Small Yet Powerful: Salesforce’s CodeGen2.5 Sets New Benchmark in Performance Despite Compact Size – A Look at the Rising Star in Language Models
The representation learning skills of large language models (LLMs) for program synthesis and understanding tasks are extraordinary. While putting upper boundaries on the model performance by the quantity of accessible data and computation, which is expensive, the neural scaling laws appear to dictate the quality of the learned representations as a function of the number of model parameters and observations.
The research team at Salesforce recently converted these discoveries from natural to programming languages, with outstanding results in program synthesis and understanding challenges. These models’ popularity originates from three characteristics:
- Easy to understand; using self-attention circuits, the involved architectures have low technical complexity.
- Ubiquitous, meaning that one model may perform several jobs when before n, separate models were needed, leading to significant savings in time and money.
- Larger models typically give predictably increased performance on downstream tasks, as performance is a function of the number of model parameters, data, and compute according to neural scaling laws, which take the shape of power laws.
These benefits, however, mask lingering issues:
- While the self-attention circuit itself is straightforward, learning either bidirectional (encoder) or unidirectional (decoder) representations requires selecting an attention-masking technique.
- The tasks of synthesis and comprehension have yet to be united, even though transformers look task-agnostic.
- While improving performance with increased scale is appealing, training even a modest number of models for various tasks is prohibitively expensive. In practice, it is not always clear what options are available for model design, learning algorithm, and data distribution. The computational demands of exploring these options result in significant financial outlay.
- Researchers attempt to unify model architecture, learning objective, left-to-right and infill sampling, and data distributions into a single recipe, which yields a single universal model with competitive performance on a wide range of synthesis and understanding tasks while keeping costs down and reducing the number of variants needed.
The aims of the study include:
- To pool knowledge and produce a standardized formula for training a globally applicable model.
- To make open-source code available as a method of training.
- To release into the public domain a set of highly refined models.
The following are their contributions to this streamlined set of findings:
- The four takeaways are condensing findings on prefix-LM as architecture, the free-lunch theory of infill sampling, selecting an appropriate goal function, and combining data in natural and programming languages.
