Seeing and Hearing: Bridging Visual and Audio Worlds with AI
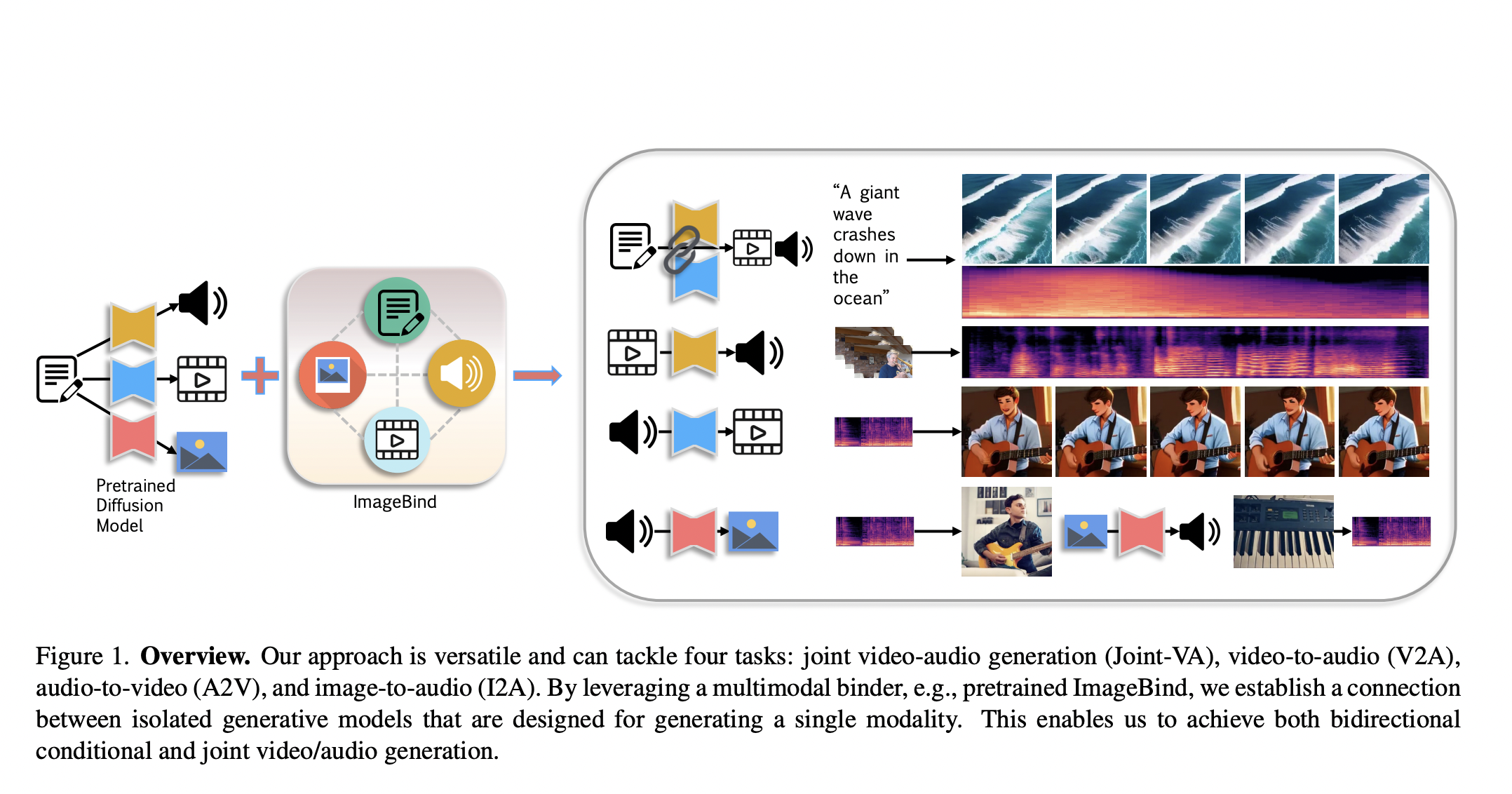
The pursuit of generating lifelike images, videos, and sounds through artificial intelligence (AI) has recently taken a significant leap forward. However, these advancements have predominantly focused on single modalities, ignoring our world’s inherently multimodal nature. Addressing this shortfall, researchers have introduced a pioneering optimization-based framework designed to integrate visual and audio content creation seamlessly. This innovative approach utilizes existing pre-trained models, notably the ImageBind model, to establish a shared representational space that facilitates the generation of content that is both visually and aurally cohesive.
