Segment Anything, but Faster! This AI Approach Speeds Up the SAM Model
Finding objects in images has been a long-going task in computer vision. Object detection algorithms try to locate the objects by drawing a box around them, while segmentation algorithms try to determine object boundaries pixel-perfectly. Image segmentation aims to partition an image into distinct regions or objects based on their semantic meaning or visual characteristics. It is crucial in various applications, including object recognition, scene understanding, autonomous driving, medical imaging, and more.
Over the years, numerous methods and algorithms have been developed to tackle this challenging problem. Traditional approaches use handcrafted features, and more recent advancements have brought us models driven by deep learning models. These modern methods have demonstrated remarkable progress, achieving state-of-the-art performance and enabling new possibilities in image understanding and analysis.
Though, these models had a fundamental limitation. They were bounded by the objects they saw in the training set, and they couldn’t segment the remaining objects.
Then there came the Segment Anything Model (SAM) that changed the image segmentation game entirely. It has emerged as a groundbreaking vision model capable of segmenting any object within an image based on user interaction prompts. It is built upon a Transformer architecture trained on the extensive SA-1B dataset, has demonstrated remarkable performance, and opened doors to a new and exciting task known as Segment Anything. With its generalizability and potential, it has the potential to become a cornerstone for a wide range of future vision applications.
Not everything about SAM is perfect, though. This sort of power comes with a cost, and for SAM, it’s the complexity. It is computationally too demanding, which makes it challenging to apply in practical scenarios. the computational resource requirements are associated with transformer models, particularly Vision Transformers (ViTs), which form the core of SAM’s architecture.
Is there a way to make SAM faster? The answer is yes, and it’s called FastSAM.
FastSAM is proposed to meet the high demand for industrial applications of the SAM mode. It manages to speed up SAM execution with a significant margin and enables it to be applied in practical scenarios.
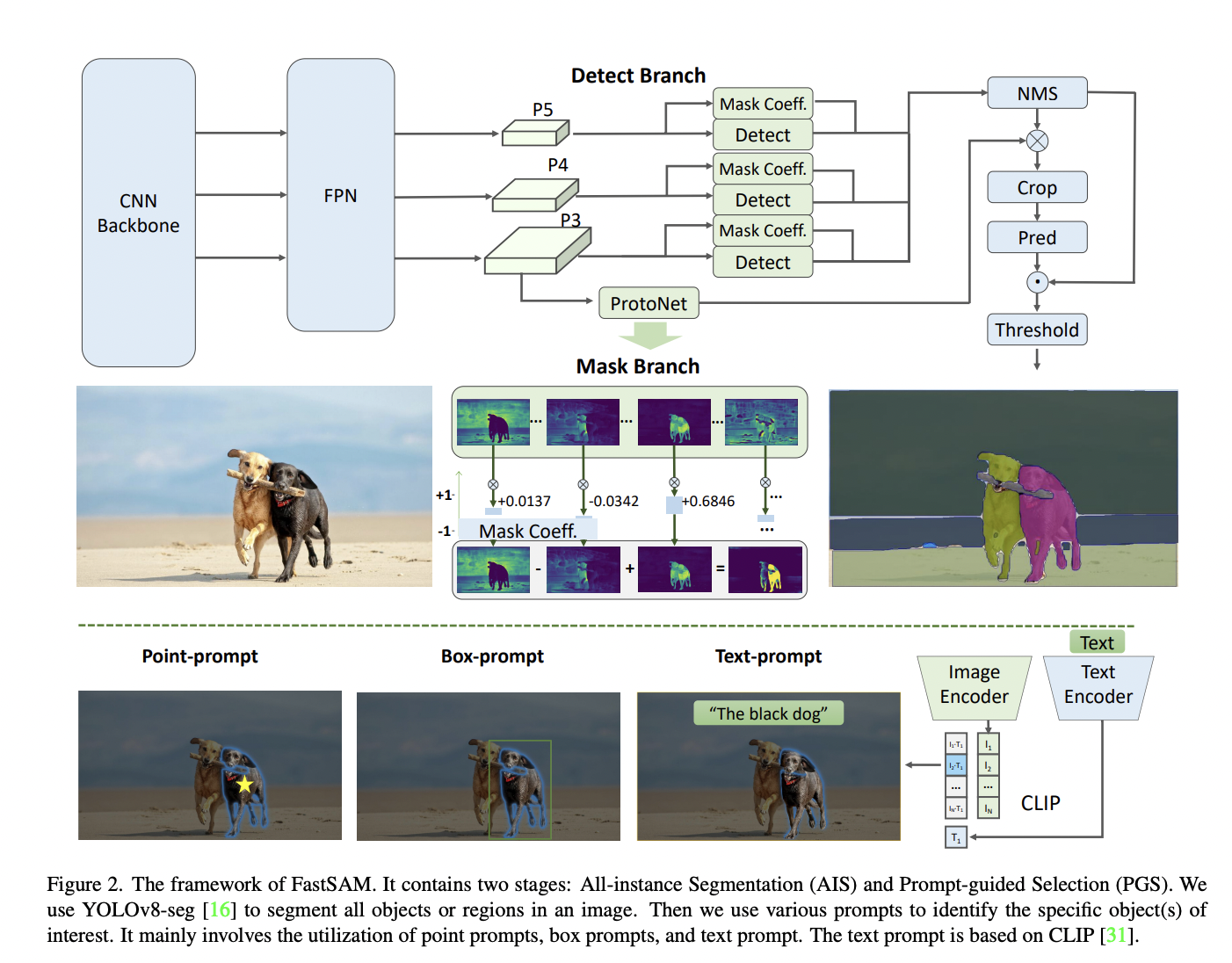
FastSAM decouples the segment anything task into two sequential stages: all-instance segmentation and prompt-guided selection. The first stage employs a Convolutional Neural Network (CNN)-based detector to produce segmentation masks for all instances in the image. In the second stage, it outputs the region of interest corresponding to the user prompt. Leveraging the computational efficiency of CNNs, FastSAM demonstrates the achievability of a real-time segment anything model without compromising on performance quality.
FastSAM is based on YOLOv8-seg, an object detector equipped with an instance segmentation branch inspired by the YOLACT method. By training this CNN detector on a mere 2% of the SA-1B dataset, FastSAM achieves comparable performance to SAM while drastically reducing computational demands. The proposed approach proves its efficacy in multiple downstream segmentation tasks, including object proposal on MS COCO, where FastSAM outperforms SAM in terms of Average Recall at 1000 proposals while running 50 times faster on a single NVIDIA RTX 3090.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Ekrem Çetinkaya received his B.Sc. in 2018, and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He received his Ph.D. degree in 2023 from the University of Klagenfurt, Austria, with his dissertation titled “Video Coding Enhancements for HTTP Adaptive Streaming Using Machine Learning.” His research interests include deep learning, computer vision, video encoding, and multimedia networking.
Credit: Source link
Comments are closed.