Salesforce AI Researchers Introduce the Evolution of LLM-Augmented Autonomous Agents and the Innovative BOLAA Strategy
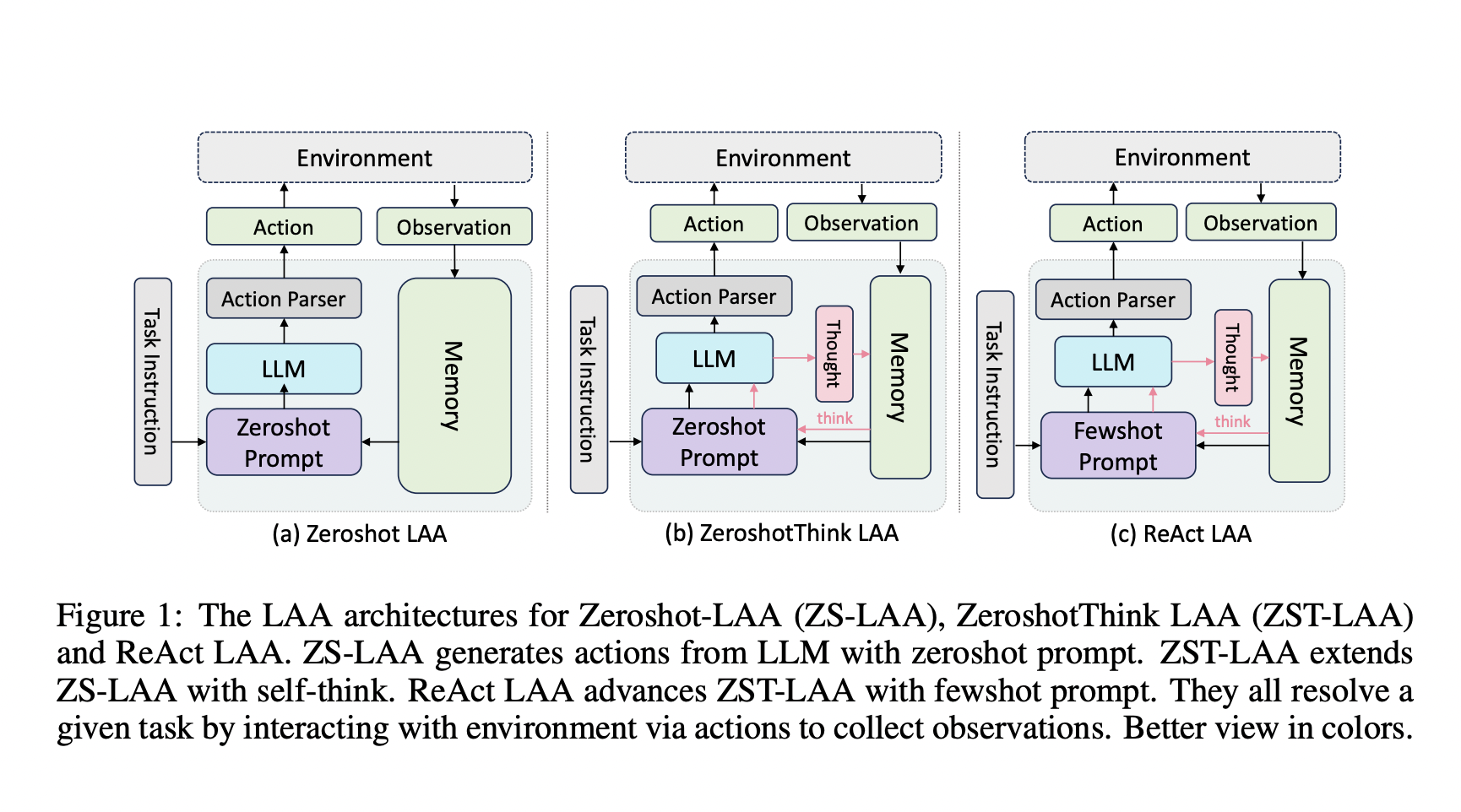
Recent large language model (LLM) accomplishments encourage new research into using LLMs to handle various complicated tasks, with LLM-augmented Autonomous Agents (LAAs) garnering the greatest attention. By extending LLM’s intelligence to sequential action executions, LAA shows supremacy in interacting with settings and handling challenging problems by gathering data. BabyAGI1 suggests an AI-powered task management system that uses OpenAI LLM2 to generate, prioritize, and carry out tasks. Another well-liked open-source LAA framework that permits LLM API calls is AutoGPT3.