The challenge of synchronizing video and audio generation presents a unique set of complexities. Traditional methods, which often involve generating video and audio in separate stages, fall short in delivering the desired quality and control. Recognizing the limitations of such two-stage processes, researchers have explored the potential of leveraging powerful, pre-existing models that excel in individual modalities. A key discovery was the ImageBind model’s ability to link different data types within a unified semantic space, thus serving as an effective “aligner” in the content generation process.
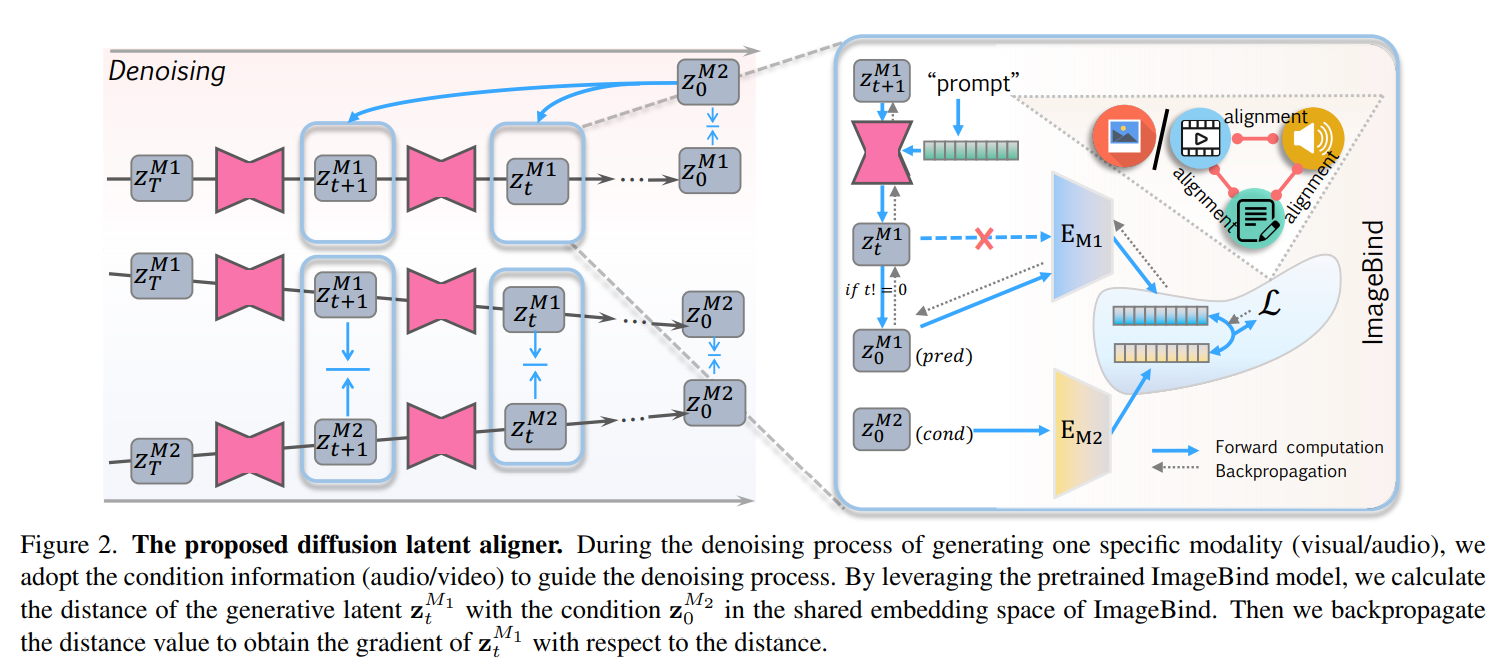
At the core of this method is the use of diffusion models, which generate content by progressively reducing noise. The proposed system employs ImageBind as a kind of referee, providing feedback on the alignment between the partially generated image and its corresponding audio. This feedback is then used to fine-tune the generation process, ensuring a harmonious audio-visual match. The approach is akin to classifier guidance in diffusion models but applied across modalities to maintain semantic coherence.
