Stanford and Google Researchers Propose DoReMi: An AI Algorithm Reweighting Data Domains for Training Language Models
Datasets are often drawn from various domains while training language models (LMs). For instance, a sizable publicly accessible dataset called The Pile has 24% online data, 9% Wikipedia, 4% GitHub, etc. The makeup of the pretraining data significantly impacts how well an LM performs. It needs to be apparent how much of each domain should be included to create a model that excels at a range of downstream tasks. Existing studies use intuition or a series of downstream tasks to establish domain weights or sample probabilities for each domain. For instance, The Pile employs heuristically selected domain weights, which may not be the best choice.
In this study, researchers from Google and Stanford University try to identify domain weights that provide models that perform well on all domains by minimizing the worst-case loss over domains rather than optimizing domain weights based on a collection of downstream tasks. Given that each domain has a unique optimum loss (also known as the entropy), a naive worst-case strategy would give more weight to the domains with the noisiest data. However, training possibly thousands of LMs on various domain weights and the possibility of overfitting to a specific set of downstream tasks are involved with existing LMs like PaLM and GLaM, which adjust the domain weights based on a set of downstream activities.

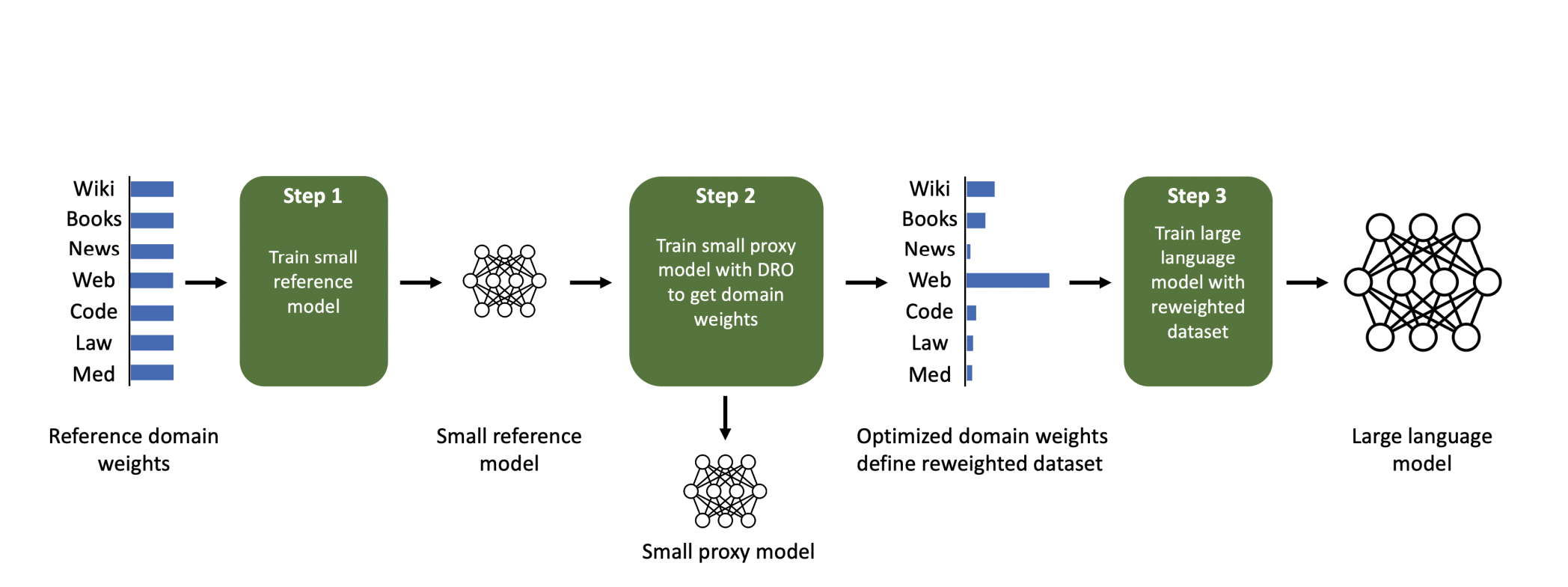
This serves as the driving force behind their technique, Domain Reweighting with Minimax Optimisation (DoReMi), which uses distributionally robust optimization (DRO) to adjust the domain weights without being aware of the tasks that will be performed later (Figure 1). DoReMi begins by conventionally training a tiny reference model with 280M parameters. To reduce the worst-case excess loss (compared to the loss of the reference model), they also introduce a tiny distributionally resistant language model (DRO-LM). Notably, they use the domain weights generated by DRO training rather than the robust LM. Instead of creating a robust model, their strategy uses the DRO-LM framework to optimize domain weights. A big (8B) LM is then trained on a new dataset specified by these domain weights.
Instead of sub-selecting instances from a minibatch, they use the online learning-based optimizer from Group DRO, which dynamically changes domain weights according to the loss on each domain for rescaling the training goal. DoReMi then uses the domain weights averaged throughout the DRO training stages. To optimize domain weights on The Pile and the GLaM dataset, they run DoReMi on 280M proxy and reference models. An 8B parameter LM that is more than 30 times bigger is trained using the DoReMi domain weights. Even when a domain is down-weighted, DoReMi lowers perplexity on The Pile across all domains relative to baseline domain weights.
On productive few-shot tasks, DoReMi reaches the downstream baseline accuracy 2.6x faster than a baseline model trained on The Pile’s default domain weights, improving average downstream accuracy by 6.5%. They release the tuned domain weights to enhance future LMs learned using The Pile. They discover that DoReMi consistently enhances LM training when the sizes of the main model trained with optimized domain weights and the proxy model are changed. DoReMi even outperforms domain weight tuning on downstream task performance on the GLaM dataset, where it is possible to get domain weights tuned on downstream tasks.
Check Out The Paper. Don’t forget to join our 22k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.