- To produce a competitive performance for left-to-right and fill-in-the-middle auto-regressive sampling, researchers suggest a simple, unified blend of uncorrupted and within-file span-corruption sequences with next-token-prediction.
- The final recipe’s reference implementation for LLM training will be available as open-source software.
- Once training for bigger LLMs converges, the CodeGen2 family of infill-capable models will be open-sourced.
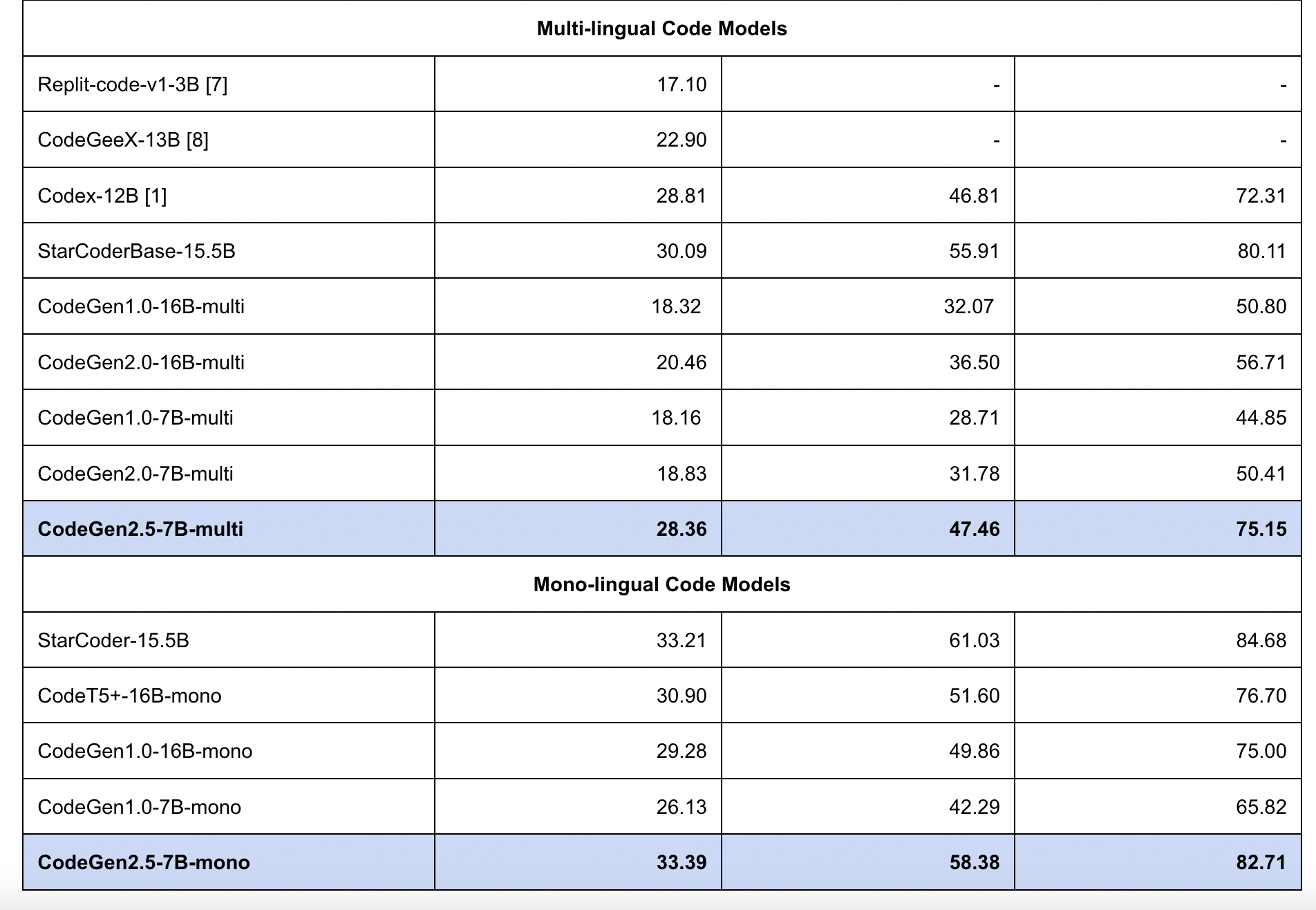
CodeGen2.5 is a new, tiny, yet powerful model in the Salesforce CodeGen family. Although there has been a recent trend toward ever-larger large language models (LLM), this study demonstrates that even a modestly sized model can achieve impressive results with proper training.
The most important contributions to bringing these models to market are:
- Incorporating the latest improvements to CodeGen’s LLM and releasing it with HumanEval’s 7B parameters.
- Less than half the size of the larger code-generation models (CodeGen1-16B, CodeGen2-16B, StarCoder-15B), CodeGen2.5 with 7B is competitive.
- The model has robust infill sampling, meaning it can “read” text the same size on the left and right as where it is currently displayed.
- Enhanced for rapid sampling with Flash’s special focus, it is ideally suited for remote use and local installation on individual computers.
- Permissive Apache 2.0 license.
CodeGen2.5 is an AR language model family used for code generation. The model, which expands upon CodeGen2 and is trained with StarCoderData for 1.4T tokens, outperforms StarCoderBase-15.5B despite being around half the size. This model, like CodeGen2, can infill and works with a wide variety of languages.
Researchers first hone their skills using Python, then hone them again with instruction data. All of the models are released in the following order:
- The CodeGen2.5-7B-multi repository: Educated with StarCoderData and released with an Apache 2.0 license.
- CodeGen2.5-7B-mono: Extra tokens of Python were used in the training process and released with an Apache 2.0 license.
- CodeGen2.5-7B-instruct: Enhanced instruction-based training based on CodeGen2.5-7B-mono. Only for academic reasons.
Learning Logic Machines is an expensive process with many design options. A unified approach to architecture, goals, sample methods, and data distributions was intended to overcome this obstacle. Scientists made predictions about these factors and then boiled down the good and bad results into four takeaways. The results of this investigation and the final training recipe may be useful for practitioners, even though they did not reach satisfactory unification. A simple mixture of causal language modeling and span-corruption limited to within-file spans is sufficient, and a mixture distribution of programming and natural languages appears promising, they conclude regarding the hypotheses. The Prefix-LM architecture has yet to yield any measurable improvements on the set of tasks.
Check out the Paper, Github link, and SF Blog. Don’t forget to join our 25k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.