Seeking Faster, More Efficient AI? Meet FP6-LLM: the Breakthrough in GPU-Based Quantization for Large Language Models
In computational linguistics and artificial intelligence, researchers continually strive to optimize the performance of large language models (LLMs). These models, renowned for their capacity to process a vast array of language-related tasks, face significant challenges due to their expansive size. For instance, models like GPT-3, with 175 billion parameters, require substantial GPU memory, highlighting a need for more memory-efficient and high-performance computational methods.
One of the primary challenges in deploying large language models is their enormous size, which necessitates significant GPU memory and computational resources. The memory wall issues further compound this challenge during token generation, where the speed of model inference is primarily limited by the time taken to read model weights from GPU DRAM. Consequently, there is a pressing need for efficient methods to reduce the memory and computational load without compromising the models’ performance.
Current approaches to handling large language models often involve quantization techniques that use fewer bits to represent each model weight, resulting in a more compact representation. However, these techniques have limitations. For example, while reducing the model size, 4-bit and 8-bit quantizations do not efficiently support the execution of linear layers on modern GPUs, compromising either model quality or inference speed.
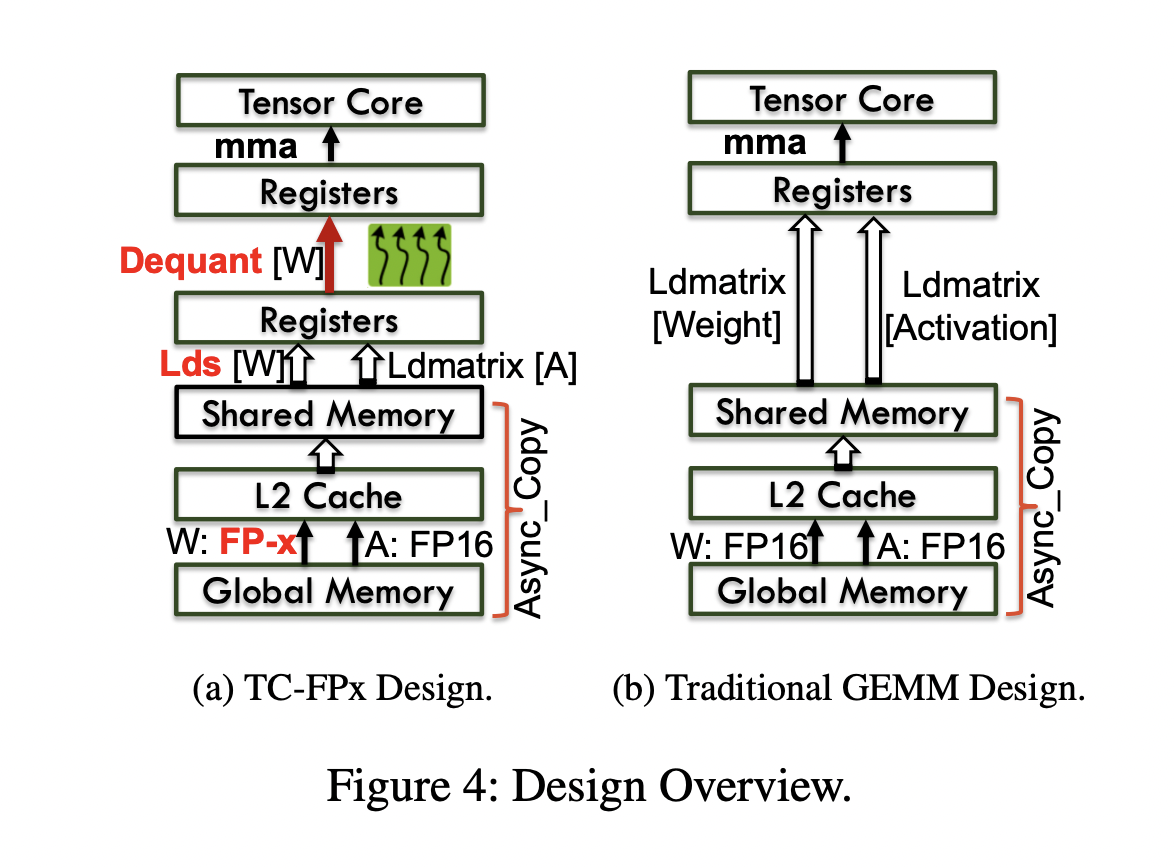
A team of researchers from Microsoft, the University of Sydney, and Rutgers University introduced a system design, TC-FPx, the first full-stack GPU kernel design scheme with unified Tensor Core support for various quantization bit-widths, including 6-bit, 5-bit, and 3-bit. This design addresses the challenges of unfriendly memory access and high runtime overhead associated with weight de-quantization in large language models. By integrating TC-FPx into existing inference systems, they developed a new end-to-end support system, FP6-LLM, for quantized LLM inference.
TC-FPx employs ahead-of-time bit-level pre-packing and SIMT-efficient GPU runtime to optimize memory access and minimize the runtime overhead of weight de-quantization. This approach significantly enhances the performance of large language models by enabling more efficient inference with reduced memory requirements. The researchers demonstrated that FP6-LLM allows the inference of models like LLaMA-70b using only a single GPU, achieving substantially higher normalized inference throughput than the FP16 baseline.
The performance of FP6-LLM has been rigorously evaluated, showcasing its significant improvements in normalized inference throughput compared to the FP16 baseline. In particular, FP6-LLM enabled the inference of models like LLaMA-70b using only a single GPU while achieving 1.69-2.65 times higher throughput. This breakthrough demonstrates FP6-LLM’s potential to offer a more efficient and cost-effective solution for deploying large language models. The system’s ability to handle the inference of complex models with a single GPU represents a considerable advancement in the field, opening new possibilities for applying large language models in various domains.
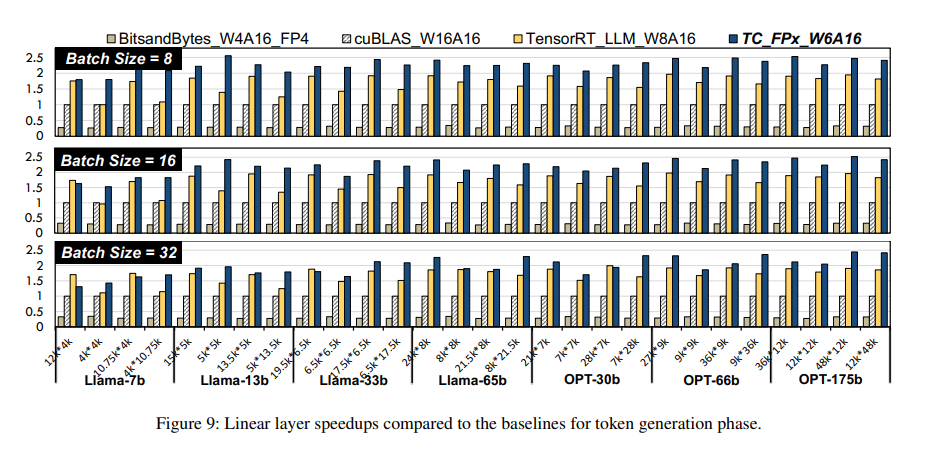
In conclusion, the research introduces a groundbreaking approach to deploying large language models through the development of FP6-LLM. Utilizing the TC-FPx kernel design, this system addresses the significant challenges posed by these models’ size and computational demands. By enabling more efficient GPU memory usage and higher inference throughput, FP6-LLM represents a vital step towards the practical and scalable deployment of large language models, paving the way for their broader application and utility in the field of artificial intelligence.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.