Speechmatics Introduces Ursa: A Speech-To-Text System That Delivers Unprecedented Performance Across A Diverse Range of Voices
Using computational linguistics, speech recognition software such as “speech to text” can decipher human speech and convert it into text. Speech-to-text has rapidly expanded from personal phone use to business and medical settings. Applications that use speech recognition show how speech-to-text technology may improve the efficiency of routine chores and even take them beyond what people have historically been able to do.
Speechmatics introduces Ursa, the most precise speech-to-text system ever developed (as claimed by Speechmatics). Ursa is a technological breakthrough that bridges the digital divide by providing the most accurate speech-to-text conversion available. With Ursa’s superior accuracy and low total cost of ownership (TCO), the team could offer GPU-accelerated transcription on-premises for the first time.
The researchers started by training a self-supervised learning (SSL) model with 48 languages and over 1 million hours of unlabeled audio. They used an efficient transformer that learns high-quality acoustic representations of human speech. In the second step, they use the paired audio-transcript data to train an acoustic model that can convert self-supervised representations into phoneme probabilities. Next, a large language model is used to determine the most probable order of words to map the predicted phonemes into a transcript.
Their diarization models use the same generic self-supervised representations to add speakers’ names and other metadata to the transcripts. In addition, they use inverse text normalization (ITN) models to convert the numerical entities in the transcriptions into a standardized and polished textual form.
Although multiple audio streams may be processed simultaneously, GPUs are ideal due to their highly parallel architecture that allows for high throughput inference. As a result of employing GPUs for inference, the team could scale the SSL model to 2 billion parameters and the language model by a factor of 30 to achieve the ground-breaking speed with Ursa. Scaling to 2 billion parameters enables the models to learn more nuanced acoustic properties from unlabeled multi-lingual data, expanding the ability to comprehend a wider variety of voice groups.
These representations not only improve accuracy when training an auditory model but also drastically increase the sample efficiency of the training process. This allows for shortening the training period of the state-of-the-art English models from weeks to days. Most importantly, Ursa’s shown accuracy improvement does not necessitate hundreds of thousands of hours of labeled audio. As a result, it’s possible to achieve accuracy on par with Whisper using only a few thousand hours of recorded sound (200x less).
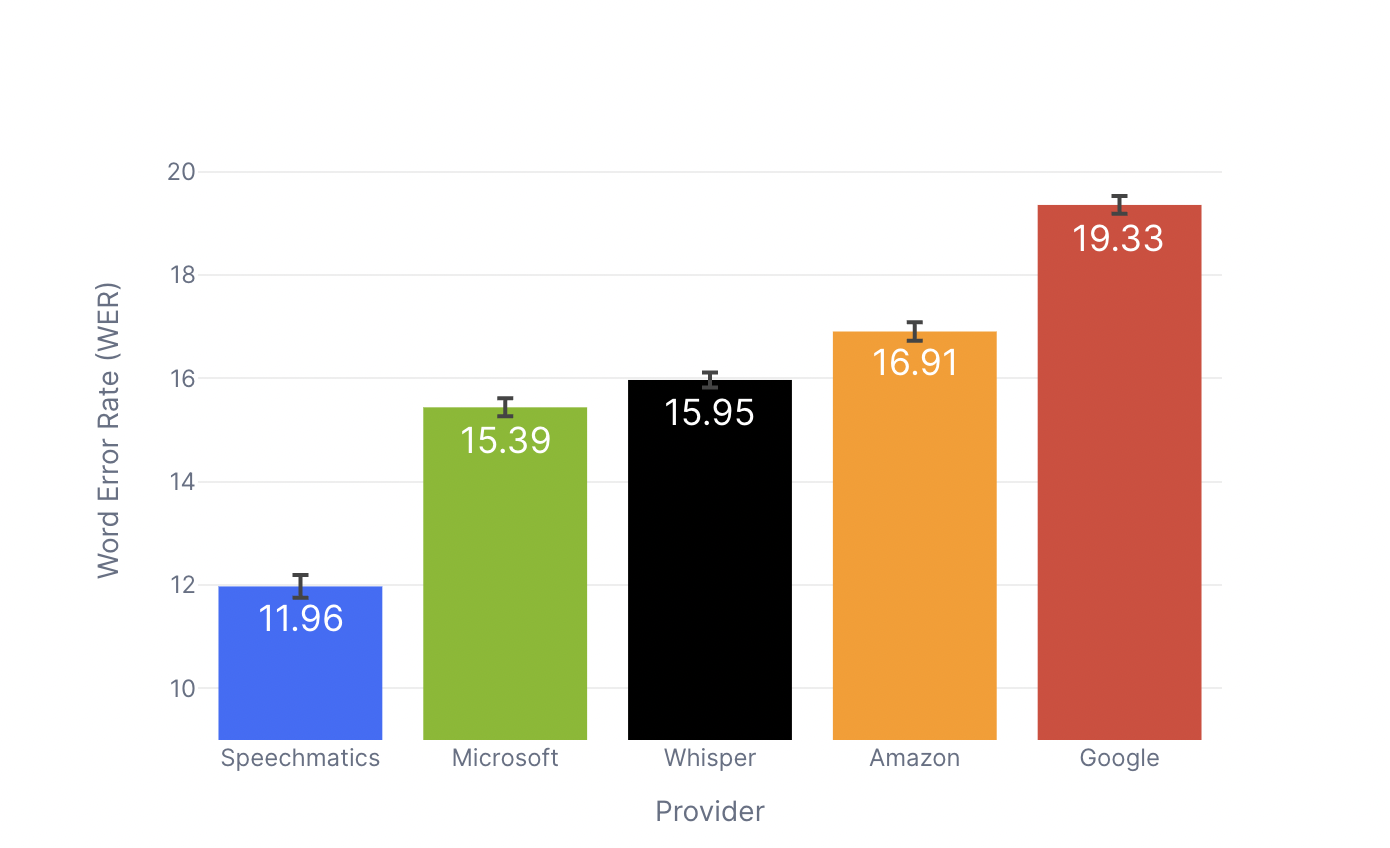
Ursa’s unparalleled precision is what sets it different from competing speech-to-text solutions. In addition to surpassing human-level transcription accuracy on the Kincaid46 dataset, Ursa’s improved model also reduces transcription errors by an average of one-fifth compared to Microsoft, the next-largest cloud provider. Compared to other suppliers, Ursa’s standard and enhanced English models perform significantly better, increasing by 35% and 22% relative accuracy, respectively.
In the future, the team plan to conduct a more in-depth investigation of accuracy across different demographics, the importance of speech-to-text accuracy for downstream tasks, a more thorough breakdown of translation accuracy, and the robustness of Ursa in noisy environments.
Check out the Source Article. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 16k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.