ReAct is a recently put forth LAA technique that interacts with surroundings before generating subsequent actions. A current open-source framework for creating LAA is called Langchain4. LAA hasn’t been thoroughly investigated because of the original probe. The best agent architecture has yet to be identified to start. For the LLM to learn to create the next action through in-context learning, ReAct stimulates the agents with examples that have already been pre-defined. Furthermore, ReAct contends that an agent should engage in intermediate thinking before executing an action. ReWOO introduces additional planning processes for LAA.
Langchain generalizes the ReAct agent with zero-shot tool usage capability. The best agent design should align with tasks and the corresponding LLM backbone, which is less well addressed in the prior research. Second, knowledge of the effectiveness of the current LLMs in LAA still needs to be completed. Only a few LLM backbones’ performances are compared in the early papers. ReAct uses the PaLM as the main LLM. ReWOO uses the OpenAI text-DaVinci-003 model for agent planning and instruction tailoring. For a generalist web agent, MIND2Web compares Flan-T5 with OpenAI GPT3.5/4.
However, only a few recent research thoroughly contrast the effectiveness of LAA with different pre-trained LLMs. A relatively recent article has just published a baseline for assessing LLMs as Agents. However, they must consider the agent architectures and their LLM backbones jointly. LAA research is advanced by choosing the best LLMs from both an effectiveness and efficiency standpoint. Thirdly, as activities get more complicated, numerous agents may need coordination. Recently, ReWOO discovered that separating reasoning from observation increases LAA’s effectiveness.
In this study, researchers from Salesforce Research make the case that it is preferable to coordinate several agents to carry out a single job as task complexity rises, particularly in open-domain situations. For the online navigation job, for instance, they might use a click agent to interact with clickable buttons while requesting a search agent to find other resources. However, few papers examine the effects of orchestration and explore ways to coordinate many individuals. This report suggests extensive analysis of LAA performance comparison to fill these research gaps. They delve further into the LLM backbones’ and LAAs’ agent architecture.
They create agent benchmarks from the already-existing settings to assess how well different agent architectures based on various LLM backbones function. Because the tasks in their agent benchmarks are linked to multiple task complexity levels, it is possible to examine the agents’ performance in relation to task complexity. These agent architectures are created to validate the current design decisions thoroughly. To enable the selection and communication amongst several labor LAAs, they present a unique LAA architecture called BOLAA5 that features a controller module on top of numerous cooperated agents.
The paper’s contributions follow:
• Six distinct LAA agent architectures are developed. To support the LAA’s designing intuition derived from prompting, self-thinking, and planning, they integrate them with several backbone LLMs. They also create BOLAA for multi-agent strategy orchestration, which improves the capacity of lone agents to engage with actions.
• They undertake comprehensive studies on the environments for knowledge reasoning tasks and decision-making online navigation. They provide the performance as final sparse rewards and intermediate recollections, which gives qualitative recommendations for the best LAA and suitable LLM choices.
• When compared to alternative LAA designs, BOLAA consistently produces the best performance in the WebShop environment. Their findings highlight the significance of developing specialized agents to work together on addressing complicated problems, which should be just as significant as developing a sizable LLM with strong generalization capabilities.
Check out the Paper and GitHub. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 28k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.