The researchers further refined their system to tackle challenges such as the semantic sparsity of audio content (e.g., background music) by incorporating textual descriptions for richer guidance. Additionally, a novel “guided prompt tuning” technique was developed to enhance content generation, particularly for audio-driven video creation. This method allows for dynamic adjustment of the generation process based on textual prompts, ensuring a higher degree of content alignment and fidelity.
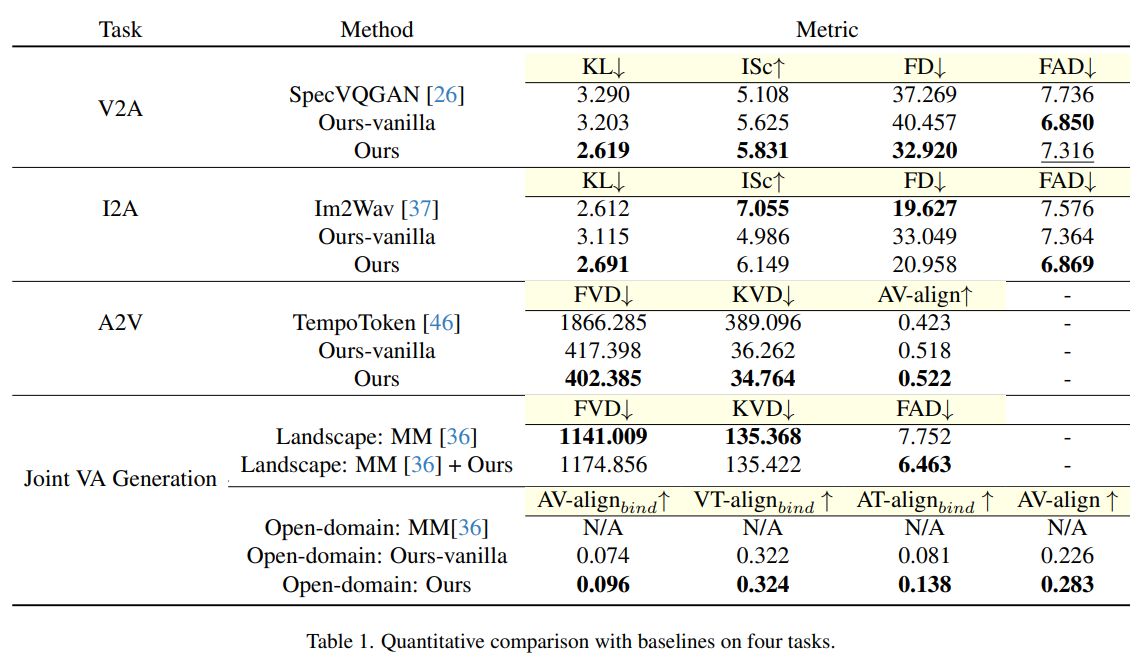
To validate their approach, the researchers conducted a comprehensive comparison against several baselines across different generation tasks. For video-to-audio generation, they selected SpecVQGAN as a baseline, while for image-to-audio tasks, Im2Wav served as the comparison point. TempoTokens was chosen for the audio-to-video generation task. Additionally, MM-Diffusion, a state-of-the-art model for joint video and audio generation in a limited domain, was used as a baseline for evaluating the proposed method in open-domain tasks. These rigorous comparisons revealed that the proposed method consistently outperformed existing models, demonstrating its effectiveness and flexibility in bridging visual and auditory content generation.
This research offers a versatile, resource-efficient pathway for integrating visual and auditory content generation, setting a new benchmark for AI-driven multimedia creation. The ability to harness pre-existing models for this purpose hints at the potential for future advancements, where improvements in foundational models could lead to even more compelling and cohesive multimedia experiences.
Despite its impressive capabilities, the researchers acknowledge limitations primarily stemming from the generation capacity of the foundational models, such as AudioLDM and AnimateDiff. The current performance in aspects like visual quality, complex concept composition, and motion dynamics in audio-to-video and joint video-audio tasks suggests room for future enhancements. However, the adaptability of their approach indicates that integrating more advanced generative models could further refine and improve the quality of multimodal content creation, offering a promising outlook for the future.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.
Credit: Source link
Comments are closed.