Stanford and Cornell Researchers Introduce Tart: An Innovative Plug-and-Play Transformer Module Enhancing AI Reasoning Capabilities in a Task-Agnostic Manner
Without changing the model parameters, large language models have in-context learning skills that allow them to complete a job given only a small number of instances. One model may be used for various tasks because of its task-agnostic nature. In contrast, conventional techniques for task adaptation, including fine-tuning, modify the model parameters for each task. Even though task-independent, in-context learning is rarely the practitioner’s method of choice because it routinely performs worse than task-specific adaption techniques. Most previous studies blame this performance disparity on the LLMs’ constrained context window, which can only accommodate a small number of task cases.
However, they demonstrate that the gap between in-context learning and fine-tuning techniques remains even when given identical task examples. This discovery begs whether the performance difference is a general constraint of task-agnostic strategies for adaptation or if it is unique to in-context learning. Can they specifically create adaption strategies that meet the requirements listed below:
• Task-agnostic: The same model applies universally to various activities.
• Quality: Across these several tasks, achieves accuracy competitive with task-specific approaches.
• Data-scalable: Learning efficiency increases as the number of task instances increases. They start by looking at the causes of the quality discrepancy.
They divide an LLM’s capacity for in-context learning into two components: the acquisition of effective task representations and the execution of probabilistic inference, or reasoning, over these representations. Is the gap caused by a lack of information in the representations or by the LLMs’ inability to analyze them? By evaluating the reasoning and representational gaps across a range of LLM families throughout several binary classification tasks, they test this notion empirically. They conclude that LLMs have strong representations and that the majority of the quality disparity is caused by weak reasoning on their part.
They also discover that fine-tuning enhances the basic model on both axes but predominantly enhances task-specific reasoning, responsible for 72% of the performance improvement. Surprisingly, most methods for narrowing the performance gap, such as prompt engineering and active example selection, only target the LLM’s learned representations. In contrast, their research examines an alternative strategy for enhancing LLM reasoning skills. They refine LLMs using artificially created probabilistic inference challenges as a first step to improving their reasoning skills. While this method enhances the model’s baseline in-context learning performance, it also necessitates individually fine-tuning each LLM.
