Stanford and Meta Researchers Release ‘ConcurrentQA’ Public Data Set With Data From Multiple Privacy Scopes And a Privacy Methodology
People increasingly rely on AI systems like assistants and chatbots to assist them with various tasks, from answering weather questions to organizing a meeting at work. Users must supply relevant information to systems, such as their location or work calendar, to complete these duties. However, in some circumstances, users wish to keep their information private. Today’s reasoning systems aren’t designed to do so.
Meta AI is providing ConcurrentQA, the first public data set for investigating information retrieval and question answering (QA) with data from various privacy scopes, to alleviate this constraint and promote research in this and related fields. Along with the data set and problem research, Meta AI established a new methodology dubbed Public-Private Autoregressive Information Retrieval as a starting point for thinking about privacy in retrieval-based contexts (PAIR).
ConcurrentQA includes questions like “With a given GPA and SAT score, which universities should one apply in the United States?” that may require both public and private information to answer. PAIR is a guide for creating systems that can answer these questions without the need to inform a QA system of one’s grades or SAT scores — it gives a framework for reasoning about how to construct systems that retrieve data from both public and private sources without jeopardizing the integrity of the personal data.

Working
QA and reasoning over data with various privacy scopes in natural language processing are primarily unexplored. This is partly due to a smaller amount of publicly available datasets and benchmarks for analyzing and comparing approaches. There are around 18,000 question-answer pairings in ConcurrentQA. Each pair contains a corresponding pair of sentences, either from Wikipedia or the widely used Enron Email Dataset. Each paragraph contains material that must be grasped in a logical order to answer the question posed — these stages are referred to as reasoning hops.
For example, an AI system must make one hop to retrieve the asker’s GPA and SAT score and another hop to retrieve information about admissions policies at universities in the United States to answer the query above regarding which universities to apply. When the information to be retrieved can be located in a single privacy scope, such as a public domain knowledge base (e.g., Wikipedia), this type of multi-hop reasoning has been thoroughly investigated, but not when some of that information is private, such as a person’s grades and test scores.
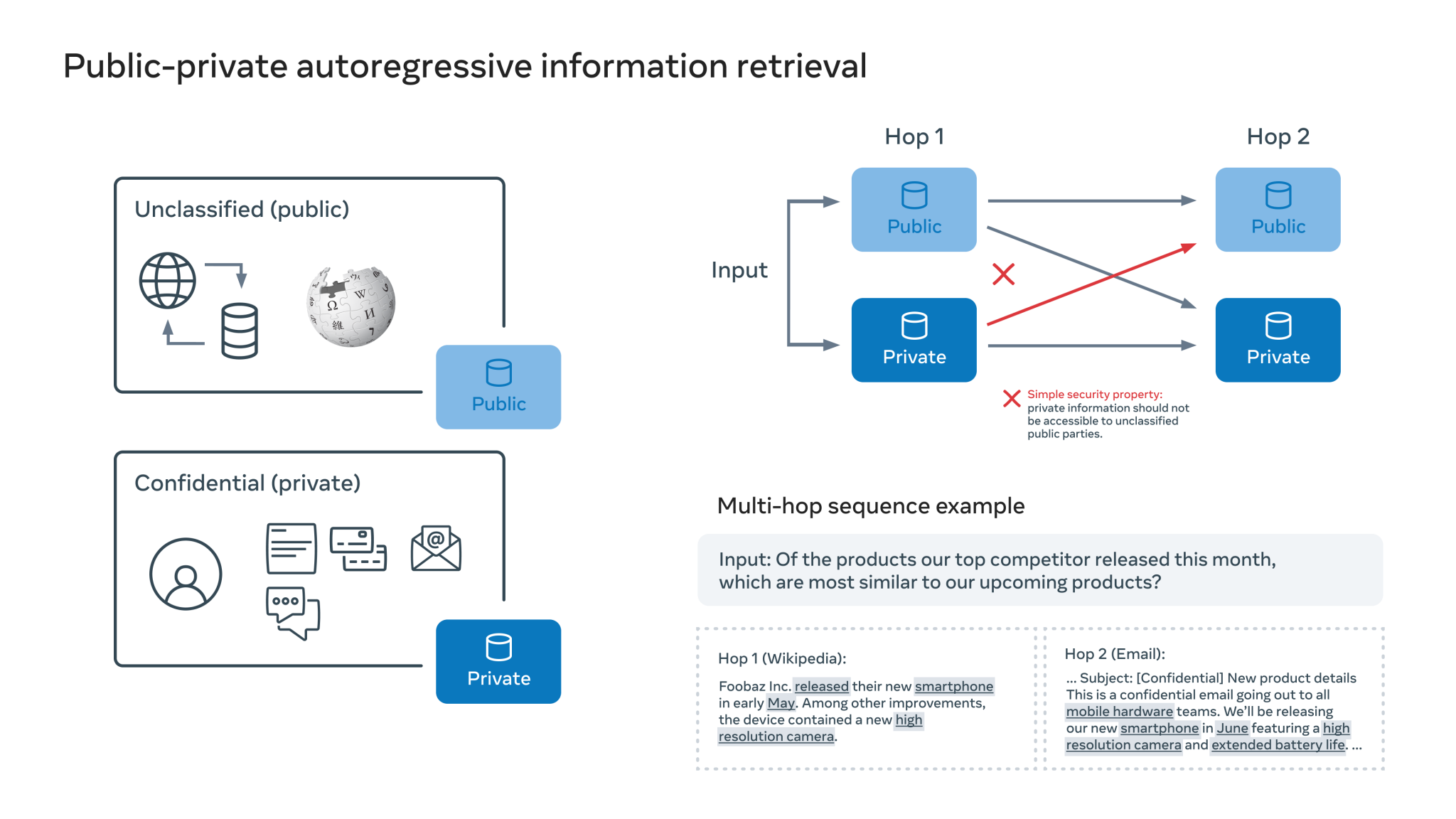
