Semper Maior: Improving Video Decoding with Machine Learning (How Machine Learning ML is used in Video Encoding Part 4)
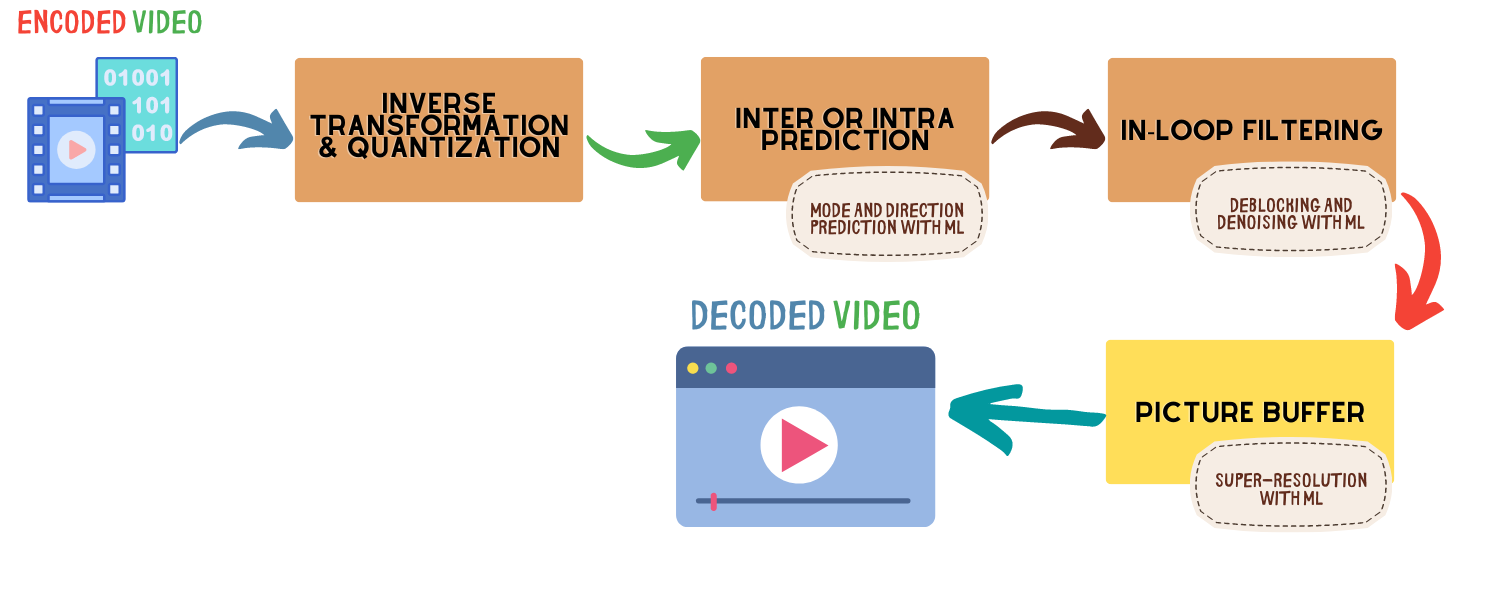
Encoding the source video to a compressed representation is the first part of the video encoding pipeline. The other part is getting that encoded video, reconstructing it (decoding), and displaying it to the user. We have already seen how machine learning-based approaches could improve encoding. Now, it is time to dive into what could be done in the decoding pipeline. Before we start, let’s look at the figure below to understand the overall decoding pipeline and see where and how we could utilize machine learning.

Video decoding is about reversing what is done during the encoding phase to reconstruct the source video to its original as close as possible. It starts with reverse transformation & quantization as those operations were the last step in the encoding phase. The same operations are reversed in this step to get the motion information required to reconstruct the video.
Once the information encoded during motion compensation (e.g., motion vectors, reference frames) is obtained via inverse transformation, the next step is reconstructing the frames using the motion information. In this step, frames are constructed using motion information from other frames (inter-coding) and/or within the frame (intra-coding). Although it sounds easy, it is actually a tricky process to determine whether to use intra or inter-mode prediction while constructing pixel information. Moreover, a further decision needs to be made about the angular direction of motion vectors to make sure pixels are appropriately constructed. This is where machine learning-based decisions could improve performance.
The video is almost ready to be displayed after the reconstruction step. However, since it is a reconstruction, it causes visual artifacts on the video, which could disturb the viewing experience. There is one extra step to apply before we pass the video to the picture buffer on the client, which is the in-loop filtering. Here, the goal is to eliminate visual artifacts as much as possible before sending the video to the display.

Denoising and deblocking are the two primary filters applied in this step. Denoising aims to remove the noise from the picture, while deblocking is about eliminating the blocking artifacts that occurred during reconstruction. Machine learning-based in-loop filters can significantly improve the visual quality in this step. Auspicious results were obtained in recent years, both in denoising and deblocking applications.
Now, after the in-loop filtering, our precious video is finally ready to be displayed. Decoded frames are sent to the picture buffer, and the playback can start. But, we have the magic hammer in our hands, so we are not going to stop improving the visual quality. We still have one more trick up our sleeves which is the super-resolution.
The goal of super-resolution is to increase input resolution with minimal distortion. Traditional approaches like bilinear or bicubic interpolation can provide high-resolution content but come with visually disturbing distortion artifacts. Since machine learning is there to improve traditional methods, super-resolution is also no exception. Machine learning-based super-resolution methods could significantly outperform traditional methods, which means we can use them for our decoded frames before displaying them to the client. Thus, getting better visual quality at the end.
This was all about how machine learning could be utilized to improve the video decoding pipeline. Now, we know how to use machine learning to improve each component in the entire video encoding pipeline. But what if we don’t rely on video codecs? Is it possible to find a solution to compress videos using machine learning? That would be the topic of our next post.
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.