Salesforce Researchers Open-Source ‘Taichi’: A Python Library For Few-Shot NLP

This Article is written as a summay by Marktechpost Staff based on the article 'TaiChi: Open Source Library for Few-Shot NLP'. All Credit For This Research Goes To Researchers on This Project. Checkout the github, paper 1, paper 2 and post. Please Don't Forget To Join Our ML Subreddit
It is a well-known fact that the predictive abilities of ML models are dependent on the size of the training datasets, and their performance improves as more data is fed into them.
Few-shot learning (FSL) is a machine learning (ML) technique where ML models are trained on a training dataset that only contains a small amount of information.
Several studies have produced excellent results in pre-training, meta-learning, data augmentation, and public benchmark datasets over the last few years, resulting in significant advances in FSL research. Because data collection and labeling are frequently costly and time-consuming, innovations in FSL research have many potential applications in the sector.
Free-2 Min AI NewsletterJoin 500,000+ AI Folks
Although FSL is a very active area of study with a wide range of potential applications, data scientists and software engineers have not had easy access to commercially available, user-friendly libraries for speedy exploration.
The well-known Chinese martial art of Tai Chi emphasizes developing “smart strength,” such as using joints as levers to generate significant power with little effort.
The Salesforce research team found it very inspiring how this mindset of Tai Chi meshes so well with few-shot learning (FSL) research, where the goal is to train models with good performance with little data. Inspired by this, they created an FSL library, which employs clever techniques to get good performance with minimal effort. They hope it may aid others in their model training in low-data settings.
TaiChi is an open-source few-shot NLP package that doesn’t require users to have a high level of FSL knowledge. It is intended for data scientists and software engineers who wish to construct proof-of-concept products or get some quick results but have little experience with few-shot learning (FSL). The library dramatically lowers the barrier to learning and using the most recent FSL methods by abstracting sophisticated FSL methods into Python objects that can be accessed by just one or two lines of code. Even with a limited number of samples, models can be trained.
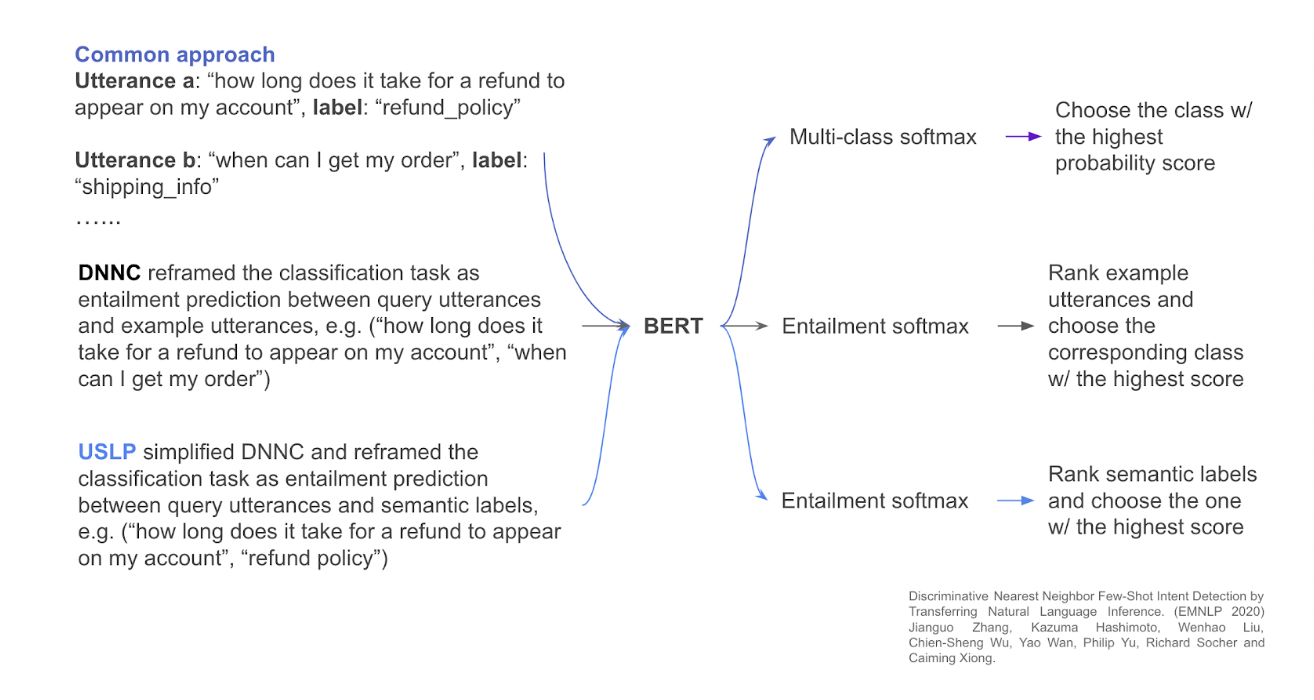
A technique known as discriminative closest neighbor classification, or DNNC, has recently been developed in this field. This approach conceptualizes a few-shot intent classification as an NLI between query utterances and training instances.
This work inspired the team’s suggestion to streamline the NLI-style classification pipeline by entailment prediction on the pair of utterance and semantic label data (USLP). Thus, the classification method can incorporate semantic data in the labels.
The researchers identified two basic models for DNNC and USLP: nli-pretrained-roberta-base (English only model) and nli-pretrained-xlm-roberta-base (supports 100 languages and can be utilized for multi/cross-lingual applications). These models were further modified with the NLI dataset to make them appropriate for NLI-style categorization. They are based on publicly available pre-trained models from Huggingface.
Both DNNC and USLP are based on NLI-style classification. But, USLP condenses DNNC by attempting to forecast the entailment relationship between utterances and semantic labels. In contrast, DNNC reframes classification as entailment prediction between query and utterances in the training set.
For training and benchmarking, the team used the CLINC150 Dataset. Because the proposed method is based on the entailment between query utterance and labels rather than all training samples, their findings imply that it is more efficient in training and serving than DNNC.
The USLP method does not have this restriction, whereas the DNNC method calls for more than one example per intent.
The USLP method outperforms the conventional classification methodology in one-shot studies.
Model performance often improves with longer, more semantically relevant labels; however, the improvement diminishes as more training data become accessible.
Credit: Source link
Comments are closed.