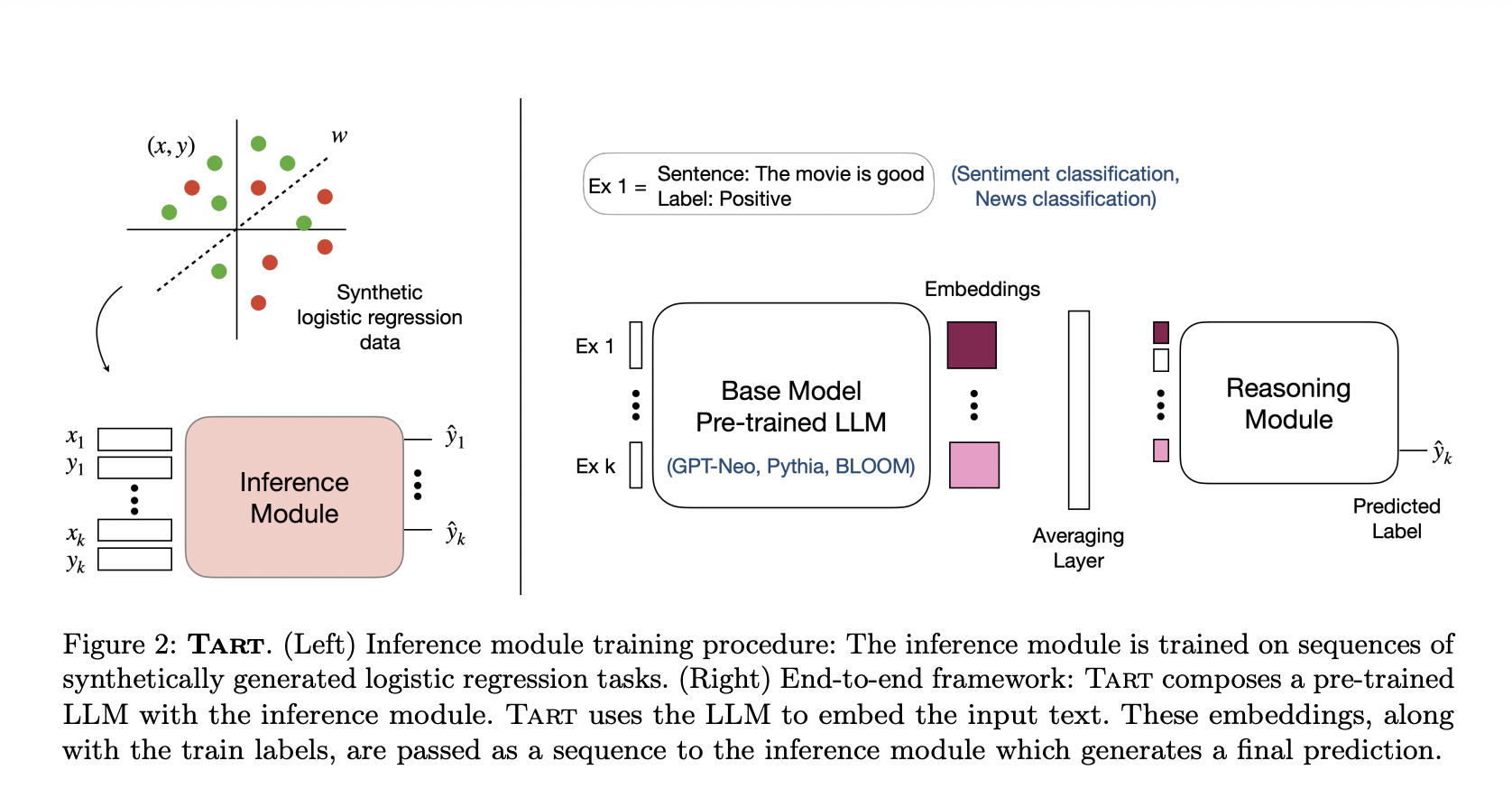
They go a step further and speculate on the prospect of developing reasoning skills in a way that is independent of tasks and models. They demonstrate that an entirely agnostic approach may be taken to enhance reasoning skills. Researchers from Standford University and Cornell University in this study suggest Tart, which uses a synthetically taught reasoning module to improve an LLM’s reasoning capabilities. Only synthetically produced logistic regression problems, regardless of the downstream task or the base LLM, are used by Tart to train a Transformer-based reasoning module. Without further training, this inference module may be constructed using an LLM’s embeddings to enhance its deductive capabilities.
In particular, Tart achieves the necessary goals:
• Task-neutral: Tart’s inference module must be trained once with fictitious data.
• Quality: Performs better than basic LLM across the board and closes the gap using task-specific fine-tuning techniques.
• Data-scalable: Handling 10 times as many instances as in-context learning.
Tart is independent of task, model, and domain. They demonstrate that Tart generalizes across three model families over 14 NLP classification tasks and even across distinct domains, using a single inference module trained on synthetic data. They demonstrate that Tart’s performance is superior in terms of quality to in-context learning by 18.4%, task-specific adapters by 3.4%, and complete task-specific fine-tuning by 3.1% across various NLP tasks.
On the RAFT Benchmark, Tart raises GPT-Neo’s performance to the point where it equals GPT-3 and Bloom while outperforming the latter by 4%. Tart solves the inconveniently short context duration barrier of in-context learning and is data-scalable. In an LLM, each example can take up several tokens, often hundreds, whereas Tart’s reasoning module only uses two tokens per case—one for the context and one for the label. The benefits that can result from this data scalability can reach 6.8%. Theoretically, they demonstrate that Tart’s generalization skills mostly depend on the distribution shift between the synthetic data distribution and the natural text embedding distribution, as evaluated by the Wasserstein-1 metric.
The following is a summary of their principal contributions:
• Using a representation-reasoning decomposition, investigate why task-specific fine-tuning outperforms in-context learning while having access to the same information.
• Present Tart, a novel task-agnostic approach that outperforms task-specific approaches and requires no real data for training.
• Prove that Tart is effective for various model families across NLP tasks. The same inference module also applies to voice and visual domains.
Check Out The Paper and Github link. Don’t forget to join our 24k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.