PAIR framework can be used to describe the design space for various multi-hop QA models as a starting point for researching privacy-aware reasoning with ConcurrentQA. PAIR-based AI systems should have the following characteristics:
- Data is held in at least two enclaves in a theoretical system. In that approach, public and private information are stored separately, allowing private actors or retrievers access to public data but not to personal data.
- Public data retrievals should be prioritized above private data retrievals in systems. Data retrieved from private knowledge bases should not leak into public systems retrieving from public knowledge bases, which may be communal, according to systems designed with PAIR.
PAIR is a starting point for researchers to create systems that can reason over both public and private data while maintaining appropriate privacy restrictions.
Conclusion
People’s daily lives are becoming increasingly entwined with technology, a tendency that will only continue as we develop for the metaverse. It’s critical for AI systems to be able to do helpful activities for people while simultaneously protecting their personal information. Meta AI’s approach to responsible AI emphasizes privacy and security. Tools like CrypTen have been produced and shared, which makes it easier for AI researchers to experiment with secure computing strategies, and Opacus, a library for training models with differential privacy, as part of this work.
The AI community is only getting started on developing effective techniques to execute question-answering jobs while maintaining privacy. The publication of ConcurrentQA and PAIR as a starting point attempts to speed up this research; however, colleagues outside of Meta still have a lot of work to perform. There is the expectation that new data sets like ConcurrentQA will aid AI researchers and practitioners develop solutions that will enable people’s privacy to be better protected. It will be more challenging for the industry to develop AI systems that can extract the information while simultaneously protecting people’s privacy until more study is done in this area.
Using more representative data sets and finding other techniques to eliminate bias can improve ConcurrentQA and PAIR. There is also an emphasis on the steps taken by the government and academic specialists to remove personally identifiable information from the Enron Email Dataset and address privacy concerns. This was done before the data set was released in its current state for AI researchers to use.
Paper: https://dl.fbaipublicfiles.com/concurrentqa/reasoning_over_public_and_private_data_in_retrieval_based_systems.pdf
Github: https://github.com/facebookresearch/concurrentqa
Reference: https://ai.facebook.com/blog/building-systems-to-reason-securely-over-private-data
Suggested
Credit: Source link
Comments are closed.