Stanford and Mila Researchers Propose Hyena: An Attention-Free Drop-in Replacement to the Core Building Block of Many Large-Scale Language Models
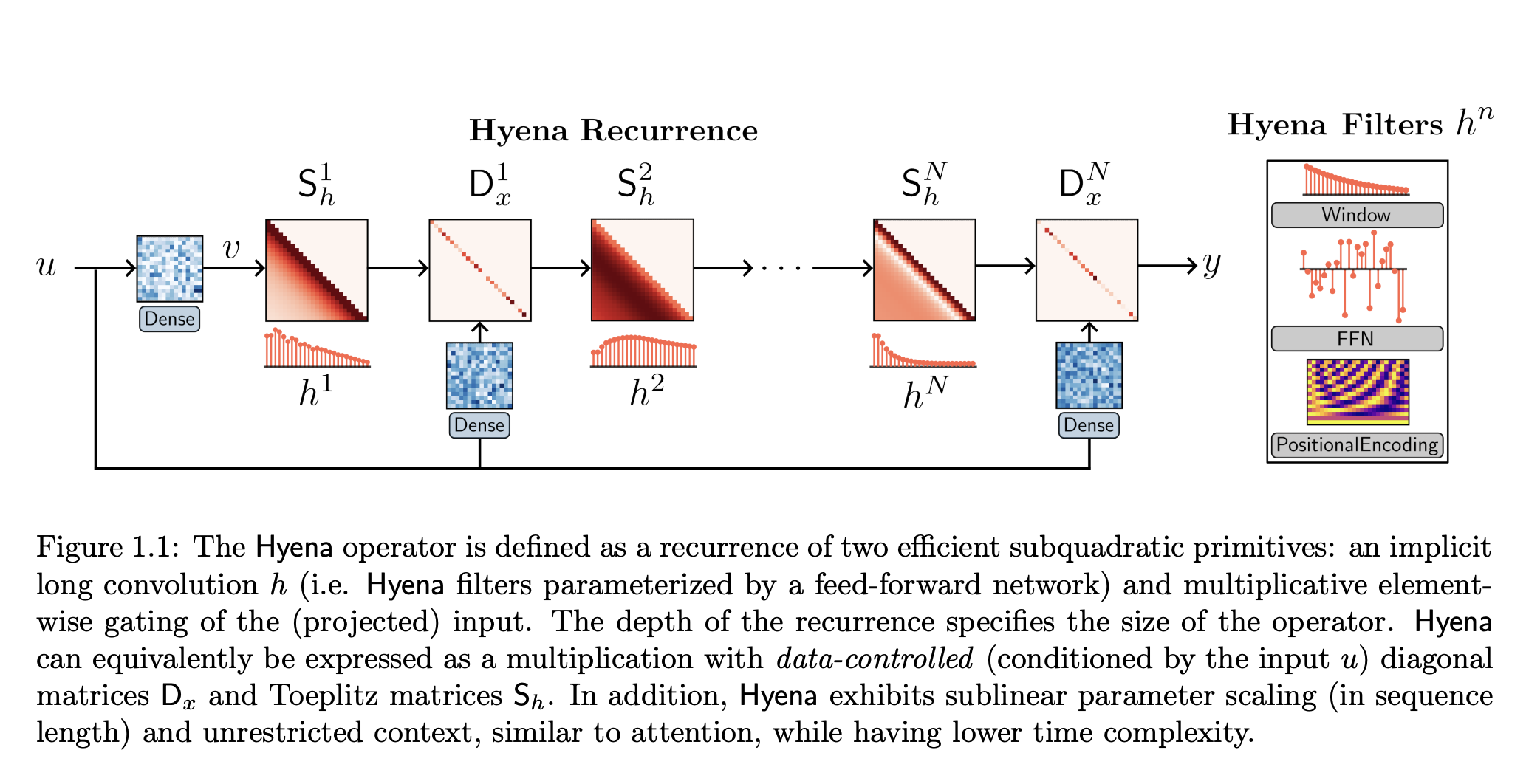
As we all know that the race to develop and come up with mindblowing Generative models such as ChatGPT and Bard, and their underlying technology such as GPT3 and GPT4, has taken the AI world by magnanimous force, there are still many challenges when it comes to the accessibility, training and actual feasibility of these models in lots of use cases which pertains to our day to day problems.
If anyone has ever played around with any of such sequence models, there is one sure-shot problem that might have ruined their excitement. That is, the length of input they can send in to prompt the model.
If they are enthusiasts who want to dabble in the core of such technologies and train their custom model, the whole optimization process makes it quite an impossible task.
At the heart of these problems lies the quadratic nature of the optimization of attention models that sequence models utilize. One of the biggest reasons is the computation cost of such algorithms and the resources needed to solve this issue. It can be an extremely expensive solution, especially if someone wants to scale it up, which leads to only a few concentrated organizations having a vivid sense of understanding and real control of such algorithms.
Simply put, attention exhibits quadratic cost in sequence length. Limiting the amount of context accessible and scaling it is a costly affair.
However, worry not; there is new architecture called the Hyena, which is now making waves in the NLP community, and people ordain it as the rescuer we all need. It challenges the dominance of the existing attention mechanisms, and the research paper demonstrates its potential to topple the existing system.
Developed by a team of researchers at a leading university, Hyena boasts an impressive performance on a range of subquadratic NLP tasks in terms of optimization. In this article, we will look closely at Hyena’s claims.

This paper suggests that subquadratic operators can match the quality of attention models at scale without being that costly in terms of parameters and optimization cost. Based on targeted reasoning tasks, the authors distill the three most important properties contributing to its performance.
- Data control
- Sublinear parameter scaling
- Unrestricted context.
Aiming with these points in mind, they then introduce the Hyena hierarchy. This new operator combines long convolutions and element-wise multiplicative gating to match the quality of attention at scale while reducing the computational cost.
The experiments conducted reveal mindblowing results.
- Language modeling.
Hyena’s scaling was tested on autoregressive language modeling, which, when evaluated on perplexity on benchmark dataset WikiText103 and The Pile, revealed that Hyena is the first attention-free, convolution architecture to match GPT quality with a 20% reduction in total FLOPS.
Perplexity on WikiText103 (same tokenizer). ∗ are results from (Dao et al., 2022c). Deeper and thinner models (Hyena-slim) achieve lower perplexity
Perplexity on The Pile for models trained until a total number of tokens e.g., 5 billion (different runs for each token total). All models use the same tokenizer (GPT2). FLOP count is for the 15 billion token run
- Large Scale image classification
The paper demonstrates the potential of Hyena as a general deep-learning operator for image classification. On image translation, they drop-in replace attention layers in the Vision Transformer(ViT) with the Hyena operator and match the performance with ViT.
On CIFAR-2D, we test a 2D version of Hyena long convolution filters in a standard convolutional architecture, which improves on the 2D long convolutional model S4ND (Nguyen et al., 2022) in accuracy with an 8% speedup and 25% fewer parameters.

The promising results at the sub-billion parameter scale suggest that attention may not be all we need and that simpler subquadratic designs such as Hyena, informed by simple guiding principles and evaluation on mechanistic interpretability benchmarks, form the basis for efficient large models.
With the waves this architecture is creating in the community, it will be interesting to see if the Hyena would have the last laugh.
Check out the Paper and Github link. Don’t forget to join our 20k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club

Data Scientist currently working for S&P Global Market intelligence. Worked as data scientist for AI product startups. Reader and a learner at heart.
Credit: Source link
Comments are closed.