Seeking Speed without Loss in Large Language Models? Meet EAGLE: A Machine Learning Framework Setting New Standards for Lossless Acceleration
For LLMs, auto-regressive decoding is now considered the gold standard. Because LLMs generate output tokens individually, the procedure is time-consuming and expensive. Methods based on speculative sampling provide an answer to this problem. In the first, called the “draft” phase, LLMs are hypothesized at little cost; in the second, called the “verification” phase, all of the proposed tokens are checked in parallel using a single forward pass of the LLM. Speed is greatly improved by parallelizing speculative sampling, which allows for producing many post-check tokens for every LLM forward pass.
Speculative sampling aims to find a preliminary model that is comparable to the original LLM in terms of latency but faster. In most cases, a lower-parameter LLM derived from the same data set as the draft model is used in speculative sampling.
Speeding up speculative sampling requires lowering the time overhead and increasing the draft’s acceptance rate by the original LLM. However, the drafts produced by these systems are less precise, limiting their potential.
Recent studies by Peking University, Microsoft Research, University of Waterloo, and Vector Institute present EAGLE (Extrapolation Algorithm for Greater Language-model Efficiency). It is a straightforward framework that departs from direct token prediction and executes auto-regressive operations at the feature level based on the observation that feature-level auto-regression is easier to handle than token-level auto-regression. EAGLE avoids the uncertainty in feature-level auto-regression by using a token sequence advanced by a one-time step.
Theoretically, in both the greedy and non-greedy settings, EAGLE is guaranteed to preserve the output distribution and does not involve fine-tuning the original LLM. In certain instances, acceleration could cause LLM outputs to be incorrect or even hazardous, preventing any degradation. Lookahead and Medusa, on the other hand, are solely concerned with greedy situations. Compared to Medusa’s 0.6, EAGLE’s draft accuracy of about 0.8 is significantly better, achieved with a model that only includes a transformer decoder layer.
The study also offers views on aspects contributing to EAGLE’s effectiveness and introduces the simple yet efficient structure. These factors might be of independent relevance to other speculative sampling approaches. The foundation of EAGLE are these two findings:
- Top-layer features are more effective than bottom-layer token embeddings with the same lightweight network.
- Draft models that only input top-layer features are severely limited in performance due to the inherent uncertainty in the sampling process.
That is why it is critical to incorporate the token representing the sample results into the preliminary model.
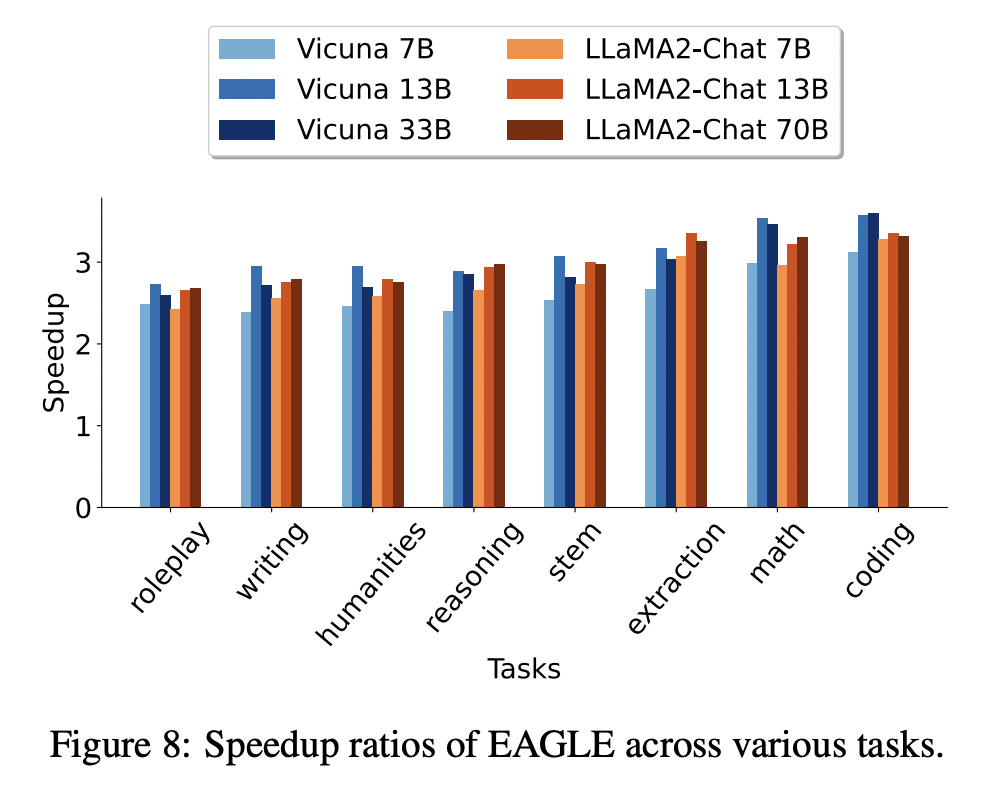
The team tested EAGLE on the MT-bench, a realistic benchmark miming real-world scenarios and applications. This benchmark includes multi-turn instructions similar to ChatGPT dialogues. Because it has been used state-of-the-art to exhibit speedup ratios by Lookahead and Medusa, they have also decided to use it. This decision makes it easy to compare the proposed method to these standards impartially and straightforwardly. With a greedy decoding configuration, EAGLE provides a 3x acceleration for Vicuna-13B and LLaMA2-Chat 13B, 70B, which is theoretically certain to preserve the original LLM’s text distribution and is immediately usable. EAGLE outperforms the newly suggested speculative sampling-based frameworks Lookahead and Medusa with a speedup of 2x and a speedup of 1.6x, respectively. With EAGLE, performance is improved, and LLM systems’ throughput is doubled.
EAGLE runs in tandem with other acceleration or throughput-enhancing techniques like quantization and compilation. The operational expenses of LLM systems could be further reduced by combining EAGLE with these approaches. Using gpt-fast1, EAGLE can increase the throughput of LLaMA2-Chat 7B decoding on a single RTX 3090 GPU from 24.5 to 160.4 tokens/s. Low training expenses are a feature of EAGLE. To train a decoder layer with less than 1 billion parameters for the LLaMA2-Chat 70B model, EAGLE uses the ShareGPT dataset with no more than 70k dialogues. On four A100 (40G) GPUs, the training takes about a day or two to finish. EAGLE can accelerate each query in real-world scenarios with just one training session. The amortized training cost of EAGLE falls to zero as the number of queries rises.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.