Stanford And Oxford Researchers Propose An Approach To Relate Transformers To Models And Neural Representations Of The Hippocampal Formation
This Article Is Based On The Research Paper 'RELATING TRANSFORMERS TO MODELS AND NEURAL REPRESENTATIONS OF THE HIPPOCAMPAL FORMATION'. All Credit For This Research Goes To The Researchers of This Project 👏👏👏 Please Don't Forget To Join Our ML Subreddit
In recent years, a significant part of neuroscience research has focused on relating deep learning architectures to the human brain, and many deep learning (DL) techniques have recently been shown to replicate neural firing patterns observed in the brain. For example, representations of convolutional neural networks have been shown to predict neurons in the visual cortex and inferior temporal cortex, while recurrent neural networks have been shown to recapitulate grid cells in the medial entorhinal cortex. The ability to use machine learning models to predict brain representations allows for a deeper understanding of the mechanistic computations of the respective brain areas and a deeper understanding of the nature of the models. However, one of the most exciting and promising new architectures, the Transformer neural network, was developed without thinking about the brain, and a correlation between it and neural structure has not yet been demonstrated.
A team composed of researchers from Oxford and Stanford Universities has filled this gap. In their work, they showed that a slightly modified transformer recapitulated spatial representations found in the brain and demonstrated the mathematical relationship of this transformer to current neuroscience models of the hippocampus. In addition, they develop new theories for both neuroscience and machine learning on the computational role of the hippocampus and the role of positional encodings in transformers, respectively.
The transformer architecture, born originally for NLP, receives a set of tokens and can predict the next element of the sequence or a missing element. Their superpowers derive mainly from self-attention, a technique that leverages three matrixes, query (Q), key (K), and values (V). These matrixes are used to compute the similarity between all the elements in the sequence. Very briefly, if we are considering a token, Q is the matrix used to compare it with the K matrixes of all the other tokens, and V contains the actual values. Self-attention does not know the order of the input, so it is usually used with additional positional encoding.
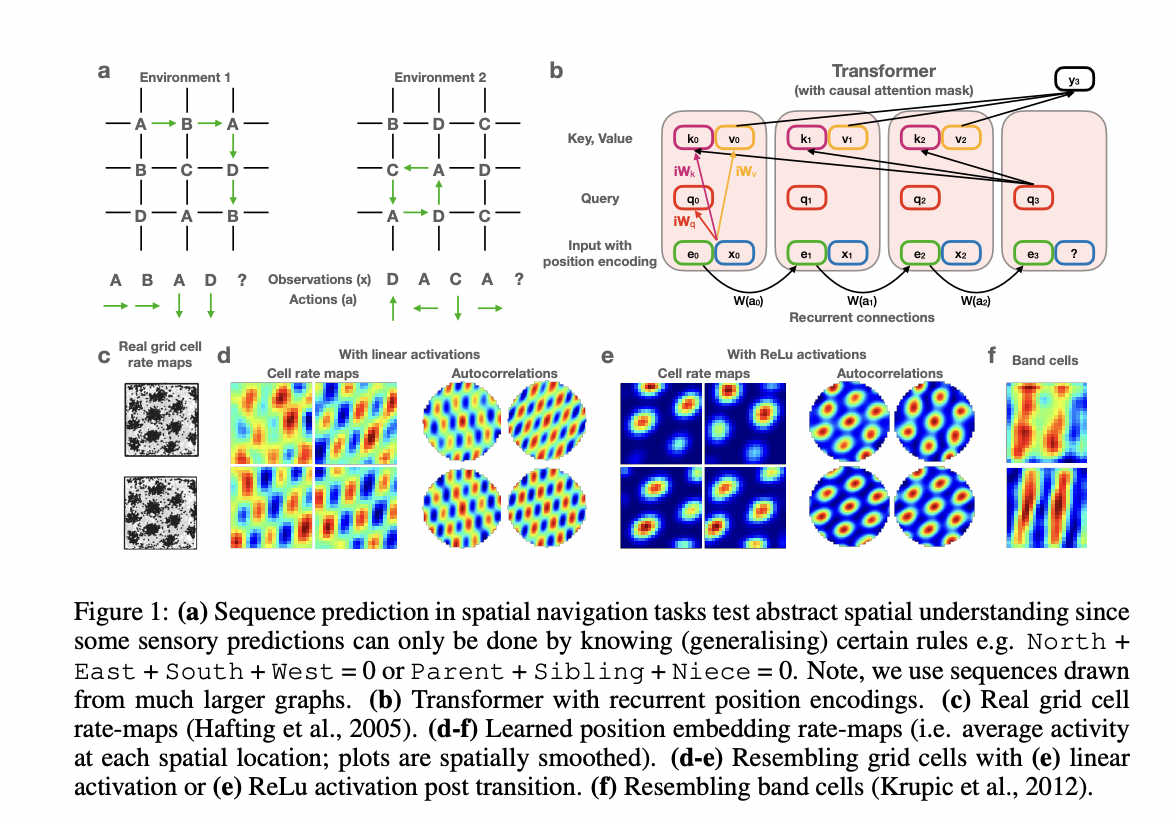
The authors introduced three modifications to the original architecture. Firstly, they defined matrixes such as Q and K are the same and focus solely on position encoding, while V focuses on the inputs. Secondly, they use a casual transformer that can just rely on past tokens to predict the next ones. Thirdly, they equipped the architecture with recurrent positional encoding. Thus, positional encoding might be optimized, and it’s not defined a priori.
With this structure, the transformer was able to learn spatial representations. Specifically, the task was to predict the next sensory observation while “moving” in a virtual environment. For example, after seeing (x1 = cat, a1 = North), which means seeing a cat and then moving to north, then (x2 = dog, a2 = East), (x3 = frog, a3 = South), (x4 = pig, a4 = West), the aim is to predict x5 = cat, because we returned at the starting point. To be successful in prediction, it is not enough to remember specific sequences of stimulus-action pairs, but it is necessary to know the rules of space, e.g., North + East + South + West = 0. The authors train the network with several different spatial environments that share the same Euclidean structure (figure below), to generalize its functioning to any 2D space.

After demonstrating that the transformer could master spatial representation, the authors pointed out how this was not surprising at all. In fact, they showed that the modified transformer is closely related to the current neuroscience model of the hippocampus and surrounding cortex, namely, the TEM (Tolman-Eichenbaum Machine) model.
Very briefly, TEM is a sequence learning model that captures neural phenomena in the hippocampus. It consists of two modules: the first one learns where it is in space using a location representation. This module was demonstrated to behave similarly to the learnable positional encoding in the modified transformer. The second module links location to specific sensory observation. The linking is made between each location and sensory observation, so it resembles self-attention in a transformer. The authors proposed an in-depth mathematical demonstration of these two intuitions and defined the TEM-transformer (TEM-t), modifying the original TEM structure according to the characteristics of the transformer architecture.
TEM-t achieved significant performance improvements over the original model. In the figure below, it can be seen that the training time decreased while the accuracy increased.

In conclusion, the implication of this paper is two-fold: in neuroscience, it may offer a new way to explore the hippocampus. This is because TEM considers conjunctions between only two cortical regions. Indeed, if more than two variables were considered, a better understanding would be gained. Unfortunately, however, with a classical TEM model, the computational effort required to consider more than two conjunctions would be unfeasible. In contrast, TEM-t scales better and could be used to study this topic.
In addition, in machine learning, the paper gives a broad study on the importance of positional encoding in transformers, and it could be the first step for researchers to understand it better.
Paper: https://arxiv.org/pdf/2112.04035.pdf
Credit: Source link
Comments are closed.