on different benchmarks, such as the canonical UDA benchmark VisDA-C [59], the medical imaging benchmark COVID-DA, and the massive distribution shift benchmark WILDS subset Camelyon. The finding reveals that the proposed approach outperforms state-of-the-art UDA approaches suitable for the web-based environment on all benchmarks. In addition, this strategy provides competitive results in the offline context without requiring the reuse of any target sample. Their straightforward solution’s performance is on par with that in an offline environment, so it’s a good option even if you’re only concerned with saving time.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Burn After Reading: Online Adaptation for Cross-domain Streaming Data'. All Credit For This Research Goes To Researchers on This Project. Check out the paper, code and reference article. Please Don't Forget To Join Our ML Subreddit
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.